
论文阅读:Enhancing Retrieval and Managing Retrieval: A Four-Module Synergy for Improved Quality and Efficiency in RAG Systems
检索增强生成(RAG)技术利用大型语言模型(LLM)的上下文学习能力,生成更准确、更相关的响应。RAG 框架起源于简单的 “检索-阅读 ”方法,现已发展成为高度灵活的模块化范式。其中一个关键组件——查询重写模块,通过生成搜索友好的查询来增强知识检索。这种方法能使输入问题与知识库更紧密地结合起来。作者的研究发现了将 Query Rewriter 模块增强为 Query Rewriter+ 的机会,即通过生成多个查询来克服与单个查询相关的信息高原,以及通过重写问题来消除歧义,从而明确基本意图。作者还发现,当前的 RAG 系统在无关知识方面存在问题;为了克服这一问题,提出了知识过滤器。这两个模块都基于经过指令调整的 Gemma-2B 模型,共同提高了响应质量。最后一个确定的问题是冗余检索,作者引入了记忆知识库和检索触发器来解决这个问题。前者支持以无参数方式动态扩展 RAG 系统的知识库,后者优化了访问外部知识的成本,从而提高了资源利用率和响应效率。这四个 RAG 模块协同提高了 RAG 系统的响应质量和效率。这些模块的有效性已通过六个常见 QA 数据集的实验和消融研究得到验证。
方法介绍
...

论文阅读:DQ-LoRe:Dual Queries with Low Rank Approximation Re-ranking for In-Context Learning
大型语言模型(LLMs)展示了其基于上下文学习的卓越能力,在错综复杂的推理任务中,利用思维链(CoT)范式中的中间推理步骤来引导大型语言模型的一个很有前景的途径。然而,核心挑战在于如何有效选择范例来促进上下文学习。
先前的很多工作都是围绕添加思维链,例如一致性 CoT、思维树以及思维图,往 context 中添加更多的推理步骤,或者将推理过程拆解为多个子步骤,依次优化每个子步骤。这些操作都会让 context 越来越长,或者在推理过程中增加更多的链路,从而导致推理的时延和成本增加。这篇论文的一个核心或者说有价值的工作是考虑了时间成本,具体做法请阅读下文关于论文方法的介绍。
在本研究中,作者介绍了一种利用双查询和低秩近似重新排序(DQ-LoRe)的框架,以自动选择用于上下文学习的范例。双查询首先查询 LLM 以获得 LLM 生成的知识(如 CoT);然后查询检索器,通过问题和知识获得最终范例。此外,对于第二次查询,LoRe 采用了降维技术来完善范例选择,确保与输入问题的知识密切吻合。
通过大量实验,作者证明了 DQ-LoRe 在 GPT-4 示例自动选择方面的性能明显优于之前的先进方 ...

论文阅读:Speculative RAG: Enhancing Retrieval Augmented Generation through Drafting
论文地址:https://arxiv.org/abs/2407.08223
RAG 将 LLM 的生成能力与外部知识源相结合,以提供更准确和最新的响应。最近的 RAG 进展侧重于通过迭代 LLM 完善或通过 LLM 的额外指令调整获得自我批判能力来改进检索结果。在这项工作中,作者介绍了 SPECULATIVE RAG,一种利用较大、通用 LLM 高效验证由较小、经过提炼的专业 LLM 并行生成的多个 RAG 草案的框架。每个草稿都是从检索到的文件中的一个不同子集生成的,从而为证据提供了不同的视角,同时减少了每个草稿的输入 tokens。这种方法增强了对每个子集的理解,并减轻了 long context 中潜在的立场偏差。该方法将起草工作委托给较小的专家 LM,由较大的通用 LM 对草稿进行一次验证,从而加快了 RAG 的速度。
广泛的实验证明,SPECULATIVE RAG 在 TriviaQA、MuSiQue、PubHealth 和 ARC-Challenge 基准测试中实现了最先进的性能,同时降低了延迟。与 PubHealth 上的传统 RAG 系统相比,它显著提高了 12.97% ...

