FlashAttention V1 学习笔记
博客的数学公式显示有些许问题,更佳的阅读体验请参阅 https://www.wolai.com/voY74vy53rt6bwrMBzEDDU 。
Flash Attention 是一种新型的注意力机制,旨在解决传统 Transformer 模型在处理长序列数据时面临的计算和内存效率问题。它通过一系列创新的技术优化,显著提高了注意力机制的计算速度和内存使用效率,同时保持了精确的结果,不依赖于近似计算。
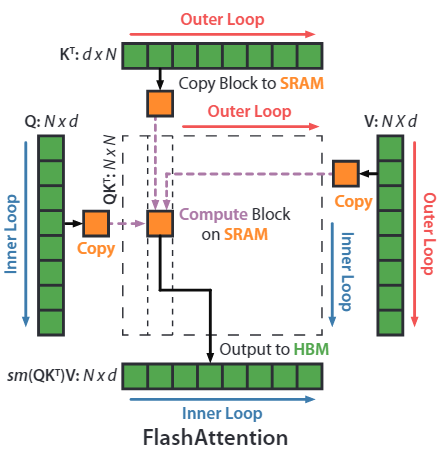
背景&动机当输入序列较长时,Transformer 的计算过程缓慢且耗费内存,这是因为 self-attention 的时间和内存复杂度会随着序列长度的增加而呈二次增长。标准 Attention 计算的中间结果 S, P(见下文)通常需要通过 HBM 进行存取,两者所需内存空间复杂度为$O(N^2)$。
$$self-attention(x) = softmax(\frac{Q K^T}{\sqrt{d}})\cdot V$$
$$S = \frac{Q K^T}{\sqrt{d}}, \quad P = softmax(S)$$
在不考虑 bat ...
ConvRAG:通过细粒度检索增强和自我检查提升大模型对话式问答能力
论文地址:https://arxiv.org/pdf/2403.18243.pdf
文章链接:https://mp.weixin.qq.com/s/InjLKF8lepX6hfi6W-oeMQ
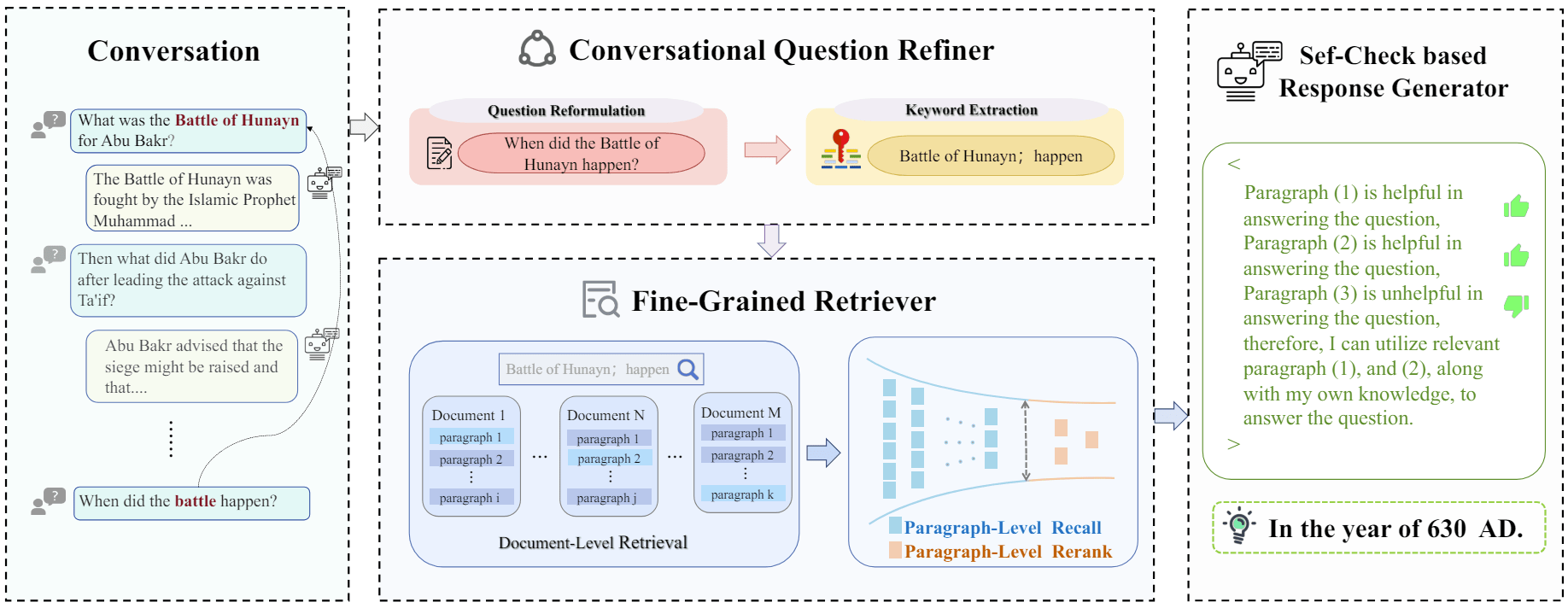
ConvRAG 是一种对话式问答方法,通过细粒度检索增强和自我检查机制提升 LLM 在对话环境中的问题理解和信息获取能力。
