上下文外推
长期记忆外挂
InfLLM
- GitHub 仓库:https://github.com/thunlp/InfLLM
- 论文地址:https://arxiv.org/abs/2402.04617
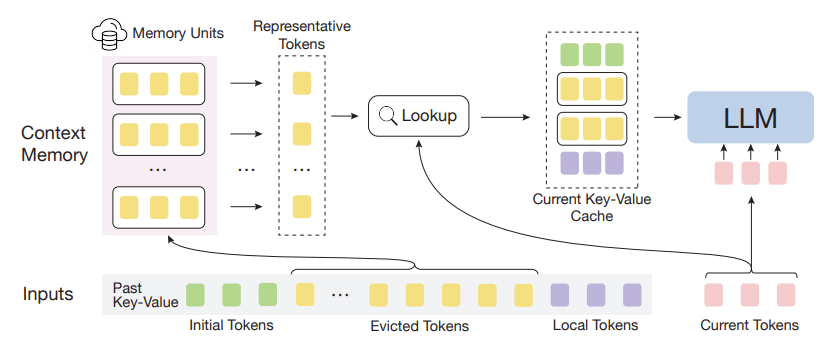
InfLLM 将遥远的上下文存储到额外的内存单元中,并采用有效的机制来查找与 token 相关的单元以进行注意力计算。因此,InfLLM 允许 LLM 有效地处理长序列,同时保持捕获长距离依赖性的能力。
推理优化
减少 kv cache
随着模型规模的增大,推理需要的时间越来越多。kv cache 作为推理加速的关键技术,通过缓存之前的解码步骤中计算出的 key_states 和 value_states 来避免在后续解码过程中重复计算,从而减少解码时间(起到空间换时间的作用)。
但是,随着序列长度增大,需要缓存的 kv cache 呈线性增长,占用大量显存。针对这一问题,之前的工作设计策略是调整注意力机制,或者对 kv cache 进行压缩。
调整注意力机制
GQA:论文阅读:GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
- 论文地址:https://arxiv.org/abs/2305.13245
- 发表日期:2023-06-02