论文阅读:Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs
论文地址:https://arxiv.org/abs/2406.10209
大型语言模型会记忆和重复训练数据,从而造成隐私和版权风险。为了减少记忆,作者对 NSP 训练目标进行了微妙的修改,称之为 goldfish loss。在训练过程中,随机抽样的 token 子集将不参与 loss 计算。这些被剔除(dropout)的 token 不会被模型记忆,从而防止逐字复制训练集中的完整 token 链。
在多轮对话的数据清洗过程中,如果未能将一些重复的话语(后处理保底或预设的回复)以及一些人名进行清洗,即使数据量很少,模型很容易学到这一完整的回复。当时老板推荐了一篇论文(暂时找不到了,里面提到对注意力进行 random mask,来避免过拟合),我当时没有修改 attention mask,转而去对参与计算 loss 的 label 进行随机采样。之所以这么做,是因为当时使用 lmsys 推出的 fastchat 框架,在多轮对话中只训练模型回复的内容。因此,基于参与计算 loss 的 label 进行处理似乎更加有效。没想到这个做法现在已经有团队发了论文,并且做了大量的实验来验证 Go ...
AI-情感聊天机器人之旅——相关论文收集
开放域闲聊场景Prompted LLMs as Chatbot Modules for Long Open-domain Conversation
发布日期:2023-05-01
简要介绍:作者提出了 MPC(模块化提示聊天机器人),这是一种无需微调即可创建高质量对话代理的新方法,可以成为长期开放域聊天机器人的有效解决方案。该方法利用预训练好的大型语言模型(LLM)作为单独的模块,通过使用 few-shot、思维链(CoT)和外部记忆等技术来实现长期一致性和灵活性。
MPC 本质上是一种 RAG 或者说 Agent,在输入和输出的中间添加了更多思考和记忆的环节,将 LLM 从“人”的角色进一步拆分为“大脑”和“嘴巴”。这种明确的分工的确能够提升最终的效果,但同样会遇到 RAG、Agent 成本较高的问题,以及引入更多中间环节造成的误差累积。为什么成本较高?为了确保中间环节结果的正确性,往往也会接一个 LLM 去做判断,或者训练专门的小模型,这些都需要资源,并且对整个推理过程的时延造成一定的影响。在业务上是否真得要这么做,还需要进一步衡量效果和成本的 tradeoff。
...
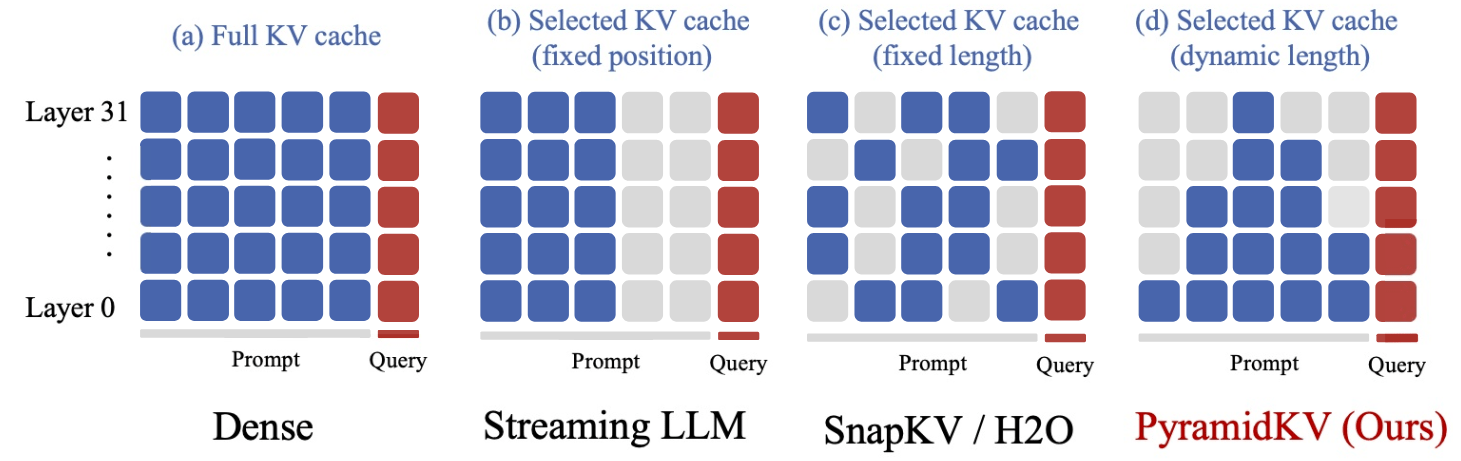
PyramidKV
论文地址:https://arxiv.org/abs/2406.02069
GitHub 仓库:https://github.com/Zefan-Cai/PyramidKV
北大、威斯康辛-麦迪逊、微软等联合团队提出了全新的缓存分配方案,只用 2.5% 的 kv cache 就能保持大模型 90% 的性能。该方法名为 PyramidKV,在 kv cache 压缩的过程中融入了金字塔型的信息汇聚方式。在内存受限的情况下,PyramidKV 表现非常出色,既保留了长上下文理解能力,又显著减少了内存使用。
传统对 kv cache 压缩的方法有一个共同特点,对每个 Transformer 层的 kv cache“一视同仁”地用相同的压缩设置,压缩到同样的长度。
PyramidKV 团队发现,对 KV cache 进行极致压缩情况下(从 32k 长度压缩到 64,即保留 0.2%的 kv cache)上述方法的表现会面临严重的性能下降。于是作者提出疑问:对每个 Transformer 层将 kv cache 压缩到同样大小是否为最优方案?
