RAG 查询检索模块 - 后处理 - 合并挑选
在 RAG 中,“Lost in the Middle”问题相当具有挑战性。斯坦福大学和加州大学伯克利分校等大学的研究强调了这一问题,这与人们经常记住购物清单上的第一个和最后一个项目,但忘记中间的项目类似。语言模型与人一样很擅长识别他们正在分析的文本的开头或结尾的信息,但他们往往会忽略中心的关键细节。
LLM 关注开头和结尾是否和现实世界的文章相关联?现实世界的文章的重心大都也放在开头和结尾,那么在预训练期间,这些数据让模型有这种关注的趋势?
为了解决这个问题,一个常用的流程是:
避免使用单一知识库,对不同类型的文档只使用一个知识库可能会混淆检索模型。他们可能很难根据主题或上下文找到正确的信息。
使用多个向量存储,为不同类型的文档创建单独的数据存储区域(称为向量存储),这有助于更有效地组织信息。
使用一个称为 Merge Retrieve 的工具合并来自这些不同向量数据库的数据,这有助于汇集来自不同来源的相关信息。
使用长上下文重新排序,这确保了模型对文本中间的数据给予同等的关注,而不仅仅是在开头或结尾。
通过该流程,可以确保数据的所有部分,包括中间部分都得到了适当的检索,有助 ...
RAG 查询检索模块 - 后处理 - 清洗过滤
方法:专家系统根据关键字词、元数据、规则等对检索得到的内容进行清洗或过滤。
方法:过滤不相关的检索信息分享一篇从 answer 的角度来优化排序检索内容的 paper。
文章来源:LLM+RAG框架下:如何过滤掉不相关的检索信息
大体思路:
当检索到相关文本集合时,可以训练一个判断模型 $M_{ctx}$,用它来选择能支撑 query 的内容,即 $M_{ctx}(t|q, P)$,其中 q 为 query,P 为召回的相关内容集合,t 为筛选出的相关片段集合。
有了判断模型 $M_{ctx}$,利用它选择出来的相关片段集合 t 作为最终的检索内容,来支撑 $M_{gen}$ 生成,即 $M_{gen}(o|q, t)$,其中 o 为生成内容。
在上述流程中,其核心在于判断模型 $M_{ctx}$ 如何训练,其训练的监督数据如何构建。针对该问题,论文提出三种方法来构建判断模型的训练数据,即对应图中的 StrInc、CXMI、Lexical。
StrInc:String Inclusion,当 o(query 对应的 answer)完整出现在一个片段 t 中,就把这个片段召回,只 ...
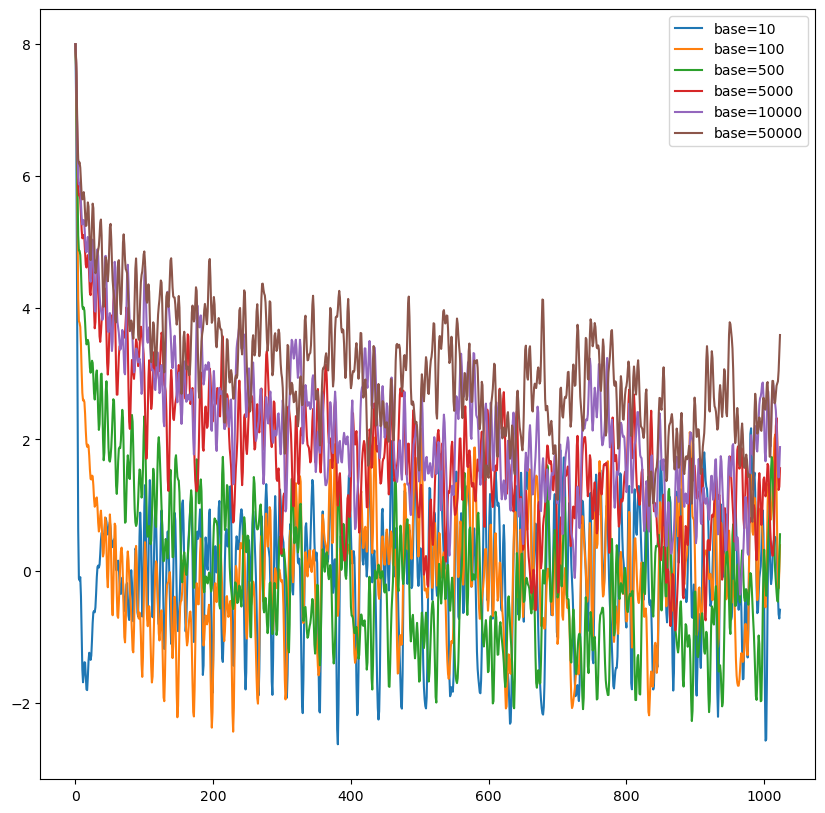
vLLM 框架:时延与吞吐的研究
注意事项:该实验是在 2024-01-05 日所作,当时所使用的 vLLM 框架版本是 v0.2.7。
读取 fastapi 部署的模型服务的日志,可以看到统计信息,如下所示:
