提示工程(Prompt Engineering)关注提示词开发和优化,帮助用户将大语言模型(Large Language Model,LLM)用于各场景和研究领域。
prompt 为人类与通用模型(如 LLM)的交互和使用提供了一个自然和直观的界面。由于其灵活性,prompt 已被广泛用作 NLP 任务的通用方法。然而,LLMs 需要细致的 prompt 工程,无论是手动还是自动,因为模型似乎不能像人类那样理解 prompt。尽管许多成功的 prompt 调整方法使用基于梯度的方法在连续空间上进行优化,但随着规模的扩大,这变得不太实际,因为计算梯度变得越来越昂贵,对模型的访问转向可能不提供梯度访问的 API。
窃以为人类与 LLM 的交互无非两种,人类主动去配合 LLM,找出与 LLM 沟通的有效方式;另一种是 LLM 去配合人类,学会人类的沟通方式和行为习惯。前者是 prompt 工程,后者是 SFT 和 RLHF。在以完成业务目标的前提下,两者没有优劣之分,不可尊一贬一。
SFT + RLHF 的道路是已经被证实可走通,例如 OpenAI 的 GPT 系列,以及最近一石惊起千层浪的 DPO、PPO,代表性模型 zephry、starling-LM。往该方向发展无可厚非,也是必经之路,必须得有相关的积累和认知。然而,认为 prompt 工程不是算法工程师的工作,prompt 工程是没有资源时做的工作,我认为有失偏颇。并非所有的业务都会有自研模型,都需要训练模型,都有适配业务场景的训练数据,很多时候往往是调用第三方 API,我们能做的只有调整 prompt,例如 B 端的大多业务,以及记忆点服务、会话摘要标题生成功能等等。在这些业务场景下,因为我们无法去更改调用的模型,效果的好坏很大程度上取决于 prompt 的质量。
论证研究
研究:prompt 顺序、格式的影响
- Calibrate Before Use:Improving Few-Shot Performance of Language Models:few-shot 学习可能是不稳定的,prompt 格式的选择、训练示例、甚至训练示例的顺序都会导致准确性从随机猜测到接近最先进的水平。不稳定性来自于语言模型对预测某些答案的偏向,多数标签偏差、回顾性偏差和常见 token 偏差。并提出上下文校准,一种调整模型输出概率的简单程序。
- Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity:论证了 prompt 的顺序对推断的结果有影响。
- Rethinking the Role of Demonstrations:What Makes In-Context Learning Work?:研究 demonstration 对于 ICL 成功所起到的作用。demonstration 中的 ground truth 输入-标签映射所起到的作用比想象的要小得多——用随机标签替换 gold 标签,只稍微降低了性能。收益主要来自于输入空间和标签空间的独立规范(independent specification);使用正确的格式,模型可以通过只使用输入或只使用标签集来保持高达 95% 的性能收益;带有语境学习目标的元训练会放大这些趋势。
研究:context 位置研究
- Lost in the Middle: How Language Models Use Long Contexts:模型更善于使用出现在上下文开头(首要偏差)和结尾(回顾偏差)的相关信息,而当被迫使用输入上下文中间的信息时,性能就会下降。并且用实验证明,在使用输入上下文方面,扩展上下文模型并不一定比非扩展上下文模型更好。
研究:In-Context Learning
- Understanding In-Context Learning from Repetitions:这篇论文对表面特征在文本生成中的作用进行了定量研究,并根据经验确定 token 共现强化的存在,任何两个 token 构成一个 token 强化循环,在该循环中,任何两个 token 都可以通过多次重复出现而形成紧密联系。这是一种基于上下文共现强化两个 token 之间关系的原理。
具体实现