研究团队对大模型进行 RAG 的机制进行深入分 ...
vocab size 调研
在 Meta 开源 Llama 模型后,大量的微调模型出现,大部分模型都在 Llama 模型的基础上扩大了词表。例如,01-ai 的 Yi-1.5 将词表大小从 32000 扩展至 64000。
扩大词表的作用:
提高语言覆盖率:扩大词表可以使模型覆盖更多的词汇,特别是包含罕见词汇、专业术语、新词以及多语言环境下的词汇。这对于处理多样化的文本数据,提高模型在特定领域(如医学、法律或多语言环境)的应用效果非常重要。
减少未知词(OOV)问题:通过增加词表大小,可以减少在文本处理中遇到的未知词(Out-Of-Vocabulary, OOV)问题。这有助于提高模型处理未见过文本的能力,从而在一定程度上提升模型的泛化性能。
提升模型细粒度:较大的词表使得模型能够识别和生成更加细粒度的文本信息。例如,在生成任务中,模型能够生成更丰富、更精确的文本内容;在理解任务中,模型能更准确地捕捉到文本的细微差别。
增强多语言和跨文化理解:对于支持多种语言的大型语言模型,扩大词表是必要的,以确保覆盖更广泛的语言和文化。这有助于模型在全球范围内的适用性和灵活性,提升跨语言、跨文化交流的能力。
...
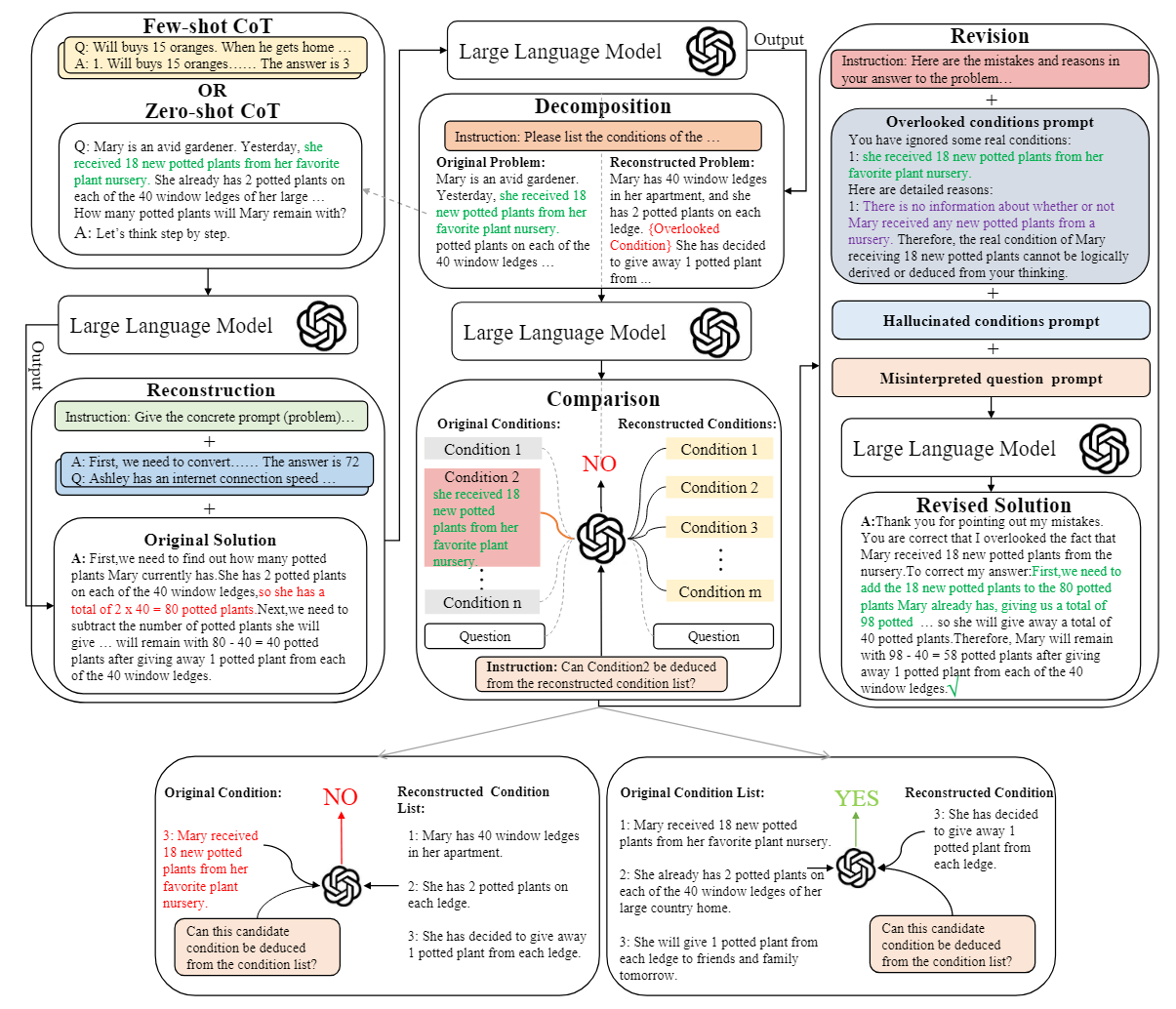
论文阅读:RCoT Detecting and Rectifying Factual Inconsistency in Reasoning by Reversing Chain-of-Thought
大语言模型(LLMs)通过结合逐步思维链(step-by-step CoT)提示,在算术推理任务中取得了可喜的成绩。然而,大语言模型在推理过程中保持事实一致性方面面临挑战,在特定问题上表现出条件忽略、问题曲解和条件幻觉的倾向。现有方法使用粗粒度反馈(如答案是否正确)来提高事实一致性。在这项工作中,作者提出了 RCOT(Reverseing Chain-of-Thought),一种通过自动检测和纠正 LLM 生成的解决方案中的事实不一致性来提高 LLM 推理能力的新方法。为了检测事实不一致,RCOT 首先要求 LLM 根据生成的解决方案重建问题。然后,对原始问题和重构问题进行细粒度比较,以发现原始解决方案中的事实不一致之处。为了纠正解决方案,RCoT 将检测到的事实不一致转化为细粒度反馈,以指导 LLM 修订解决方案。
实验结果表明,在七个算术数据集上,RCoT 比标准 CoT 有持续的改进。此外,作者还发现,人工编写的细粒度反馈可以显著提高 LLM 的推理能力(例如,ChatGPT 在 GSM8K 上的准确率达到 94.6%),从而鼓励社区进一步探索细粒度反馈生成方法。