文章介绍了一种名为 ConvRAG 的新型对话式问答方法,旨在增强 LLMs 的对话问答能力。ConvRAG 通过结合细粒度检索增强和自我检查机制,解决了以往 RAG 方法在单轮问答中的局限性,并将其成功适应于复杂的对话环境(问题与之前的上下文相互依赖)。
ConvRAG 的核心在于三个关键组件的协同工作:
对话式问题精炼器:通过问题重构和关键词提取,使问题意图更加明确,以便更好地理解与上下文相关联的问题。
细粒度检索器:利用问题重构和关键词从网络中检索最相关的信息,以支持响应生成。检索过程包括文档级检索、段落级召回和段落级重排,以确保获取到最有用的信息片段。
基于自我检查的响应生成器:在生成响应之前,先对检索到的信息进行自我检查,以确保使用的是有用的信息,从而提高 ...
硬件相关知识
显卡
存储体系寄存器寄存器是处理器内部非常小但极其快速的存储单元,直接嵌入在CPU核心中。它们用于存储指令、数据和地址信息,是CPU执行指令时最先访问的存储区域。寄存器的数量相对有限,但访问速度极快,几乎与CPU的运算速度一致。由于寄存器的数量和大小都很有限,它们主要用于存储当前指令执行中最为关键的数据。
片上缓存 (on-chip cache)片上缓存是一种位于 CPU 内部的 Cache(缓存)。在计算机架构中,Cache 是指一种快速的存储层,目的是存储临时指令和数据,以便于快速访问。这样 CPU 在执行任务时可以迅速获取这些信息,而不需要每次都去较慢的主内存(RAM)中读取数据。
片上缓存的主要目的是通过在CPU和主内存之间提供一个高速的临时存储区域来减少CPU访问主内存所需的时间。这种缓存通常分为几个层级(如L1、L2、L3),每个层级的大小和速度都有所不同。
L1缓存:它是最接近CPU核心的缓存,也是速度最快的缓存,但通常容量较小。L1缓存通常分为两个部分:一个用于存储指令(I-Cache),另一个用于存储数据(D-Cache)。
L2缓存:它的速度比L1慢 ...