1INFO 01-05 01:46:00 llm_engine.py:624] Avg prompt throughput: 416.3 tokens/s, Avg generation throughput: 123.8 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 5.6%, CPU KV cache usage: 0.0%
Avg prompt throughput:平均 prompt 吞吐,即 prefill 阶段的吞吐处理能力。
Avg generation throughput:平均生成吞吐,即 generate 阶段的吞吐处理能力。
查看所有的日志信息,发现线上模型服务的 KV cache usage 都相当小,甚至没有 20%,这是不是说明还能再往里面添加更多的 reqs ...
RAG 查询检索模块 - 后处理 - 重排序
重排序是指对检索得到的文档集合根据特定指标进行重新排序的过程,明确最“重要”和最“不重要”的文档,用于后续的过滤和挑选环节。
由于 cross-encoder 需要两两进行比对,当数据量较多时,编码的次数会急剧上升,编码更慢且需要更多的内容。通常,会先用 bi-encoder 进行粗筛,挑选出一部分匹配的候选项;然后,再用 cross-encoder 去重新排序候选项,得到最终的带有高精度的结果。
cross-encoder交叉编码器 cross-encoder 是一种深度神经网络,它将两个输入序列作为单个输入,同时进行编码,从而捕获了句子的表征和相关关系。与 bi-encoder 生成的嵌入(独立的)不同,cross-encoder 生成的嵌入是互相依赖的,因此允许直接比较和对比输入,以更综合和细致的方式理解它们的关系。
cross-encoder 被训练来优化分类或回归损失,而不是相似性损失。
实现方式借助 sentence-transformers 实现 cross-encoder 的执行流程。
首先,安装 sentence-transformers。
1pip i ...

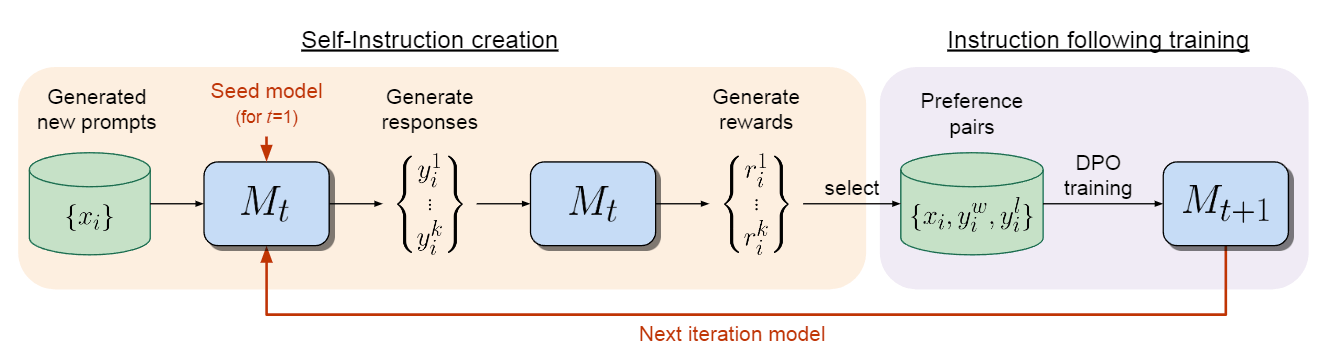
论文阅读:Self-Alignment with Instruction Backtranslation
作者提出了一种可扩展的方法,通过自动为人类撰写的文本标注相应的指令来建立高质量的指令语言模型。该方法被命名为“指令反向翻译”,首先在少量种子数据和给定网络语料库的基础上对语言模型进行微调。种子模型通过生成网络文档的指令 prompt(自我增强)来构建训练示例,然后从这些候选示例中选择高质量的示例(自我强化)。随后利用这些数据对更强大的模型进行微调。在该方法的两次迭代中对 LLaMA 进行微调,得到的模型优于 Alpaca 排行榜上不依赖蒸馏数据的所有其他基于 LLaMA 的模型,证明了高度有效的自我对齐。
方法作者的自训练方法假定可以访问基础语言模型、少量种子数据和无标签示例集合,例如网络语料库。未标注数据是人类撰写的大量不同文档,其中包括人类感兴趣的各种主题,但最重要的是没有与指令配对。