RCoT 方法 ...
Transformer 架构中的位置编码
Transformer 模型需要位置编码来处理序列数据,因为其核心机制——自注意力(Self-Attention)本身并不具备捕捉序列中元素位置信息的能力。自注意力机制允许模型在计算一个元素的表征时考虑到序列中的所有元素,但是它对这些元素是如何排序的一无所知。这与传统的序列处理模型(如循环神经网络 RNN 和长短期记忆网络 LSTM)不同,后者通过逐个元素的递归处理天然地编码了位置信息。
Transformer 模型的设计理念是完全摒弃递归处理,从而允许并行计算,这极大地提高了训练的效率。然而,这也意味着模型丧失了捕捉序列中位置关系的能力。为了解决这个问题,Transformer 引入了位置编码(Positional Encoding)作为补充信息,确保模型能够利用序列中元素的位置信息。
绝对位置编码绝对位置编码比较简单,研究者一般会将绝对位置信息加到输入中:在输入的第 k 个向量 $x_k$ 中加入位置向量 $p_k$ 得到 $x_k + p_k$,其中 $p_k$ 仅与 k 相关。计算 $p_k$ 的方法一般有两种:
训练式:将位置向量 P 设置为可训练的参数,如 BERT 就将 ...
AI 情感聊天机器人之旅 —— 多轮对话存在的问题与数据积累
在 QA、逻辑推理等领域,多跳问答比单跳问答难得多。在聊天机器人场景中亦是如此,模型需要结合历史对话和用户当前的输入内容生成合适的响应。然而,现有的指令数据大都是单轮或者两轮的对话(截止这篇文章落笔的日期 2023-09-10),模型在对话轮数较少时,还能很好地遵循指令、记住历史信息以及输出合适的内容。但对话轮数多了后,模型的输出往往会变得不可控,例如越来越长、格式出现错误、遗忘历史信息、指令遵循能力变弱(人设不符)。一方面是因为上下文变长、加上 Lost in the middle 等 prompt 层面的影响;另一方面是模型在多轮对话下的对齐能力较弱(多轮对话数据的训练数据质量较差,且在 long context 场景下“锻炼”得不够)。
在处理多跳问题和数学推理等较难任务时,除了在模型层面做优化外,往往会使用 CoT 系列的 prompt 工程,例如“Let’s think step by step”的方式。我理解它们能提升 LLM 推理能力的一部分原因在于将任务拆解,输出中间步骤,对于从左到右的生成式模型来说,这些补齐的中间步骤的生成为输入空间带来了更细致的条件约束,而这些条件 ...