硬件-显卡
基础概念Pinned Memory页锁内存(Pinned Memory 或 Page-locked Memory)是指在计算机系统中,物理内存中的某些页面被锁定(或固定),以防止操作系统将这些页面交换到磁盘上。这种技术在高性能计算和 GPU 编程中尤为重要,尤其是在使用 CUDA 编程时。
页锁内存的主要特点和优势
防止交换:页锁内存不会被操作系统的虚拟内存管理系统交换到磁盘上。这意味着数据始终驻留在物理内存中,避免了磁盘I/O的开销。
高效的数据传输:在 GPU 编程中(如使用 CUDA),使用页锁内存可以显著提高 CPU 和 GPU 之间的数据传输速度。GPU 设备可以直接访问页锁内存,而不需要首先将数据复制到临时缓冲区。
低延迟:由于数据不会被交换到磁盘上,访问页锁内存的数据会有更低的延迟。
页锁内存的使用场景
GPU 编程:在 CUDA 编程中,页锁内存通常用于提高主机(CPU)和设备(GPU)之间的数据传输效率。可以使用 CUDA 提供的 API 函数 cudaHostAlloc 来分配页锁内存。
实时系统:在需要低延迟和高确定性的实时系统中,页锁内存 ...
论文阅读:A Survey on Data Selection for LLM Instruction Tuning
指令调整是训练大语言模型(LLM)的重要步骤,因此如何提高指令调整的效果受到越来越多的关注。现有研究表明,在 LLM 的指令调整过程中,数据集的质量比数量更为重要。因此,进来很多研究都集中于探索从指令数据集中选择高质量子集的方法,旨在降低训练成本并增强 LLM 的指令遵循能力。本文对用于 LLM 指令调整的数据选择进行了全面研究。首先,介绍了常用的指令数据集。然后,提出了新的数据选择方法分类法,并详细介绍了最新进展,还详细阐述了数据选择方法的评估策略和结果。最后,强调了这一任务所面临的挑战,并提出了新的研究领域。
2. 指令集由 LLM 生成的各种指令调整数据集(如 Self-Instruct 和 Alpaca)无需人工即可提供丰富的样本,但其数据质量取决于 LLM 的性能,并具有不确定性。相反,人工编辑的数据集(如 LIMA 和 Dolly)通过精心的人工选择获得了更高的质量,但也可能受到人为偏见的影响。其他数据集构建方法,如即时映射(prompt mapping)和进化构建(evol-instruct),旨在提高数据集的质量和多样性,但也给质量保证带来了新的挑战。数据集构建和来源的 ...
LLM 模型参数融合
模型参数融合通常指的是在训练过程中或训练完成后将不同模型的参数以某种方式结合起来,以期望得到更好的性能。这种融合可以在不同的层面上进行,例如在神经网络的不同层之间,或者是在完全不同的模型之间。模型参数融合的目的是结合不同模型的优点,减少过拟合的风险,并提高模型的泛化能力。在实际应用中,这通常需要大量的实验来找到最佳的融合策略。
本篇文章只介绍训练完成后的不同模型的参数融合,不涉及训练过程的模型参数融合。
思路来源去年年底曾与 chatglm 的算法团队有过交流,一个令人印象深刻的论述是大模型的参数空间非常稀疏,当时 glm-130B 模型刚开源,用 3 张 RTX3090 以 int4 方式部署,推理的效果虽然相较 chatgpt 甚远,但比起 T5 也好得多,经过业务数据微调后即可投入到实际的生产业务,而非传统 NLP 的规则、模板 + 模型的生产方式。
按照 LIMA 的观点,模型的知识是在预训练期间注入,后续的 SFT 和 RLHF 是“约束”模型的输出,使其符合人类的喜好与习惯,或者学会一种表达方式。那么,错误的对齐会让模型的能力遭到破坏,训练数据的分布越是“离谱”,训练时 ...