第一个关键假设:在这个庞大的人类撰写的文本中,存在一些适合作为某些用户指令黄金生成的子集。
第二个关键假设:可以预测这些候选黄金答案的指令,并将其作为高质量的示例对来训练指令遵循模型。
因此,作者称之为指令反向翻译的整个过程有两个核心步骤:
自我评估:为无标签数据(即网络语料库)生成指令,为指 ...
RoPE 相对位置编码解读与外推性研究
RoPE(Rotary Position Embedding)位置编码是大模型中最常见的位置编码之一,是论文 Roformer: Enhanced Transformer With Rotary Position Embedding 提出的一种能够将相对位置信息依赖集成到 self-attention 中并提升 transformer 架构性能的位置编码方式。谷歌的 PaLM 和 Meta 的 LLaMA 等开源大模型都是 RoPE 位置编码。
出发点在绝对位置编码中,尤其是在训练式位置编码中,模型只能感知到每个词向量所处的绝对位置,无法感知两两词向量之间的相对位置。对于 Sinusoidal 位置编码而言,这一点得到了缓解,模型一定程度上能够感知相对位置。
对于 RoPE 而言,作者的出发点:通过绝对位置编码的方式实现相对位置编码。RoPE 希望 $q_m$ 与 $k_n$ 之间的点积,即 $f(q, m) \cdot f(k, n)$ 中能够带有相对位置信息 m - n。那么如何才算带有相对位置信息呢?只需要能够将 $f(q, m) \cdot f(k, n)$ 表示成一个关于 ...
论文阅读:Self-Rewarding Language Models
作者认为,要实现超人 agents,未来的模型需要超人反馈,以提供足够的训练信号。目前的方法通常是根据人类的偏好来训练奖励模型,但这可能会受到人类水平的瓶颈制约。其次,这些单独冻结的奖励模型无法在 LLM 训练过程中学会改进。在这项工作中,作者研究的是自我奖励语言模型,即在训练过程中,语言模型本身通过 LLM 即 LLM-as-a-Judge 提示来提供自己的奖励。
研究表明,在迭代 DPO 训练过程中,不仅指令遵循能力得到了提高,而且为自身提供高质量奖励的能力也得到了提高。根据该方法对 Llama2-70B 进行三次迭代微调后,模型的性能超过了 AlpacaEval 2.0 排行榜上的许多现有系统,包括 Claude2、Gemini Pro 和 GPT-4 0613。虽然这只是一项初步研究,但这项工作为建立能在两个轴上不断改进的模型打开了一扇大门。
Self-Rewarding Language Models该方法首先假定可以访问基础预训练语言模型和少量人类标注的种子数据。然后,建立一个旨在同时具备两种技能的模型:
指令遵循:给定一个描述用户请求的 prompt,能够生成高质量、有 ...