prompt 优化
prompt 优化分为调整 context,或者在 context 中添加更多的信息,例如错误的信息、或者从错误信息中抽取到的思考、原则等辅助信息,也可以是通过检索得到的世界性知识或者专属知识。
方式:调整 context
添加更多的信息
往 context(prompt)中添加 few-shot 示例、错误的信息(或者从错误信息中抽取得到的思考、原则等辅助信息)。这部分更多与 RAG 结合使用。
2021-01:What Makes Good In-Context Examples for GPT-3?:提出 KATE 方法,根据测试样本与训练集相似度挑选最佳邻居作为上下文示例。
2021-10:Generated Knowledge Prompting for Commonsense Reasoning:提出生成知识提示,包括从语言模型中生成知识,然后在回答问题时将知识作为额外输入。
理解改进:将生成知识单独拆分出来,作为填充知识库内容会更好,因为我们无法保证语言模型中生成的知识是否有幻觉,需要通过一系列的方式进行过滤和处理。在回答问题时,通过 RAG 的方式检索高质量的知识作为额外输入可有效减少幻觉和冗余信息的影响。
结合业务:可通过爬虫或者询问 GPT-4,来丰富现有 joyland 角色的人设,填充更多的信息,后续可通过 RAG 的方式动态拼接人设 prompt。
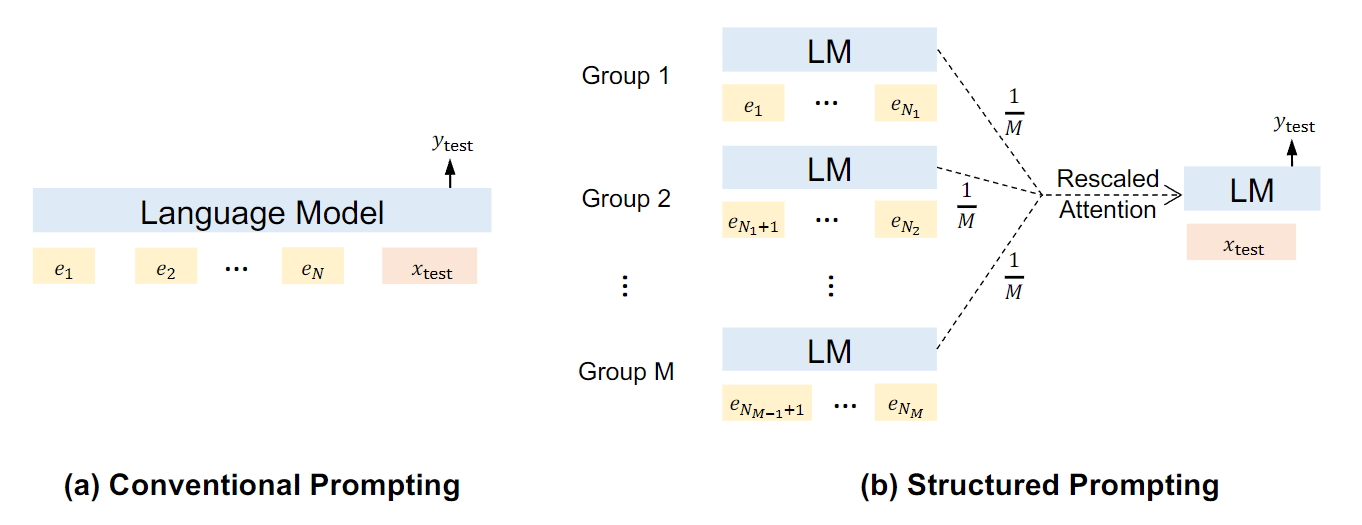
2022-12:Structured Prompting:Scaling In-Context Learning to 1,000 Examples:探索了如何利用更多的示例来进行语境学习,并提出了结构化 prompt,以在有限的计算复杂度下扩大示例的数量。对每组演示进行独立编码,并通过 rescaled attention 对语言模型的表征进行 prompt。
2023-11:Chain-of-Note:Enhancing Robustness in Retrieval-Augmented Language Models:介绍了一种新颖的方法 CHAIN-OF-NOTING(CoN)框架,核心理念是为每个检索到的文档生成连续的阅读笔记,以深入评估文档与所提问题的相关性,并整合这些信息来形成最终答案。
2023-11:Thread of Thought Unraveling Chaotic Contexts
:从人类的认知过程中汲取灵感,推出了“Thread of Thought”(ThoT,思维线索)策略。ThoT 首先通过在 prompt 后加上“Walk me through this context in manageable parts step by step, summarizing and analyzing as we go”得到核心概要信息(初始化推理);然后将核心概要信息添加到 prompt 末尾去得到真正的 answer(强化结论)。2024-02:In-Context Principle Learning from Mistakes:引入了学习原则(LEAP)。首先,有意诱导模型在这几个示例上犯错误;然后,模型本身会对这些错误进行反思,并从中学习明确的特定任务“原则”,这些原则有助于解决类似问题并避免常见错误;最后,提示模型使用原始的 few-shot 示例和这些学到的一般原则来回答未见过的测试问题。
过滤冗余或错误信息
- 2023-05:Deliberate then Generate: Enhanced Prompting Framework for Text Generation:提出 DTG 提示方法,通过让模型在可能包含错误的合成文本上检测错误类型,鼓励 LLM 在生成最终结果之前进行深思熟虑。
- 2023-11:System 2 Attention (Is Something You Might Need Too):通过诱导 LLM 重新生成输入上下文,使其只包含相关部分;然后再关注重新生成的上下文,以诱导出最终良好的响应。
方式:prompt 压缩