MLA:缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA
PS:MLA 是深度求索公司 deepseek-v2 论文中提出的注意力机制。个人建议可以先看苏神的这篇博客,深入浅出地从 MHA、MQA、GQA 到 MLA 的发展路径以及 MLA 的思想讲述了一遍。
- 论文地址:https://arxiv.org/abs/2405.04434
- 发表日期:2024-05-07
- GitHub 仓库:https://github.com/deepseek-ai/DeepSeek-V2
- 代码地址:https://huggingface.co/deepseek-ai/DeepSeek-V2-Chat/blob/main/modeling_deepseek.py
CLA:麻省理工(MIT) | 提出跨层Attention,减少Transformer大模型键值(KV)缓存,加快LLM推理! - NLP自然语言处理的文章 - 知乎
发表日期:2024-05-21
简要介绍:提出了一种新的 Attention 设计方法:跨层注意力(Cross-Layer Attention,CLA),即通过在不同层之间共享 key 和 value 头来减少 kv cache 的存储大小。
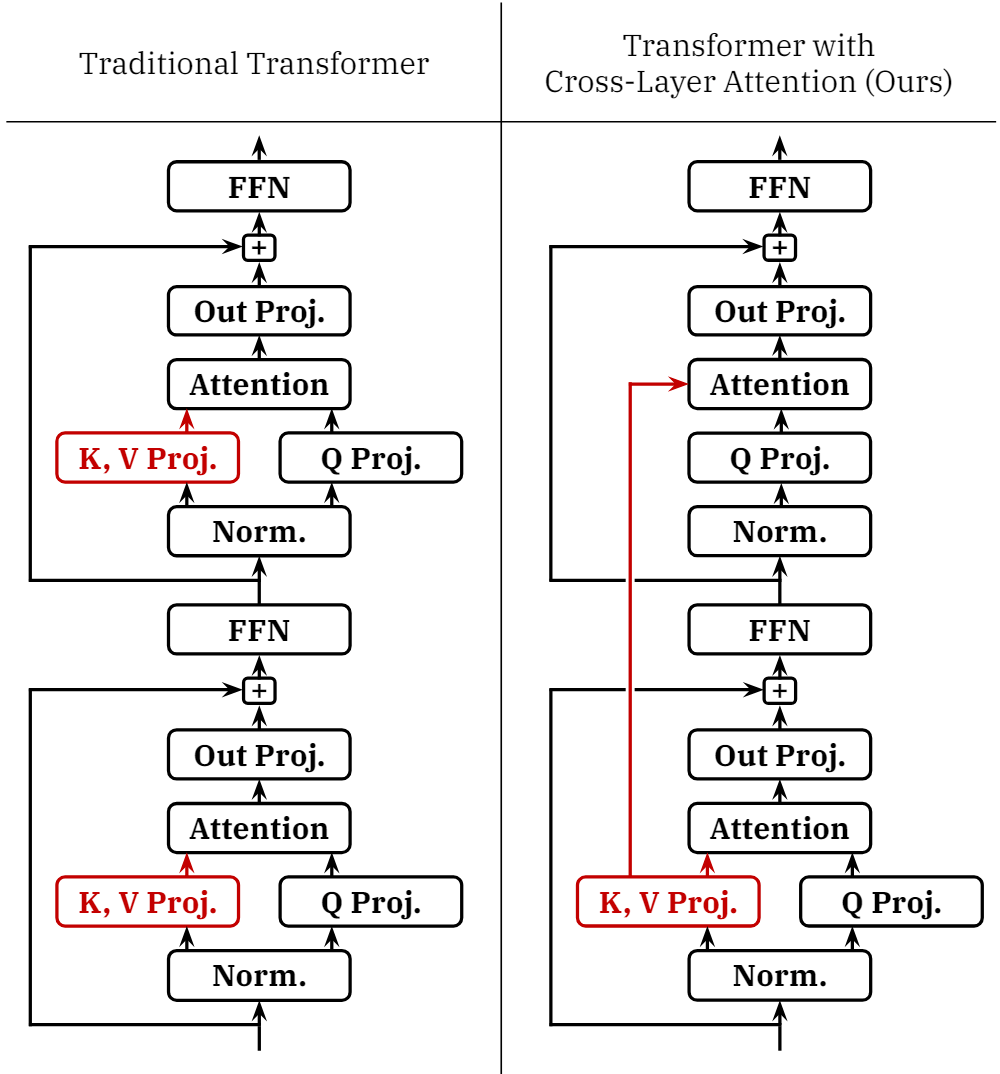