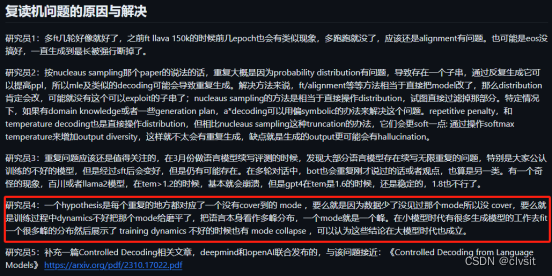
AI 情感聊天机器人工作之旅 —— 与复读机问题的相遇与别离
前言:先前在杭州的一家大模型公司从事海外闲聊机器人产品,目前已经离职,文章主要讨论在闲聊场景下遇到的“复读机”问题以及一些我个人的思考和解决方案。文章内部已经对相关公司和人员信息做了去敏,如仍涉及到机密等情况,可删除。
meta 开源 Llama2 后,我们立马将基座模型从 Llama1 更换为了 Llama2。很重要的一个原因在于 Llama2 的 context length 是 4k,是 Llama1 的 2 倍,对于日益增长的角色人设 prompt 来说,2k 已经不满足线上产品使用。
在将 base 模型从 Llama1 “升级”到 Llama2 后出现了单句重复问题,该问题也被业界定义为“复读机问题”——模型会在一轮回复中不断重复某一相同或语义相似的子句,直到 max_new_tokens(最大输出长度)。
PS:Llama1 有没有这个问题已经无法追溯,其一,当时还没有在 sentry 查看日志链路的习惯;其二,产品和社区没有反馈该类问题,产品妹子们更多地是反馈多轮重复问题——模型在多轮对话中重复相同的内容。
由于当时尚处于 8 月份,vLLM 框架的集成以及后续将部 ...
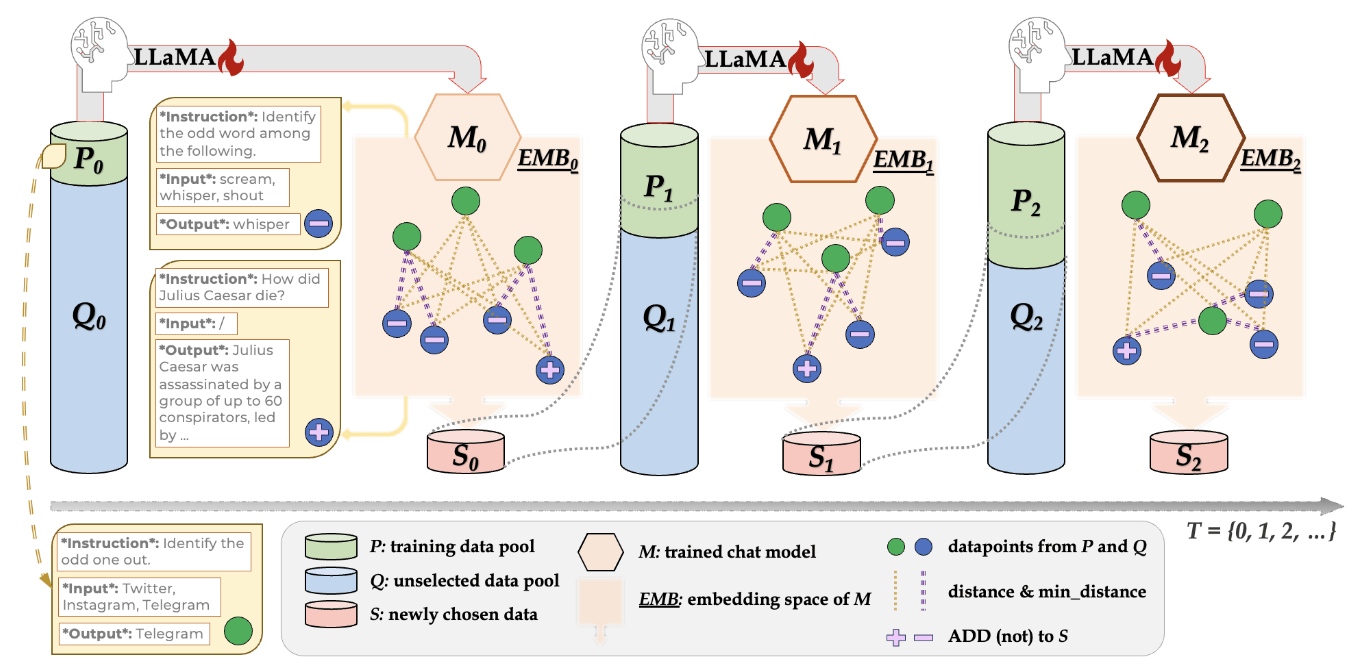
论文阅读:Self-Evolved Diverse Data Sampling for Efficient Instruction Tuning 数据子集挑选方法
论文链接:https://arxiv.org/abs/2202.06417
GitHub 仓库:https://github.com/OFA-Sys/DiverseEvol