RoPE + 位置线性内插
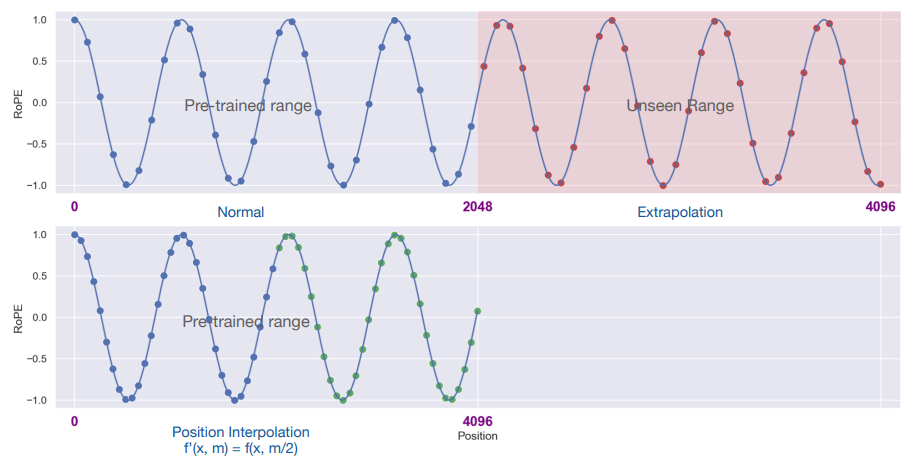
RoPE 位置编码在超出一定的序列长度后,模型生成的 PPL 指标会爆炸,因此直接外推的效果很差。Meta 的研究团队在论文《Extending Context Window of Large Models via Positional Interpolation》中提出了“位置线性内插”(Position Interpolation,PI)方案,来扩展 LLM 的 context length。
实现方式将预测的长文本位置缩放到训练长度范围以内,具体流程如下:
首先,确定推断时的序列长度;
然后计算推断时序列长度与训练时序列长度的比值,这个比值作为缩放比;
上图是关于“位置线性内插”方法的图示说明,训练时的最大序列长度是 2048,推断时扩展到 4096。
第一张图的左侧蓝色区域:这部分是 LLM 预训练的最大序列长度,蓝色点表示输入的位置索引,它们都在 0 - 2048 范围内。
第一张图的右侧粉色区域:这部分是长度外推后的区域,这些位置对于模型来说是“未见过的”,预训练期间没有得到训练。
第二张图蓝色区域:通过位置线性内插的位置,将 0 - 4096 位置区域缩放到 0 ...
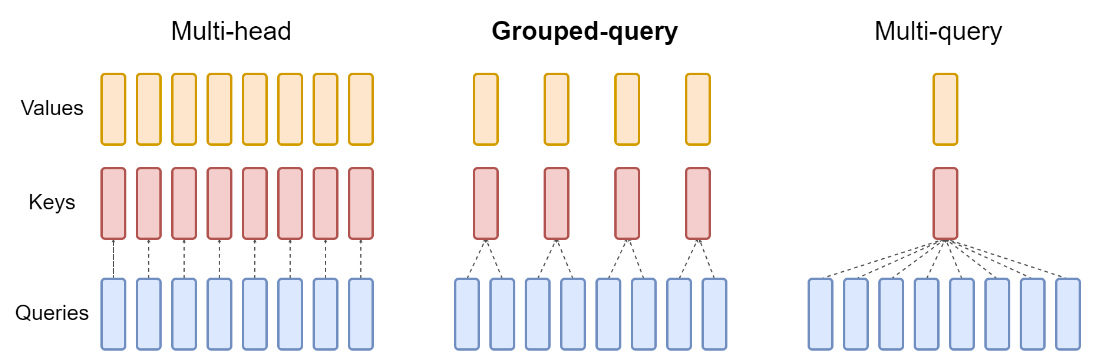
论文阅读:GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
论文链接:https://arxiv.org/abs/2305.13245
自回归解码器推理是 Transformer 模型的一个严重瓶颈,虽然现在的大模型(LLM)会通过 kv cache 存储历史 kv 信息,避免每个解码步骤重复计算,但这需要额外的内存空间,并且加大了内存带宽的开销(需要将 kv cache 从显存中加载到 GPU 的 SP)。因此,在 decoder-only 模型的推理过程中,pre-fill 阶段是 compute-bound,瓶颈在于 GPU 的计算,需要将输入的 prompt 计算 kv 信息;decode 阶段则是 memory-bound,瓶颈在于加载 kv cache,并且随着 context 的增加,解码的速度越慢。
因此,就有研究人员考虑是否可以不再是一个 query 头对应一个 key 和 value 头的 multi-head attention?于是提出了 MQA,多个 query 对应一个 key 和 value 头。我们知道 self-attention 中的主要参数权重是 Q、K、V 和 O 这四个矩阵,其中 K 和 V 的头从原先 ...
