检索增强 LLM(Retrieval Augmented LLM),简单来说,给 LLM 提供外部数据库,对于用户问题(Query),通过一些信息检索(Information Retrieval,IR)的技术,先从外部数据库中检索出和用户问题相关的信息,然后让 LLM 结合这些相关信息来生成结果。这种模式有时也被称为检索增强生成(Retrieval Augmented Generation,RAG)。
目的:幻觉问题(Hallucinations)仍然是当前 LLM 面临的一个重要挑战。简单来说,幻觉问题是指 LLM 在生成不正确、荒谬或者与事实不符的结果。此外,数据新鲜度(Data Freshness)也是 LLM 在生成结果时出现的另外一个问题,即 LLM 对于一些时效性比较强的问题可能给不出或者给出过时的答案。RALLM 通过检索外部相关信息的方式来增强 LLM 的生成结果是当前解决以上问题的一种流行方案。
传统的信息检索工具,比如 Google/Bing 这样的搜索引擎,只有检索能力(Retrieval-only),现在 LLM 通过预训练过程,将海量数据和知识嵌入到其巨大的模型参数中,具有记忆能力(Memory-only)。从这个角度看,检索增强 LLM 处于中间,将 LLM 和传统的信息检索相结合,通过一些信息检索技术将相关信息加载到 LLM 的工作内存(Working Memory)中,即 LLM 的上下文窗口(Context Window),亦即 LLM 单次生成时能接受的最大文本输入。
应用场景
为什么要结合传统的信息检索系统来增强 LLM?换句话说,基于检索增强的 LLM 主要解决的问题和应用场景是什么?
主要解决问题
长尾知识
虽然当前 LLM 的训练数据量已经非常庞大,动辄几百 GB 级别的数据量,万亿级别的 token 数量,比如 GPT-3 的预训练数据使用了 3000 亿量级的 token,LLaMA 使用了 1.4 万亿量级的 token。训练数据的来源也十分丰富,比如维基百科、书籍、论坛、代码等。LLM 的模型参数量也十分巨大,从几十亿、百亿到千亿量级,但让 LLM 在有限的参数中记住所有知识或者信息是不现实的,训练数据的涵盖范围也是有限的,总会有一些长尾知识在训练数据中不能覆盖到。