提高大型语言模型(LLM)的指令遵循能力主要需要大量的指令调整数据集。然而,这些数据集的庞大数量带来了相当大的计算负担和标注成本。为了研究一种标注效率高的指令调整方法,使模型本身能够主动采样同样有效甚至更有效的子集,作者引入了一种自进化机制 DIVERSEEVOL。在这一过程中,模型会反复增强其训练子集,以完善自身性能,而无需人类或更高级 LLM 的干预。该数据采样技术的关键在于提高所选子集的多样性,因为模型会根据其当前的嵌入空间选择与任何现有数据点最不同的新数据点。三个数据集和基准的广泛实验证明了 DIVERSEEVOL 的有效性。与在全部数据上进行微调相比,在不到 8% 的原始数据集上训练的模型保持或提高了性能。作者还提供了经验证据来分析指令数据多样性的重要性,以及迭代方案相对于一次性采样的重要性。
方法:DIVERSEEVOL迭代指令数据选择目标是将指令数据挖掘正规化,使其成为一个迭代过程,按照一定的策略从庞 ...
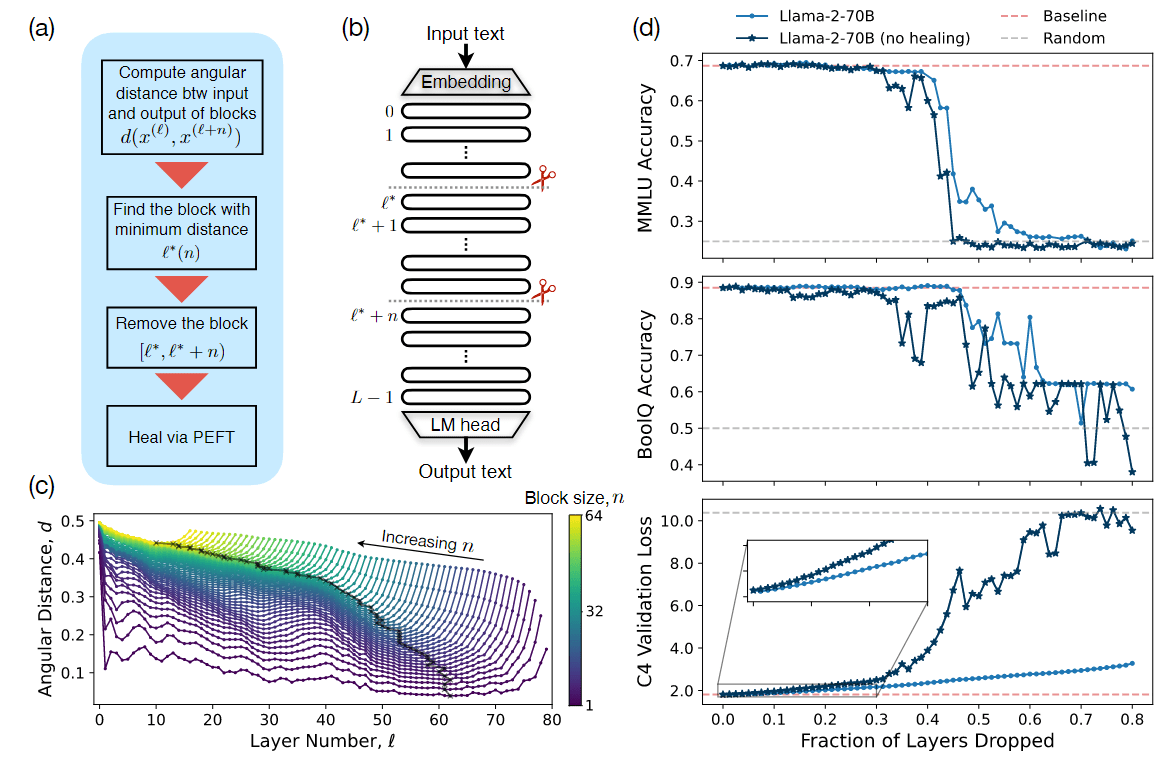
论文阅读:The Unreasonable Ineffectiveness of the Deeper Layers 层剪枝与模型嫁接的“双生花”
作者实证研究了针对流行的开放式预训练 LLM 系列的简单层修剪策略,发现在不同的 QA 基准上,直到去掉一大部分(最多一半)层(Transformer 架构)后,性能的下降才会降到最低。为了修剪这些模型,作者通过考虑各层之间的相似性来确定要修剪的最佳层;然后,为了“治愈”损伤,进行了少量的微调。特别是 PEFT 方法,尤其是量化和低秩适配器(QLoRA),这样每个实验都可以在单张 A100 GPU 上完成。
从实用的角度来看,这些结果表明,层剪枝方法一方面可以补充其他 PEFT 策略,进一步减少微调的计算资源,另一方面可以改善推理的显存开销和生成时延。从科学角度看,这些 LLM 对层删除的鲁棒性意味着,要么当前的预训练方法没有正确利用网络深层的参数,要么浅层在存储知识方面起着关键作用。