prompt 压缩可以缩短原始 prompt,同时尽可能保留最重要的信息。这可以减少模型推理阶段的 prefill 时间,并过滤掉 context 中冗余、错误的信息,帮助生成更为准确的回复。本质上也是调整 context,但还是将其另成一派。
可行性结论:
- 语言中常常包含不必要的重复,且无意义的内容,例如在传统 NLP 中,我们时常会去停用词,因为这些停用词没有太多的语义或者对模型输出结果几乎没有影响。
- 《Prediction and entropy of printed English》表明,英语在段落或章节长度的文本中有很多冗余,大约占 75%。这意味着大部分单词可以从它们前面的单词中预测出来。
疑问:
- prompt 被压缩后,后面位置的 token 其位置编码会相应变化,例如第 500 位置的 token 压缩后到了 200 位置,虽然它在 500 位置处的信息量或者 logits 对结果没有影响,但到了 200 位置是否就变得重要了呢?
- RLHF 对齐越好的模型,是否对 prompt 压缩越敏感?压缩后的 prompt 几乎人类不可读,与人类喜好对齐强的模型是否也不容易理解?在一篇讲述 Pinecone 搜索方案的博客中将压缩后的 prompt 送入 gpt-4-1106-preview,它会返回文章的格式和用词写法错误,但在 gpt-3.5-turbo 中就不会出现。
相关方法
自动压缩机(AutoCompressors)
2023-04:Unlocking Context Constrainits of LLMs:Enhancing Context Efficiency of LLMs with Self-Information-Based Content Filtering:引入了“选择性上下文”(Selective Context 技术),通过过滤掉信息量较少的内容,为 LLM 提供了一种更紧凑、更高效的上下文表示法,同时又不影响它们在各种任务中的性能。
2023-10:LLMLingua:Compressing Prompts for Accelerated Inference of Large Language Models:提出了一种从粗到细的提示压缩方法 LLMLingua,包括一种在高压缩率下保持语义完整性的预算控制器、一种能更好地模拟压缩内容间相互依存关系的 token 级迭代压缩算法,以及一种基于指令调整的语言模型间分布对齐方法。
方式:优化指令
以人的行为习惯、思维方式写下的 prompt 往往能达到及格分,经验丰富老道的提示工程师或许可以在第一步就写出达到 80 分的 prompt。但无论如何,人写下的 prompt 很难跳出人类的思维方式,我们会尽可能将话语和文字组织得通顺连贯、行文结构合理,偶尔捎带些许有趣性,但这并不一定是最符合模型的思考习惯。例如模型的对齐能力是否会有影响?对齐能力强的模型更能理解人的语言,即使低质量的 prompt 也能执行得好,例如 GPT4),我们可以不强求非得以人的视角写出符合人类习惯的 prompt,让模型自己去生成自己能更好理解的 prompt,似乎是一个更好的方向。
- 2022-03:An Information-theoretic Approach to Prompt Engineering Without Ground Truth Labels:介绍了一种选择 prompt 的方法,在一组候选 prompt 中,选择使输入和模型输出之间的互信息最大化的 prompt。
- 2022-11:Large Language Models Are Human-Level Prompt Engineers:提出了 APE(自动 prompt 工程师)框架,根据问题和回答让 LLM 自动生成指令,然后再用 LLM 去评估生成指令的质量,从中挑选效果最好的指令。此外,可以根据蒙特卡洛法去检索更好的指令集并减少迭代的计算成本。
- 2023-02:Active Prompting with Chain-of-Thought for Large Language Models:将主动学习的过程应用到 prompt 工程上,主要是流程和工程上面的改进,制定不确定性标准,例如分歧、熵、方差和置信度来评估 prompt 在特定任务上的效果。选择这些效果不佳的 prompt,交给人工去标注,最后进行推断。不断重复上述过程,与主动学习的过程相同。