对于一些相对通用和大众的知识,LLM 通常能生成比较准确的结果,而对于一些长尾知识,LLM 生成的回复通常并不可靠。ICML 会议上的这篇论文 [Large Language Models Struggle to Learn Long-Tail Knowledge] 就研究了 LLM 对基于事实的回答的准确性和预训练数据中相关领域文档数量的关系,发现有很强的相关性,即预训练数据中相关文档数量越多,LLM 对事实性问答的回复准确性就越高。从这个研究中可以得出一个简单的结论——LLM 对长尾知识的学习能力比较弱。
为了提升 LLM 对长尾知识的学习能力,除了在训练数据中加入更多的相关长尾知识,或者增大模型的参数量外(这两种方法确实都有一定的效果,但不经济,需要很大的训练数据量级和模型参数才能大幅度提升 LLM 对长尾知识的回复准确性),通过检索的方法把相关信息在 LLM 推断时作为上下文(Context)给出,既能达到一个比较好的回复准确性,也是一种比较经济的方式。
私有数据
通用 LLM 预训练阶段使用的大部分都是公开的数据,不包含私有数据,因此对于一些私有领域的知识是欠缺的。比如某个企业内部的规章制度等等。虽然可以在预训练阶段加入私有数据或者利用私有数据进行微调,但训练和迭代成本很高。此外,通过一些特定的攻击手法可以让 LLM 泄露训练数据,如果训练数据中包含一些私有ixnxi,则很可能会发生隐私信息泄露。
如果把私有数据作为一个外部数据库,让 LLM 在回答基于私有数据的问题时,直接从外部数据库中检索出相关信息,再结合检索出的相关信息进行回答。这样就不用通过预训练或者微调的方法让 LLM 在参数中记住私有知识,既节省了训练或者微调成本,也一定程度上避免了私有数据的泄露风险。
数据新鲜度
由于 LLM 中学习的知识来自于训练数据,虽然大部分知识的更新周期不会很快,但依然会有一些知识或者信息更新得很频繁。LLM 通过从预训练数据中学到的这部分信息就很容易过时。比如,GPT-4 模型使用的是截至 2021-09 的预训练数据,因此涉及这个日期之后的事件或者信息,它会拒绝回答或者给出的回复是过时或者不准确的。
如果把频繁更新的知识作为外部数据库,供 LLM 在必要的时候进行检索,就可以实现在不重新训练 LLM 的情况下对 LLM 的知识进行更新和拓展,从而解决 LLM 数据新鲜度的问题。
来源验证和可解释性