方法作者在论文中写道:移除层的直觉来自于将表征视为层索引的缓慢变化函数,特别是 transformer 层与层之间的表征变化由一个残差迭代方程给出:$$x^{(l + 1)} = x^{(l)} + f(x^{(l)}, \theta^{(l)})$$
注意:现在的 LLM 大都是 pre-n ...
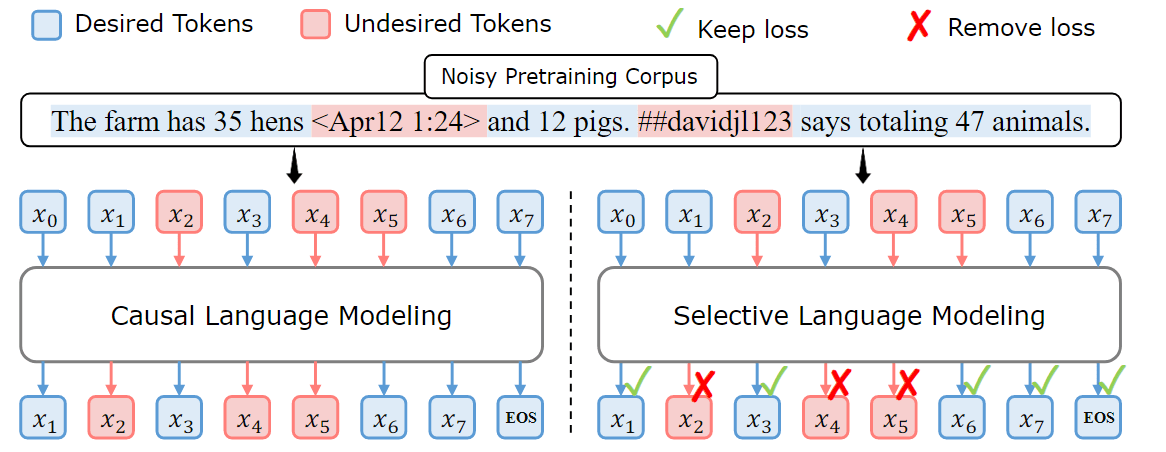
论文阅读:RHO-1:Not All Tokens Are What You Need 选择你需要的 Tokens 参与训练
论文链接:https://arxiv.org/abs/2404.07965
以往的语言模型预训练方法对所有训练 token 统一采用 next-token 预测损失。作者认为“并非语料库中的所有 token 对语言模型训练都同样重要”,这是对这一规范的挑战。作者的初步分析深入研究了语言模型的 token 级训练动态,揭示了不同 token 的不同损失模式。利用这些见解,推出了一种名为 RHO-1 的新语言模型。与学习预测语料库中 next-token 的传统 LM 不同,RHO-1 采用了选择性语言建模 (SLM),即有选择地对符合预期分布的有用 token 进行训练。这种方法包括使用参考模型对预训练 token 进行评分,然后对超额损失较高的 token 进行有针对性损失的语言模型训练。
在 15B OpenWebMath 语料库上进行持续预训练时,RHO-1 在 9 项数学任务中获得了高达 30% 的 few-shot 准确率绝对提升。经过微调后,RHO-1-1B 和 7B 在 MATH 数据集上分别取得了 40.6% 和 51.8% 的一流结果——仅用 3% 的预训练 token ...