论文阅读:Lost in the Middle: How Language Models Use Long Contexts
论文地址:https://arxiv.org/abs/2307.03172
虽然最近的语言模型能够将较长的上下文作为输入,但人们对它们使用较长上下文的效果却知之甚少。作者分析了语言模型在两项任务中的表现,这两项任务都需要识别输入上下文中的相关信息:多文档问题解答和 key-value 检索。作者发现,当改变相关信息的位置时,性能会明显下降,这表明当前的语言模型不能稳健地利用长输入上下文中的信息。特别是,作者观察到,当相关信息出现在输入上下文的开头或结尾时,性能往往最高,而当模型必须在长上下文中间获取相关信息时,性能会明显下降,即使是明确的长上下文模型也是如此。作者的分析使人们更好地了解语言模型如何使用输入上下文,并为未来的长上下文语言模型提供了新的评估协议。
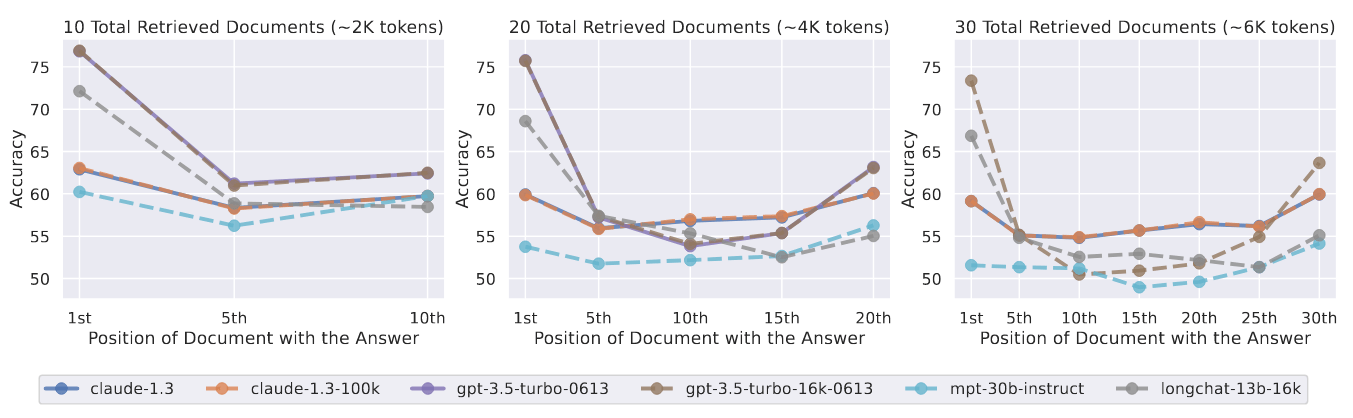
实验研究多文档 QA 实验
图 5:改变相关信息(包含答案的文档)的位置对多文档 QA 性能的影响。较低的位置更接近输入上下文的起点。当相关信息出现在上下文的最开始或末尾时,性能最高;而当模型必须对输入上下文中间的信息进行推理时,性能会迅速下降。
作者对包含 10、20 和 30 个文档的输入上下文进行了实验。图 5 显示了在 ...
资料搜集:emerging architectures for llm applications
这篇文章翻译自 https://a16z.com/emerging-architectures-for-llm-applications/,学习如何搭建一套完整的 LLM App,将其应用至当前负责的 RAG 项目中。
大型语言模型是构建软件的强大新工具。但由于它们是如此之新,而且行为方式与普通计算资源大相径庭,因此如何使用它们并不总是显而易见的。
在这篇文章中,我们将分享新兴 LLM 应用程序栈的参考架构。它展示了我们所见过的人工智能初创公司和尖端科技公司所使用的最常见的系统、工具和设计模式。这个堆栈仍处于早期阶段,可能会随着底层技术的发展而发生重大变化,但我们希望它能为现在使用 LLM 的开发人员提供有用的参考。
这项工作基于与人工智能初创公司创始人和工程师的对话。我们特别依赖以下人士提供的意见:Ted Benson、Harrison Chase、Ben Firshman、Ali Ghodsi、Raza Habib、Andrej Karpathy、Greg Kogan、Jerry Liu、Moin Nadeem、Diego Oppenheimer、Shreya Rajpal、I ...