通常情况下,LLM 生成的输出不会给出其来源,比较难解释为什么会这么生成。而通过给 LLM 提供外部数据源,让其基于检索出的相关信息进行生成,就在生成的结果和信息来源之间建立了关联,因此生成的结果就可以追溯参考来源,可解释性和可控性就大大增强。即可以知道 LLM 是基于什么相关信息来生成的回复。利用检索来增强 LLM 的输出,其中很重要的一步是通过一些检索相关的技术从外部数据中找出相关信息片段,然后把相关信息片段作为上下文供 LLM 在生成回复时参考。
框架设计
Naive RAG
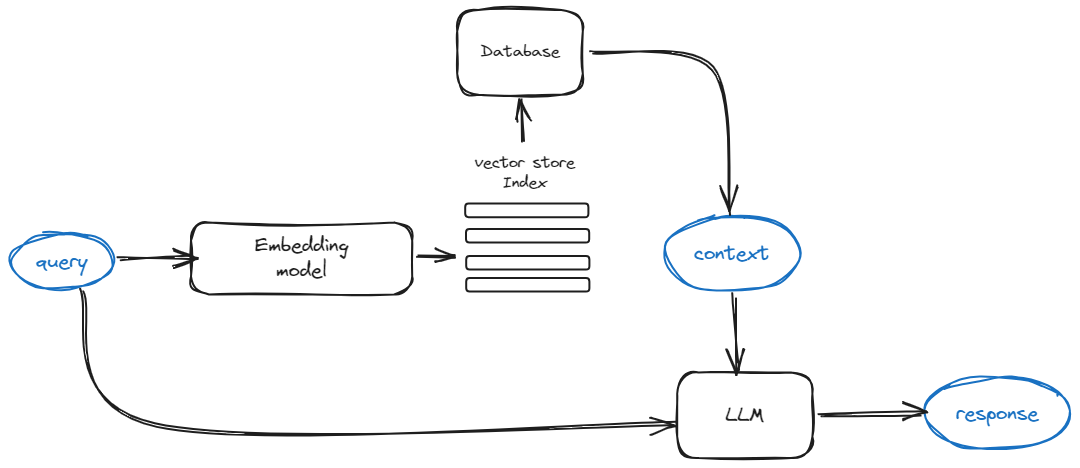
Naive(Vanilla)RAG 的处理流程如上图所示:
- 将文本分割成块;
- 借助 Sentence Embedding 将文本块编码成向量,并存储到向量数据库,例如 Milvus;
- 在已有的 prompt 基础上拼接根据向量相似度检索得到 top-k 个文本块;
- 最后,将完整的 prompt 送入模型,得到模型生成的响应。
关键模块
为了构建 RAG 系统,需要实现的关键模块和这些模块需要实现的功能和解决的问题:
- 数据索引模块:如何处理外部数据和构建索引。
- 抽取存储模块:如何从数据中抽取知识并进行存储。
- 查询检索模块:如何准确高效地检索出相关信息。
- 响应生成模块:如何利用检索出的相关信息来增强 LLM 的输出。
数据索引模块
在模块考虑如何获取并清洗外部数据,并根据数据的类型选择合适的索引(存储库)。
数据索引
经过前面的数据读取和文本分块操作后,接着就需要对处理好的数据进行索引。索引是一种数据结构,用于快速检索出与用户查询相关的文本内容,是检索增强 LLM 的核心基础组件之一。
LlamaIndex 介绍并提供了几种常见的索引结构。
- 节点(Node):对应于文档中的文本块,LlamaIndex 接收 Document 对象,并在内部将其解析/分块为 Node 对象。
- 响应合成(Response Synthesis):根据检索到的 Node 合成响应。
抽取存储模块
抽取服务为每个抽取请求启动一个后台处理子线程。无论启动成功与否,都会直接返回结果。在后台处理子线程中,会依次经过前处理、LLM Agents 抽取信息以及后处理,最后将抽取得到的信息存入数据库。
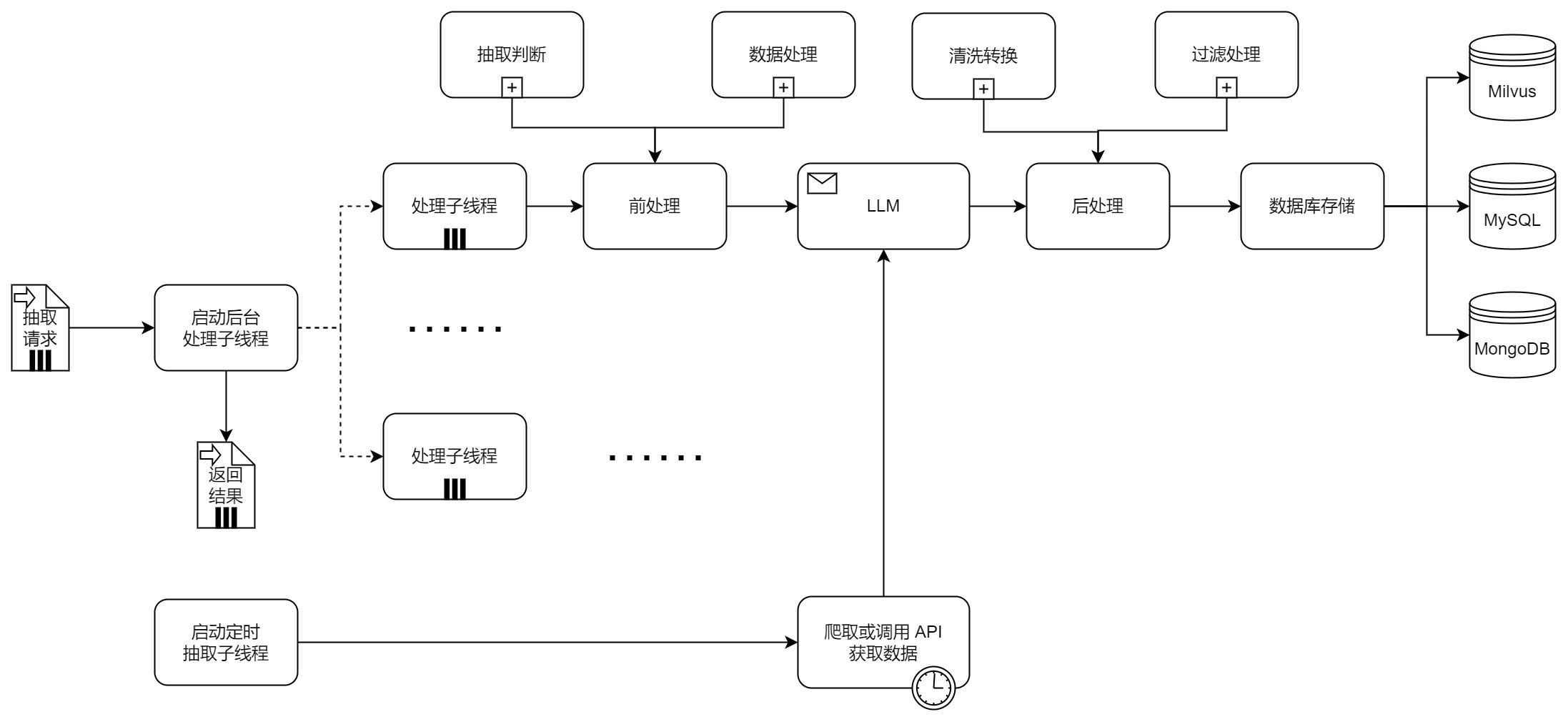
后处理环节
承接 LLM Agents 抽取或者爬虫以及人为标注的内容,对其进行清洗转换、并根据规则或其他 Agents 进行过滤和改写,确保信息的质量和完整。