Subword 模型
在自然语言处理(NLP)的任务中,为了训练和预测,神经网络模型依赖于一个词表来表征句子。传统上,词表是通过分词处理句子并挑选出现频率最高的前 N 个词汇构建的。例如,在英文中,词汇总量通常介于 17 万至 100 万个不等。但是,基于计算效率的原因,选取的 N 值通常不能涵盖训练集中的所有单词。这种构建词表的方法会遇到几个问题:
在实际使用中,模型会遇到词表之外的新词汇(即Out Of Vocabulary, OOV),这些词汇无法被模型识别或生成;
词表中那些出现次数较少的词汇在训练时无法得到足够的训练,导致模型不能完全理解它们的语义;
由于单词的不同变形形态,如“look”可能变为“looks”,“looking”,或“looked”,尽管这些变形词意义相近,它们却被视为不同的词条,这不仅增加了训练的复杂性,也加剧了词汇量的膨胀问题。
一种解决方案是采用字符级别的词表表示,这可以解决OOV问题,但这会导致单词的语义信息丢失,并且会使模型的输入序列变得更长,从而增加了模型训练的难度和复杂性。
针对这些挑战,子词模型应运而生。它采用的分割粒度位于完整单词和单个字符之间。例如,“lo ...
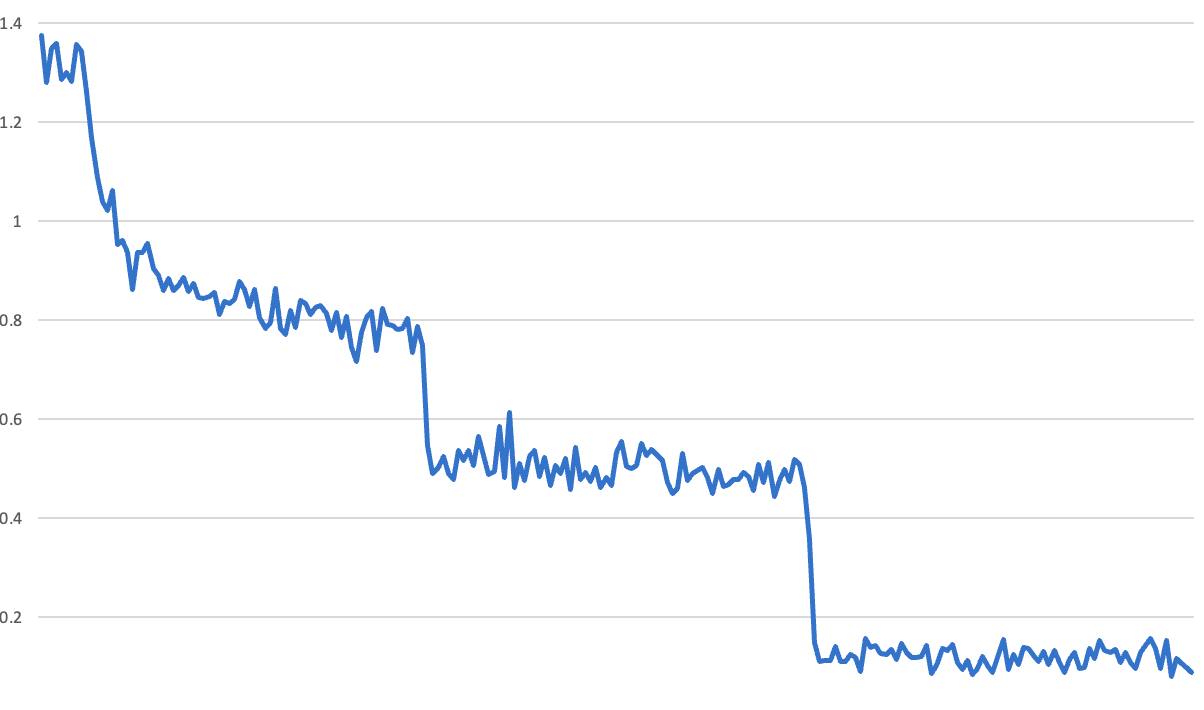
LLM 可以从简单数据中学习吗?