方式:定向刺激
2023-02:Guidling Large Language Models via Directional Stimulus Prompting:提出了一个名为“定向刺激 prompt”(Directional Stimulus Prompting)的新型 prompt 框架,先训练一个经过微调、强化学习后的小型模型,然后使用该小型模型根据用户的查询来生成对应的刺激(文本),将其添加到 prompt 中来引导黑盒大语言模型朝着所需的输出方向前进。
2023-07:EmotionPrompt:Leveraging Psychology for Language Models Enhancement via Emotional Stimulus:作者从心理学中汲取灵感,提出 EmotionPrompt(情感提示)来探索情商,以提高 LLM 的性能。具体来说,作者为 LLMs 设计了 11 句情感刺激句子,只需将其添加到原始 prompt 中即可。缺陷在于情绪刺激可能并不适用于其他任务,并且对不同 LLM 的效果无法保证。
在次日留存率时期,该方法效果不佳,很大程度上源于模型较“笨”,只会输出又长又黄的回复,对用户的指令都无法很好地理解,更不用说上下文中的情感提示与刺激。2024-02-20 日之后的模型可以尝试用该方法。
连续推理
将中间的推理步骤一步步思考完整,或者将一整个问题逐步分解成子问题来解决。核心在于需要执行多次或多跳来完成任务。
方式:CoT 与类 CoT 大家族
CoT 一系列研究,给我的感觉像是将数据结构中的链表、树和图依次应用到 CoT 中。
2022-02:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models:提出了思维链(CoT)的方法。
2022-03:Self-Consistency Improves Chain of Thought Reasoning in Language Models:提出了自我一致性方法,先使用思维链 prompt,然后通过采样等手段获取多条输入,汇总答案(根据投票以及加权等方式),并选择最一致的答案。该方法受限于固定的答案集,并且计算成本较高(多条输出、推理路径)。但在算术和常识推理任务上能够提高准确性。
理解改进:核心在于如何选择最一致的答案,在开放式闲聊场景中,使用奖励模型来评分是一个不错的方式,例如生成多条回复,让奖励模型打分,挑选分数最高的回复。
2023-05:Tree of Thoughts:Deliberate Problem Solving with Large Language Models:还未细看。
2023-06:RCoT:Detecting and Rectifying Factual Inconsistency in Reasoning by Reversing Chain-of-Thought:提出 RCoT 方法,首先要求 LLM 根据生成的解决方案(响应)重构问题。然后,将原始问题和重构问题进行细粒度拆分,并进行比较,从而发现原始解决方案中的事实不一致之处(条件忽略、幻觉、问题曲解等问题)。最后利用检测到的不一致来指导 LLM 修正原先的解决方案(响应)。
该方法与 APO 优化 prompt 类似,都是从输出中找出问题,然后根据问题去修正结果。区别在于,APO 是修正 prompt;RCoT 是修正原先的输出,期望得到正确的输出。
2023-08:Better Zero-Shot Reasoning with Role-Play Prompting:提出了一种由两阶段框架组成的新型 zero-shot role-play 提示方法,旨在增强 LLM 的推理能力。实验结果凸显了 role-play 提示作为一种隐性和有效的 CoT 触发器的潜力,从而提高了推理结果。
方式:问题拆分
- 2022-10:Measuring and Narrowing the Compositionality Gap in Language Models:提出了 self-ask 的方式,不断将复杂、多跳问题拆分为子问题,然后依次解决子问题,最后回答完整问题。在解决子问题的过程中,可借助搜索引擎来获取事实性知识。