清洗转换
存储的数据和信息决定了 RAG 答案的质量,因此在入库(建立索引)之前,需要对得到的数据做清洗或者格式上的转换处理,来保证数据的质量,以及方便下游的检索工作。
数据清洗的 Tips:
- 清除特殊字符、奇怪的编码、不必要的HTML标记来消除文本噪声(比如使用regex);
- 找出与主要主题无关的文档异常值并将其删除(可以通过实现一些主题提取、降维技术和数据可视化来实现这一点);
- 使用相似性度量删除冗余文档(PS:该方法不一定可行,因为相似性较高的两篇文档可能有不同的关键信息,因为绝大部分内容的相似而忽略少数的核心不相似,会遗漏信息,这很考验 sentence embedding 模型的能力)。
查询检索模块
检索的难点在于如何将用户输入的查询文本和抽取到的知识进行关联。更具性价比的做法是尽可能地让抽取到的知识点信息丰富,去适配业务场景的用户输入,仅通过相似度检索的方式快速地获取匹配的内容。另一种做法是对用户输入的查询做转换,明确要查询的内容,去适配抽取到的知识点。但该做法需要对用户的每个输入做转换,成本和时延都会增加。
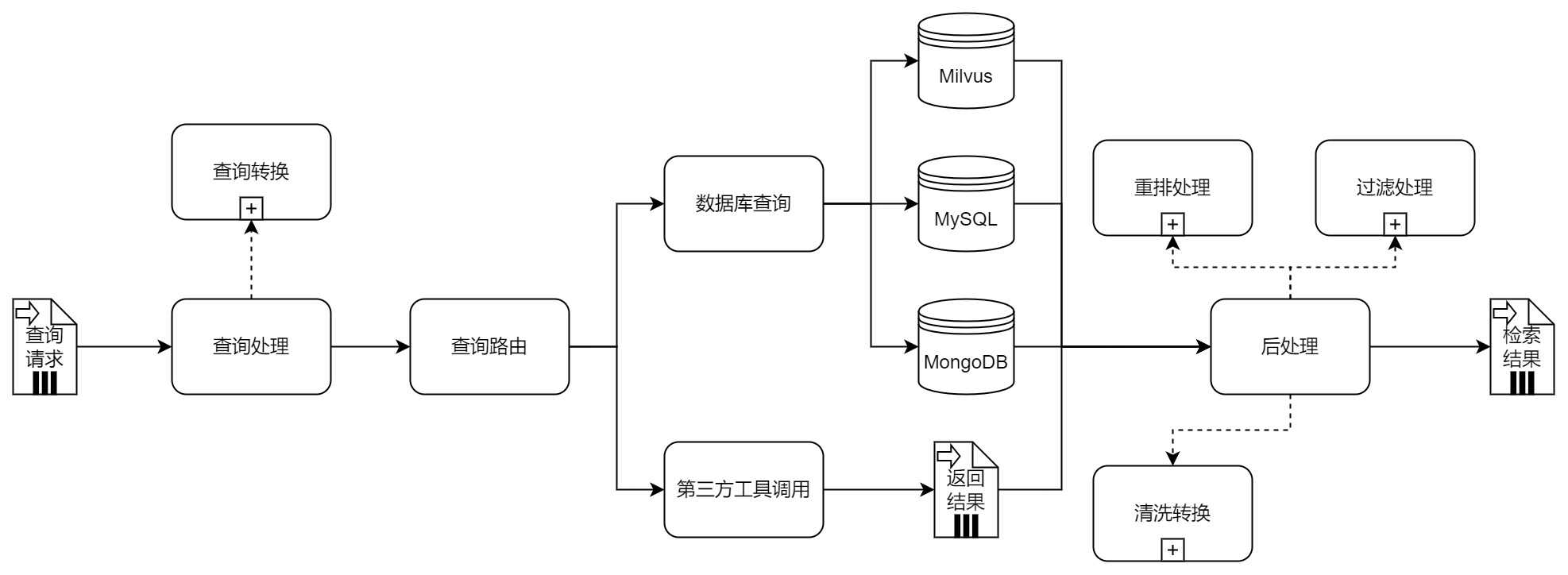
前处理环节
检索服务收到查询请求对象后,根据查询请求对象内部或配置文件的设置来判断是否要对查询请求对象进行处理,例如查询转换。
检索环节
后处理环节
在上一步查询路由模块处理完成后,后处理模块从数据库中查询得到的结果或者第三方工具返回的结果,这些结果可能是错误、冗余,亦或是混杂大量无关信息,需要对其进行过滤、清洗、转换和重排序,挑选出符合要求的文档集合。
响应生成模块
在获取检索到的知识后,该如何将这部分内容拼接到 prompt,让模型能够“关注”到并给出合理的回复是一个较为棘手的问题。这涉及到 prompt 工程和模型对 context 的理解能力。
- 直接放在 prompt:比较简单的操作方式,将检索到的文本内容直接拼接到 prompt 中,当成一个上下文送入大模型内,让大模型自行去获取和理解。
- KNN + LLM:在推理中,将两个 next_token 分布进行融合解码,一个分布来自 LLM 自身输出,另一个是来自检索的 top-k token,具体为利用 LLM embedding 方式在外挂知识库中查找与 query token 相似的 token。