在 10 月份的一次周会结束后,我提到 SFT 训练后的 Loss 曲线呈现阶梯状,至于为什么,并没有人有合理的解释,加上当时的重心是提升次日留存率,Loss 曲线呈现阶梯状与次日留存率的关系还太远,即使有问题,起码次日留存率是逐渐在提升。
幸运的是,在一次逛论坛时发现了一篇博客 Can LLMs learn from a single example?,也是我这篇博客的标题名称由来,在其基础上结合了公司业务的一些现状和我个人的思考。
可以清楚地看到每个 epoch 的终点——loss 突然向下跳。我们以前也见过类似的损失曲线,但都是由于错误造成的。例如,在评估验证集时,很容易意外地让模型继续学习——这样在验证之后,模型就会突然变得更好。因此,开始寻找训练过程中的错误。
发现该“问题”的时间,恰好与单句重复问题同一时期(9 月份),于是推测是不是 context length 从 2k 变到 4k 所致,以及 Transformers 库和 RoPE 位置编码的问题。在开始逐步修改代码的同时,在 Alignment Lab AI Discord 上看到他人反馈的类似的奇怪 loss ...
分布式并行训练
先前做 NLP 相关的工作(2023 年前),主要用到的是数据并行,例如 PyTorch 的 DP 和 DDP,对 3D 略有耳闻,没有系统地学习。在从事 LLM 相关的工作后,不得不对此有所了解,无论是训练还是推理,对占用的显存有个大致的估算。
虽然在个人的笔记中记录了不少相关的内容,但本体是 吃果冻不吐果冻皮 写的知乎文章《大模型分布式训练并行技术》。我所做的无非是将其整理摘录,然后对部分不理解的地方做了一个 QA(搜索资料、或者询问 GPT-4o)。如果将其当做自己的博客,就涉及到抄袭和狗尾续貂了,所以还是直接看原文吧。
在此主要补充一些参考资料,以及后续的相关工作。
参考资料
DeepSpeed之ZeRO系列:将显存优化进行到底 - basicv8vc的文章 - 知乎https://zhuanlan.zhihu.com/p/513571706
数据并行Deep-dive: 从DP 到 Fully Sharded Data Parallel (FSDP)完全分片数据并行 - YuxiangJohn的文章 - 知乎https://zhuanlan.zhihu.com/p/48520 ...