可以看到在 CLA 中,只有模型中一部分层会计算 kv Proj,而没有计算 kv Proj 层的 Attention 块会重新使用之前层的 kv Proj。可以理解为若干相邻层共享某一层的 kv Proj。MQA 和 GQA 从 key 和 value 头上做了分组,而 CLA 则在 Attention 块上做了“分组”。因此,CLA 可以和 MQA、GQA 进行组合。
PS:CLA 之于 MHA 等同于 ALBERT 之于 BERT(ALBERT 将 Transformer 层的所有参数共享)。实际上这篇文章并没有什么新鲜的,无非是将 ALBERT 中的 Transformer 层的所有参数共享,改为对 kv Proj“分组”进行共享。
为了增加论文的工作量,在系统工程角度总结了 CLA 对相关关键指标的影响:
- kv cache:显著减少了 kv cache 的内存占用量,减少的倍数等于共享因子。
- 训练内存占用:CLA 减少了训练期间 kv Proj 激活值的内存占用。
- 模型并行性:CLA 完全兼容张量并行技术,可用于跨多个加速器分片模型权重。
- 参数和 FLOPs:CLA 减少了模型参数的数量,因此在前向和反向传播过程中所需的 FLOPs 也降低。
- 解码延迟:在推理过程中,虽然通过复制取代矩阵乘法来减少了 FLOPs,但影响很少,核心还是在于减少了 kv cache,能够提供更大的 batch size,从而提升服务的总吞吐量。
Block Transformer:拆分Transformer注意力,韩国团队让大模型解码提速20倍 - 量子位的文章 - 知乎
发表日期:2024-06-04
简要介绍:核心思路是将原始 Transformer 的全局注意力分解成块级注意力和块内注意力,引入 Block Decoder 处理块级注意力,Token Decoder 处理块内注意力,如下图所示。
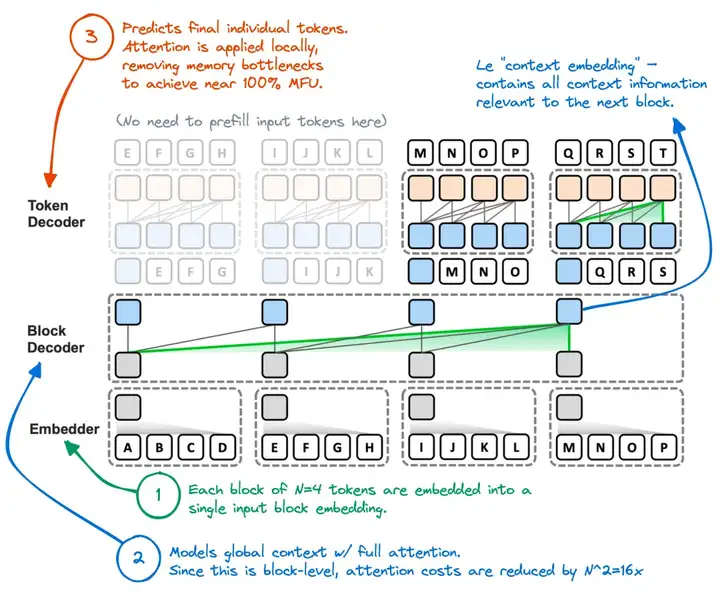
工作流程:
- 先执行序列切块,使用 Embedder 将一个块内的 token embedding 信息汇总到 block embedding(即上图灰色块)。
- Block Decoder 仍然以从左到右关注的方式来处理 block embedding 间的信息交互,捕捉块间的全局依赖。
- Token Decoder 处理块内 token embedding(即上图蓝色块),捕获 token 间的局部依赖。
- 交替执行块级自回归建模和块内自回归解码。
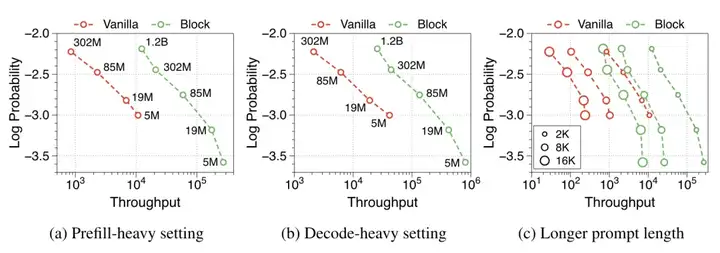