论文阅读:《Sequence can Secretly Tell You What to Discard》,减少推理阶段的 kv cache
目前各类大模型都支持长文本,例如 kimi chat 以及 gemini pro,都支持 100K 以及更高的上下文长度。但越长的上下文,在推理过程中需要存储的 kv cache 也越多。假设,数据的批次用 b 表示,输入序列的长度仍然用 s 表示,输出序列的长度用 n 表示,隐藏层维度用 h 表示,层数用 l 表示。kv cache 的峰值显存占用大小 = $b * (s + n) * h * l * 2 * 2 = 4blh(s + n)$,这里的第一个 2 表示 k 和 v cache,第二个 2 表示 float16 数据格式存储 kv cache,每个元素占 2 bytes。
然而,目前的大多数 LLM 会使用 GQA 而非 MHA,因此 kv cache 的占用量会更少,以 transformers 的 modeling_llama.py 脚本中的实现为例:
123456789101112131415161718192021class LlamaAttention(nn.Module): def __init__(self, config: Lla ...
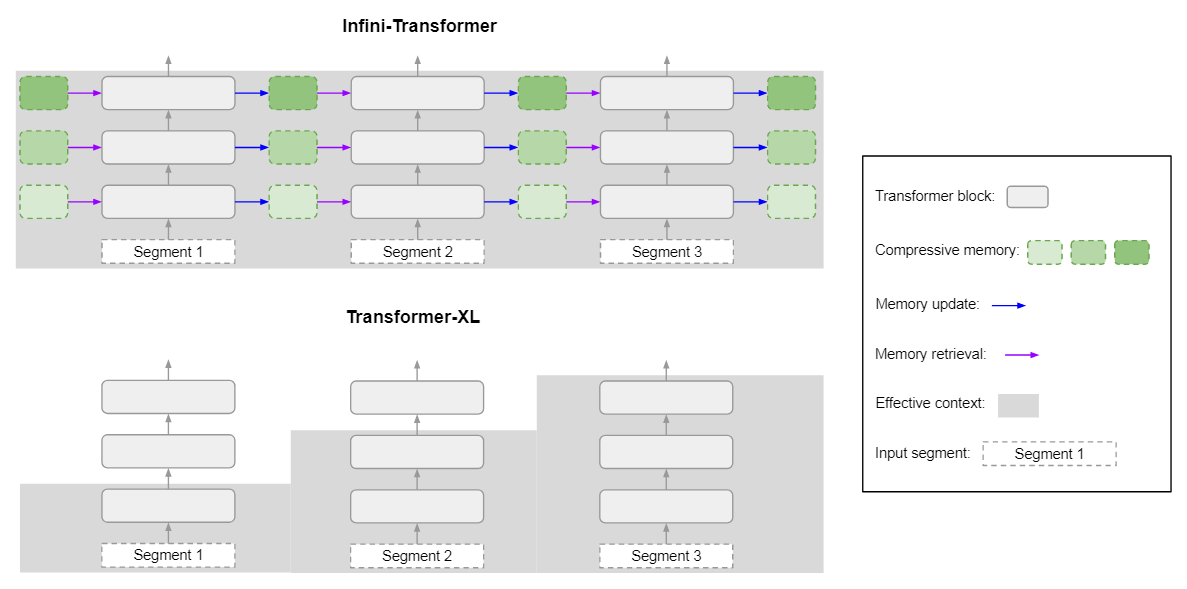
论文阅读:Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
这项研究介绍了一种高效的方法,可将基于 Transformer 的大型语言模型(LLM)扩展到无限长的输入,同时限制内存和计算量。该方法的一个关键组成部分是一种新的注意力技术,被称为 Infini-attention。Infini-attention 在 vanilla 注意力机制中加入了压缩内存,并在单个 Transformer 块中建立了掩码局部注意和长期线性注意机制。
作者使用 1B 和 8B LLM,在长上下文语言建模基准、1M 序列长度的 passkey context block 检索和 500K 长度的书籍摘要任务中展示了该方法的有效性。该方法引入了最小的有界内存参数,实现了 LLM 的快速流推理。
方法图 2 比较了提出的模型、Infini-Transformer 和 Transformer-XL。与 Transformer-XL 类似,Infini-Transformer 也是在一个片段序列上运行。作者在每个片段中计算标准的因果点积注意力上下文。因此,点积注意力计算是局部的,即它覆盖了当前片段中索引为 S 的 N 个 token(N 为片段长度)。然而,局部注意力(D ...
最新文章