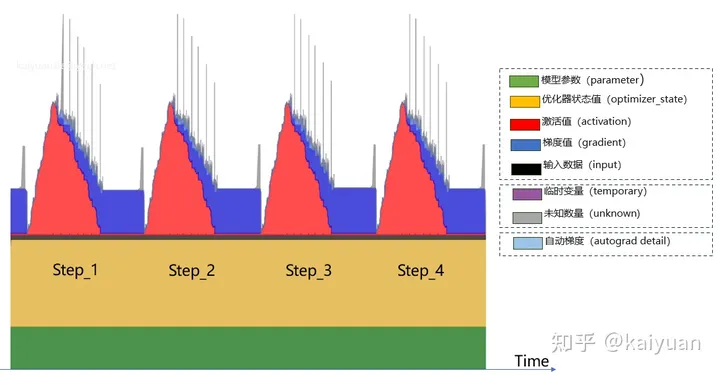
模型参数量及显存分析
当前业界主流的 LLM 大都是基于 Transformer 架构,按照结构的不同,可分为两大类:encoder-decoder(代表模型是 T5 和 PaLM)和 decoder-only(GPT 系列、Llama 系列等等)。
为了方便分析,事先定义好数学符号以及它们所代表的内容。
l(layer):模型的层数。
h(hidden size):隐藏层的维度。
ih(intermediate size):MLP 层提升的维度。
a(attention heads):注意力头数。
V(vocab size):词表大小。
如果模型符合 HugginFace Transformers 库的格式,则这些信息可以在 config.json 文件中查看。下面以 mistralai/Mistral-7B-Instruct-v0.2 为例。
123456789{ // 仅保留相关的信息 "hidden_size": 4096, "intermediate_size": 14336, "num_attention_head ...

论文阅读:Unlocking Context Constrainits of LLMs:Enhancing Context Efficiency of LLMs with Self-Information-Based Content Filtering
论文地址:https://arxiv.org/abs/2304.12102
GitHub 仓库:https://github.com/liyucheng09/Selective_Context
HuggingFace Demo:https://huggingface.co/spaces/liyucheng/selective_context
大型语言模型(LLMs)在各种任务中表现出色,因而受到广泛关注。然而,其固定的上下文长度在处理长文档或保持长时间对话时带来了挑战。本文提出了一种名为“选择性上下文”(Selective Context)的方法,利用自信息过滤掉信息量较少的内容,从而提高固定上下文长度的效率。作者在不同数据源(包括学术论文、新闻报道和对话记录)的摘要和问题解答任务中演示了该方法的有效性。
2. 自信息自信息(Self-information),又称为信息量,是信息论中的一个基本概念,它量化了一个事件所传递的信息量。在语言建模的上下文中,这里的事件是生成的一个步骤(即一个 token)。它被定义为 token 的负对数可能性:
$$I(x) = - log ...

RAG 查询检索模块 - 检索 - 混合检索
虽然向量检索有助于检索给定查询的语义相关块,但它有时在匹配特定关键字词方面缺乏准确性。
为了解决这个问题,混合检索是一种解决方案。该策略充分利用了矢量搜索和关键字搜索等不同检索技术的优势,并将它们智能地组合在一起。使用这种混合方法,您仍然可以匹配相关的关键字,同时保持对查询意图的控制。 **混合搜索的案例,可以参考Pinecone的入门指南[3]**。
Pinecone 混合检索方案该博客讨论了混合搜索的概念和实现,混合搜索结合了矢量搜索(密集检索)和传统搜索方法的优势,以提高信息检索性能,尤其是在缺乏用于微调模型的特定领域数据的情况下。
矢量搜索与传统搜索: 当使用特定领域的数据集对模型进行微调时,矢量搜索在检索相关信息方面表现出色。然而,由于缺乏经过微调的模型,矢量搜索在处理“域外”任务时显得力不从心。传统的搜索方法,如 BM25,可以处理新的领域,但在提供类似人类的智能检索方面能力有限。
混合搜索解决方案: 该博客介绍了一种将密集(向量)和稀疏(传统)搜索方法结合为混合搜索方法的解决方案。这种方法旨在利用矢量搜索的性能潜力,同时保持传统搜索对新领域的适应性。
实现过程使用支持 ...