在推理的 decode 阶段,原先需要 attend 所有的 kv,现在只需要先 attend 块级 kv,然后再 attend 块内 kv,数量大大减少。具体的量取决于块的大小。较大的块可以减少块的数量,从而降低 Block Decoder 的计算复杂度,但每个块包含更多的 token,可能影响局部依赖的建模能力;较小的块包含的 token 更少,可以提高局部依赖的建模能力,但 Block Decoder 需要处理更多的块,会增加计算复杂度。
按照论文的说法,Block Transformer 能够提升 20 倍的吞吐量,同时还能保持较低的训练损失。
kv cache 压缩
论文阅读:《Sequence can Secretly Tell You What to Discard》,减少推理阶段的 kv cache
发表日期:2024-04-24
简要介绍:研究发现在 LLaMA2 系列模型上:(i)相邻 token 的 query 向量之间的相似度非常高,(ii)当前 query 的注意力计算可以完全依赖于一小部分前面 query 的注意力信息。基于这些观察结果,作者提出了一种无需重新训练的 KV 缓存驱逐策略 CORM,通过重复使用最近的 query 注意力信息来显著减少显存占用。
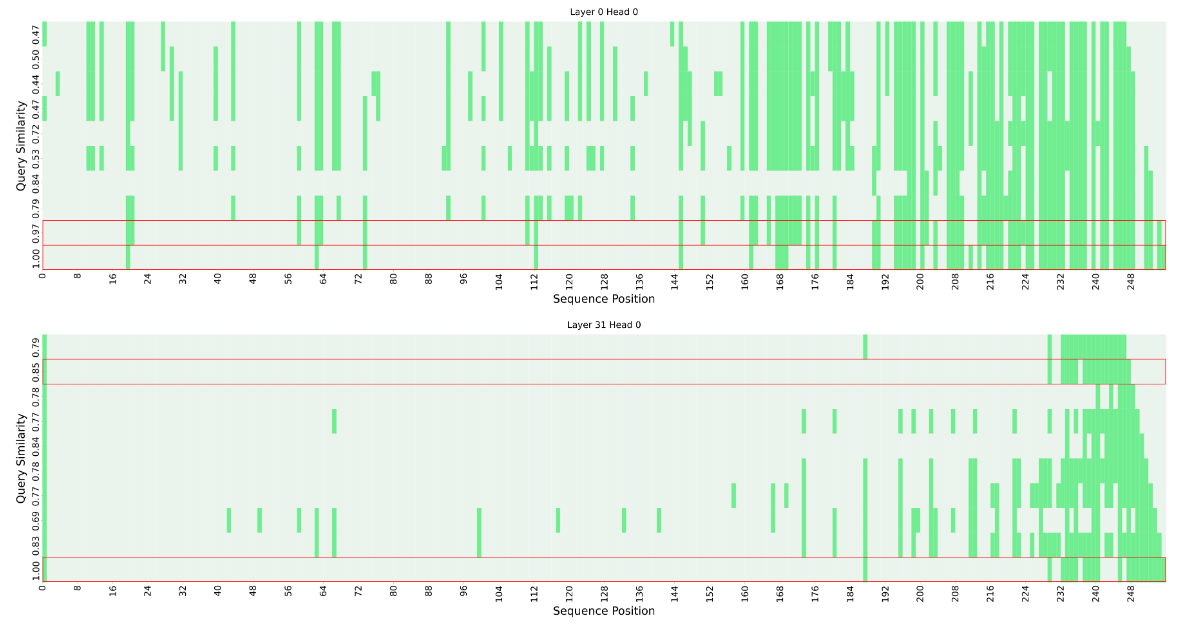