AWS SageMaker 推理方案
总体而言,LLM 的生成推理有三大挑战(根据 Pope 等人 2022 年的研究):
由于大模型参数和解码过程中的瞬态,需要占用大量内存。这些参数往往超过单个加速器芯片的内存。注意 kv cache 也需要大量内存。
低并行性会增加延迟,尤其是在内存占用较大的情况下,每一步都需要大量数据传输来将参数和缓存加载到计算核心中。这就导致需要很高的总内存带宽来满足延迟目标。
相对于序列长度,注意力机制计算的二次方加剧了延迟和计算挑战。
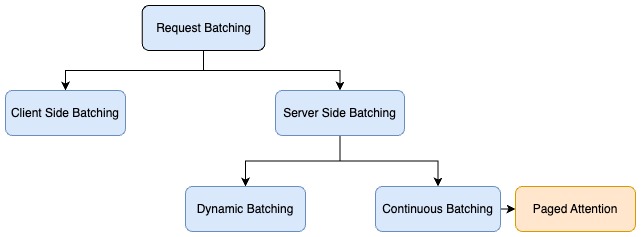
批处理是应对这些挑战的技术之一。批处理是指将多个输入序列一起发送到 LLM,从而优化 LLM 推理性能的过程。这种方法有助于提高吞吐量,因为不需要为每个输入序列加载模型参数。参数可以一次性加载,并用于处理多个输入序列。批处理有效利用了加速器的 HBM 带宽,从而提高了计算利用率,改善了吞吐量,并实现了经济高效的推理。
这篇文章探讨了如何利用批处理技术最大限度地提高 LLM 中并行化生成推理的吞吐量。作者讨论了不同的批处理方法,以减少内存占用,提高并行性,并缓解注意力的二次方,从而提高吞吐量。目标是充分利用 HBM 和加速器等硬件来克服内存、I/O ...
RTX 4090Ti 部署 7B、13B 模型的性能测评
推理速度测评实验参数:
batch_size: 1
avg num input tokens: 1719.29
stream: False
预测⽅式:接⼝预测
测试结果:
推理框架
模型
TP(模型并⾏)
Throughput(token/s)
avg num output tokens
vllm
vicuna-7b-v1.5
1
53.02
122.31
vllm
vicuna-7b-v1.5
2
40.09
121.74
vllm
vicuna-13b-v1.3
2
32.77
160.15
动态 batching 测评测试⽅式:借助 ApiFox ⼯具的⾃动化测试,循环 10 轮,每轮启动 3 个线程来调⽤模型服务。
workers
总耗时(秒)
接⼝请求耗时(秒)
平均接⼝请求耗时(毫秒)
1 x RTX4090 vicuna-7b-v1.5
1
132.325
129.96
4332
2
89.52
83.1
2770
3
70.938
63.93
2131
2 x RTX4090 vicuna-13b- ...
LLM - 推理相关资料整理
推理服务通常情况下,LLM 推理服务目标是首 token 输出尽可能快、吞吐量尽可能高以及每个输出 token 的时间尽可能短。换句话说,希望模型服务能够尽可能快地尽可能多地为用户生成文本。
常见 LLM 推理服务性能评估指标
首 token 生成时间(Time To First Token,TTFT):用户输入 prompt 后多久开始看到模型输出。这一指标取决于推理服务处理 prompt 和生成第一个输出 token 所需的时间。在实时交互中,低时延获取响应非常重要,但在离线工作任务中则不太重要。通常,不仅对平均 TTFT 感兴趣,还包括其分布,如 P50、P90、P95 和 P99 等。
生成每个输出 token 所需时间(Time Per Output Token,TPOT):生成一个输出 token 所需的时间,这一指标与用户感知模型“速度”相对应。例如,TPOT 为 100ms/token,表示每秒生成 10 个 token。
端到端时延:模型为用户生成完整响应所需的总时间。整体响应时延可使用前两个指标计算得出:时延 = (TTFT) + (TPOT) ...