解码策略:Speculative Sampling
GitHub 仓库:https://github.com/feifeibear/LLMSpeculativeSampling
论文地址:https://arxiv.org/abs/2211.17192
投机采样在解码过程中使用两个模型:目标模型和近似模型。近似模型是一个较小的模型,而目标模型是一个较大的模型。近似模型生成 token 猜测,目标模型纠正这些猜测。通过这种方法,可以在近似模型的输出上并行运行目标模型进行解码,从而比单独使用目标模型解码效率更高。
投机采样由 Google 和 Deepmind 于 2022 年各自提出。因此,上述 GitHub 仓库实现了两个略有不同的投机采样版本:Google 和 Deepmind 版本。
前置知识对于 LLM 如 GPT 系列的这一类 Decoder-only Transformer 架构,“推理”特指模型生成文本的过程,分为预填充和解码两个阶段。
预填充(pre-filling):并行处理输入 prompt 中的词元(token)。
解码(decoding):以自回归的方式逐个生成词元(token),每个生成的词元会被添加到输入 ...
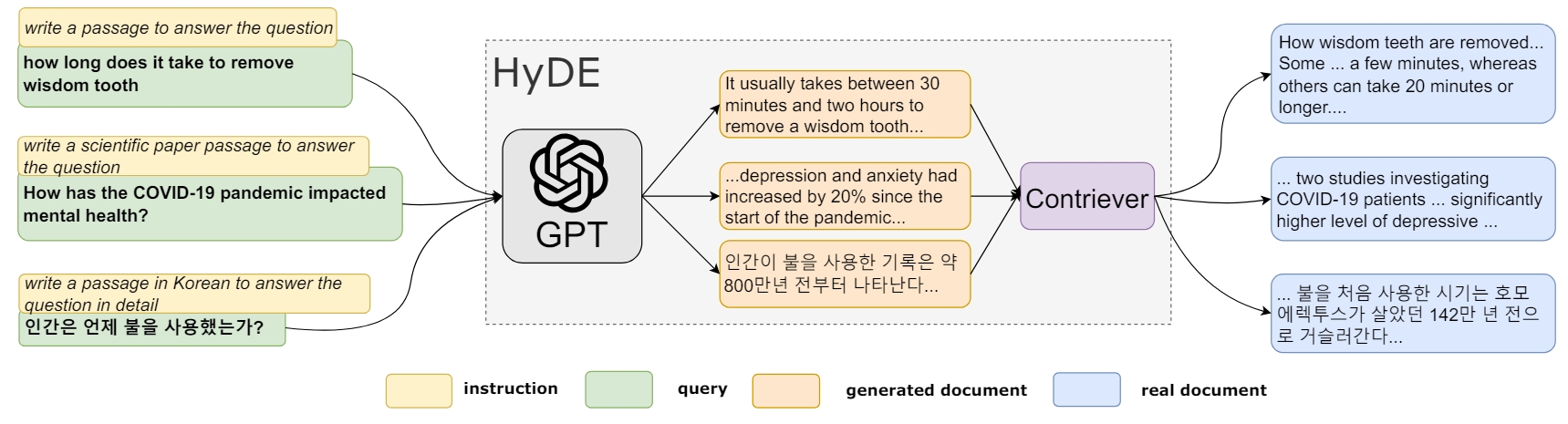
RAG 查询检索模块 - 前处理 - 查询变换
查询文本的表达方式直接影响着检索结果,微小的文本改动都可能会得到天差地别的结果。直接用原始的查询文本进行检索在很多时候可能是简单有效的,但有时候可能需要对查询文本进行一些变换,以得到更好的检索结果,从而更可能在后续生成更好的回复结果。
方法:同义改写将原始查询改写成相同语义下不同的表达方式,例如将原始查询“What are the approaches to Task Decomposition?”改写成下面几种同义表达:
123How can Task Decomposition be approached?What are the different methods for Task Decomposition?What are the various approaches to decomposing tasks?
对每种查询表达,分别检索出一组相关的文档,然后对所有检索结果进行去重合并,从而得到一个更大的候选相关文档集合。
优点:能够克服单一查询的局限,获得更丰富的检索结果集合。
缺点:如果数据库内存在冗余和噪声数据,也更容易检索出冗余和噪声的文档。
方法:查询分解有相关的研 ...
最新文章