该论文与 StreamingLLM 中提出的 attention sink、Label are anchor 等论文以及 prompt 压缩的可行性都能在理论方面进行印证。但该论文提出的 CORM 方法也存在一个缺陷,是否存在某个 key 与未来一段时间内的 query 的相似度都很低,在这之后才出现较高的相似度。而此时,如果将该 key 认为是不重要而进行丢弃的话,未来的 query 可能获取不到这部分信息。
2.5%KV缓存保持大模型90%性能,大模型金字塔式信息汇聚模式探秘|开源 - 量子位的文章 - 知乎
发表日期:2024-06-04
GitHub 仓库:https://github.com/Zefan-Cai/PyramidKV
简要介绍:对不同 Transformer 层采用不同的 kv cache 压缩设置,底层尽量都保留,高层仅保留关键 token 的 kv cache。
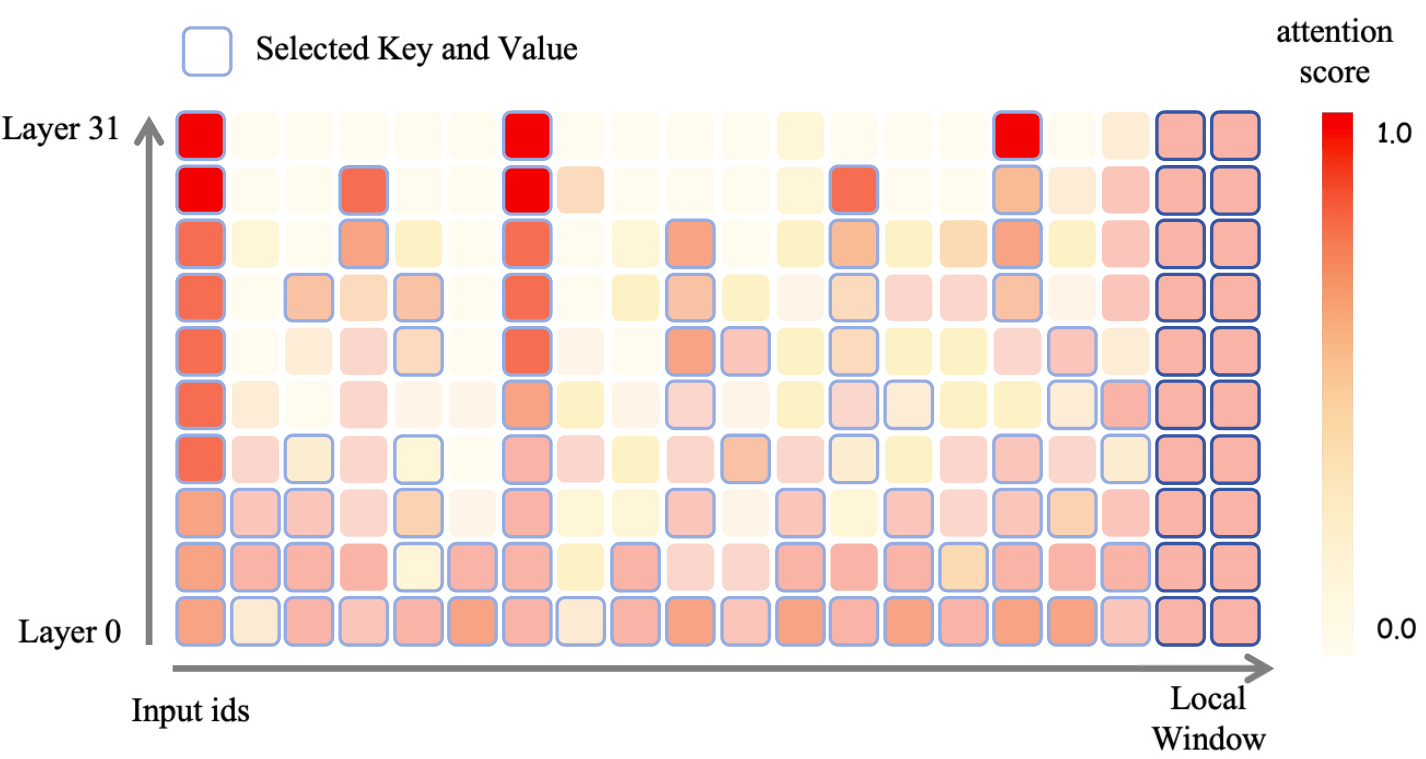
发表日期:2024-06-13
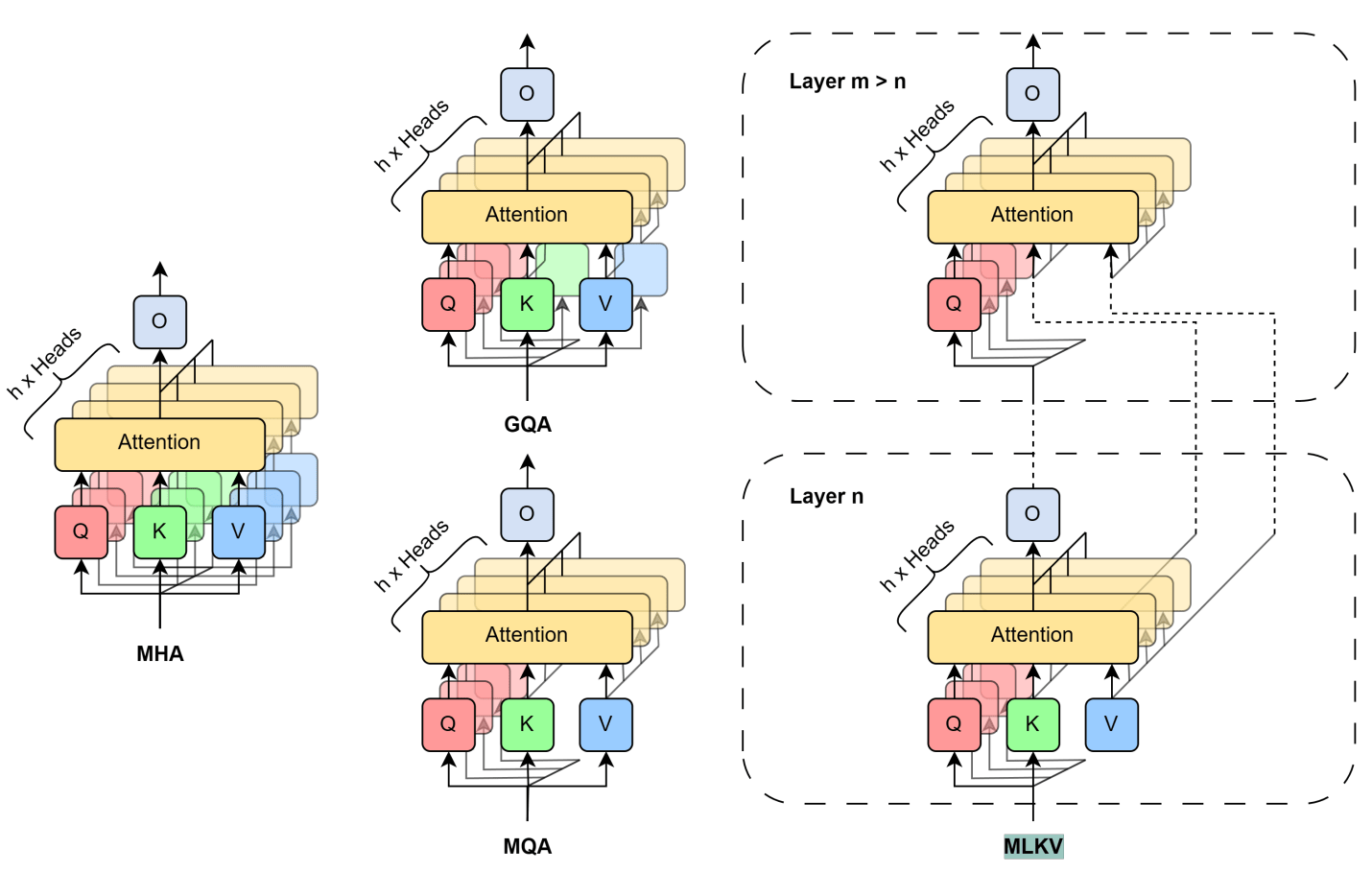
GitHub 仓库:https://github.com/zaydzuhri/pythia-mlkv
简要介绍:在上文的调整注意力机制一节中提到了 CLA,一种跨层共享 Attention 的机制。无独有偶,kv cache 也可以有同样的思路。通过跨层共享 kv cache 来减少内存占用量。