- 自回归检索 + 解码:先利用 LLM 解码出部分 token,然后检索与该 token 相似的文本,然后拼接在 prompt 中,进行 next tokens 预测,以自回归的方式完成解码。

评估体系
评估指标
RAG 的评估方法多样,主要包括三个质量评分:上下文相关性、答案忠实性和答案相关性。
关键能力:噪声鲁棒性、拒答能力、信息整合和反事实鲁棒性。
评估框架
存在如 RGB 和 RECALL 这样的基准测试,以及 RAGAS、ARES 和 TruLens 等自动化评估工具,它们有助于全面衡量 RAG 模型的表现。
- Ragas
- TruLens
相关研究
相关工具
RAG 库
- FlashRAG:FlashRAG 是一个 Python 工具包,用于再现和开发检索增强生成(RAG)研究。该工具包包括 32 个经过预处理的基准 RAG 数据集和 12 种最先进的 RAG 算法。
- GoMate:是一款配置化模块化的Retrieval-Augmented Generation (RAG) 框架,旨在提供可靠的输入与可信的输出,确保用户在检索问答场景中能够获得高质量且可信赖的结果。该框架的设计核心在于其高度的可配置性和模块化,使得用户可以根据具体需求灵活调整和优化各个组件,以满足各种应用场景的要求。
- GraphRAG:GraphRAG 项目是一个数据管道和转换套件,旨在利用 LLM 的强大功能从非结构化文本中提取有意义的结构化数据。
辅助工具
- ChunkViz:一个可视化 chunk 的在线工具。
- Reader:是一个可以将任何 URL 转换成适合 LLM 输入格式的工具,在 URL 前添加前缀“https://r.jina.ai/”来实现。
- Tiktokenizer:在线计算 tokens 的工具。
- Open-Parse:提供了一个灵活易用的库,能够直观地辨别文档布局并有效地对其进行分块,是任何 RAG 系统的基础。
- unstructured:非结构化库提供了用于摄取和预处理图像和文本文档(如 PDF、HTML、Word 文档等)的开源组件。非结构化库的用例围绕着简化和优化 LLM 的数据处理工作流程。非结构化库的模块化功能和连接器形成了一个内聚系统,简化了数据摄取和预处理,使其能够适应不同的平台,并高效地将非结构化数据转化为结构化输出。