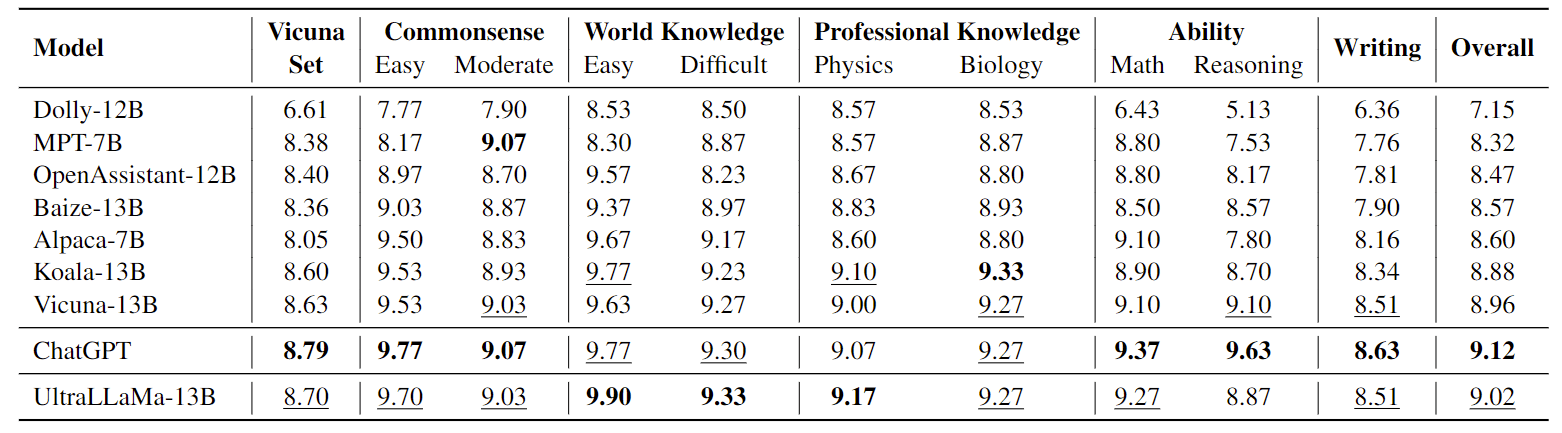
论文阅读:Enhancing Chat Language Models by Scaling High-quality Instructional Conversations 构造多轮指令对话数据集
数据集地址:https://huggingface.co/datasets/stingning/ultrachatGitHub 仓库:https://github.com/thunlp/UltraChat
对指令数据进行微调已被广泛认为是实施 ChatGPT 等聊天语言模型的有效方法。本文旨在通过构建一个系统设计的、多样化的、信息丰富的大规模指令对话数据集 UltraChat,来提高开源模型性能。UltraChat 包含 150 万条高质量的多轮对话,涵盖广泛的主题和指令。作者在 UltraChat 的基础上,对 LLaMA 模型进行了微调,从而创建了强大的会话模型 UltraLLaMA。评估结果表明,UltraLLaMA 始终优于其他开源模型,包括之前公认的最先进开源模型 Vicuna。
方法介绍与其他倾向于使用特定任务(如问题解答、改写和总结)来构建数据的数据集不同,该方法以一个三方框架为基础,旨在捕捉人类与人工智能助手可能进行的广泛交互。作者认为,人类用户与人工智能助手之间的任何互动都可视为获取信息。
信息获取:第一部分“关于世界的问题”侧重于查询世界上的现有信息。这是人机交互 ...
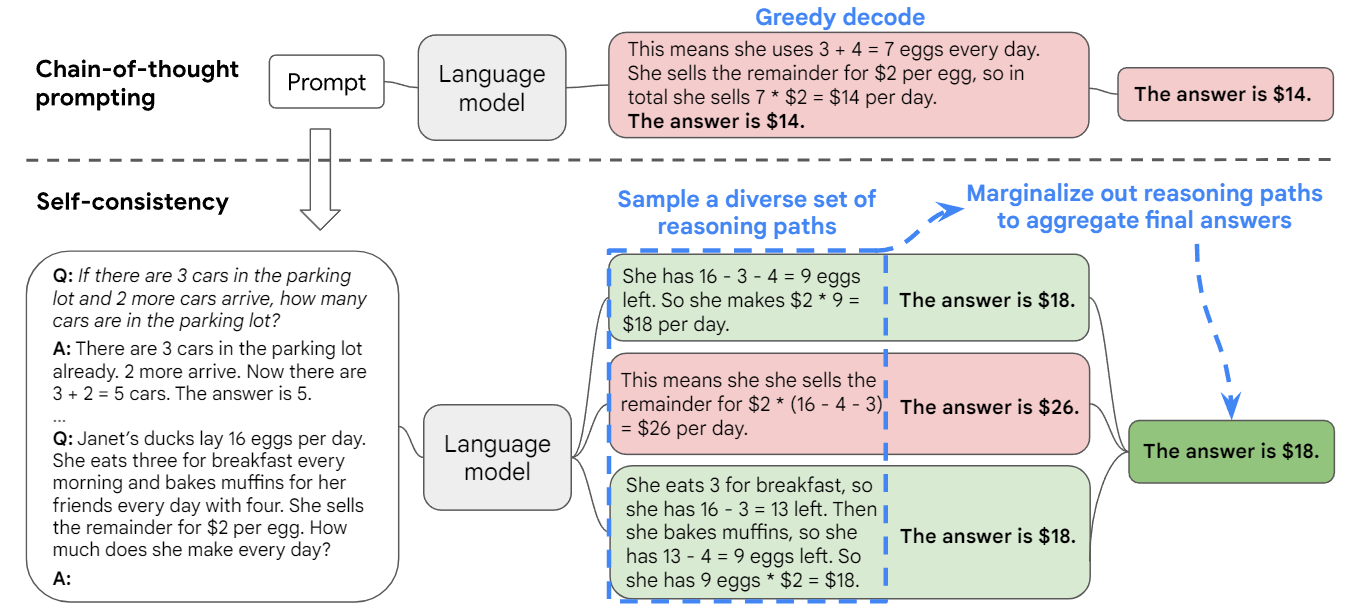
论文阅读:Self-Consistency Improves Chain of Thought Reasoning in Language Models
思维链 prompt 与预训练的大型语言模型相结合,在复杂的推理任务上取得了令人鼓舞的结果。在本文中,作者提出了一种新的解码策略,即自我一致性(self-consistency),以取代思维链 prompt 中使用的 naive 贪婪解码。它首先对不同的推理路径进行抽样,而不是只采取贪婪的推理路径,然后通过对抽样的推理路径进行边际化处理,选择最一致的答案。自我一致性利用了这样一种直觉:一个复杂的推理问题通常会有多种不同的思维方式,从而引导其唯一的正确答案。