- 2022-10:ReAct: Synergizing Reasoning and Acting in Language Models:提出了 ReAct 框架。
- 2023-06:Let’s Verify Step by Step:在数学推理领域,过程监督可以用来训练比结果监督更可靠的奖励模型。主动学习可以用来降低人类数据收集的成本。
偏见
LLMs 可能会产生带有问题的生成结果,这些结果会对模型在下游任务上的性能产生负面影响,并显示可能会恶化模型性能的偏见。其中一些可以通过有效的 prompt 策略来缓解,但可能需要更高级的解决方案,如调节和过滤。
在 《Calibrate Before Use:Improving Few-Shot Performance of Language Models》论文中提到“方差在更多的数据和更大的模型中持续存在”,而造成高方差的原因是 LLMs 中存在的各种偏差(偏见),例如:
- 在 prompt 中经常出现的答案(多数标签偏差)。
- 在 prompt 的最后(回顾性偏差)。
- 在预训练数据中常见的答案(常见 token 偏差)。
多数标签偏差
当一个类别更常见时,GPT-3 会严重偏向预测该类别,本质是多数标签严重影响模型预测分布,从而对准确性造成很大影响。
理解:1-shot 时,模型预测很大程度上受到这一个训练示例标签的影响,从而输出该训练示例的标签,而非期望得到的标签。
回顾性偏差
模型的多数标签偏差因其回顾性偏差而加剧:重复出现在 prompt 结束时的答案的倾向。例如,当两个负例出现在最后,模型将严重倾向于负面的类别。
回顾性偏差也会影响到生成任务。对于 4-shot 的 LAMA,更接近 prompt 结束的训练答案更有可能被模型重复。总的来说,回顾性偏差与多数标签偏差一样,都会影响模型预测的分布。
例如,joyland 模型重复问题,很大程度上由于 context 中存在大量重复的回复,尤其是最近几轮相近或相同的回复,加上对话的 prompt 组织格式形似 ICL,这进一步加重回顾性偏差,从而导致当前轮模型回复继续重复。详细研究请参考 Rethinking Historical Messages。
常见 token 偏差
模型倾向于输出预训练分布中常见的 token,而这可能对下游任务的答案分布来说是次优的。在 LAMA 事实检索数据集上,模型常常预测常见的实体,而 ground truth 的答案却是罕见的实体。在文本分类中也出现了更细微的常见token偏差问题,因为某些标签名称在预训练数据中出现的频率较高,所以模型会对预测某些类别有固有偏见。总的来说,常见 token 偏差解释了标签名称的选择对于模型预测的重要性,以及为什么模型在处理罕见答案时会遇到困难。
相关工具
| 名称 | 链接 |
|---|---|
| awesome-chatgpt-prompts-zh | https://github.com/PlexPt/awesome-chatgpt-prompts-zh |
| snackprompt | https://snackprompt.com/ |
| flowgpt | https://flowgpt.com/ |
| prompthero | https://prompthero.com/ |
| publicprompts.art | https://publicprompts.art/ |
| guidance | https://github.com/guidance-ai/guidance |
| Synapse_CoR | https://github.com/ProfSynapse/Synapse_CoR |
| PromptInject | https://github.com/agencyenterprise/PromptInject |
参考资料
- 工程指南:https://www.promptingguide.ai/zh
- prompt 学习:https://learningprompt.wiki/