有点类似于学生时代的考试,第一遍做题得出结果,在第二遍检查时,抛开先前的记忆重新再计算一次,看看两次的结果是否一致,如果不一致说明存在问题,那么就需要重点去思考题目的正确结果。
广泛的实证评估表明,在一系列流行的算术和常识推理基准上,自我一致性以惊人的幅度提高了思维链 prompt 的性能,包括 GSM8K(+17.9%)、SVAMP(+11.0%)、AQuA(+12.2%)、StrategyQA(+6.4%)和 ARC-challenge(+3.9%)。
不同推理路径上的自我一致性人类的一个突出方面是,人们的思维方式不同。作者 ...
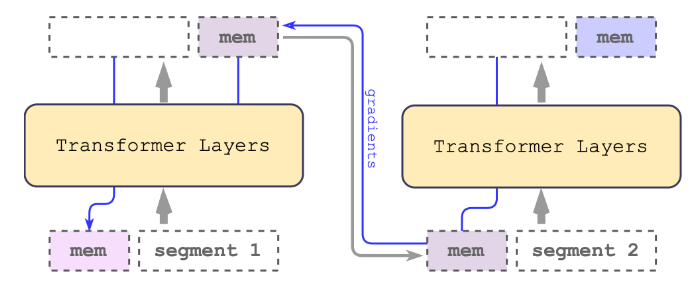
论文阅读:Scaling Transformer to 1M tokens and beyond with RMT
AI 速读Basic Information:
Title: Scaling Transformer to 1M tokens and beyond with RMT (使用RMT将Transformer扩展到100万个令牌及以上)
Authors: Aydar Bulatov, Yuri Kuratov, and Mikhail S. Burtsev
Affiliation: DeepPavlov (Aydar Bulatov), Artificial Intelligence Research Institute (AIRI) (Yuri Kuratov), London Institute for Mathematical Sciences (Mikhail S. Burtsev)
Keywords: Transformer, BERT, Recurrent Memory Transformer, long sequences, memory augmentation
URLs: https://arxiv.org/abs/2304.11062, GitHub: None
摘要 ...
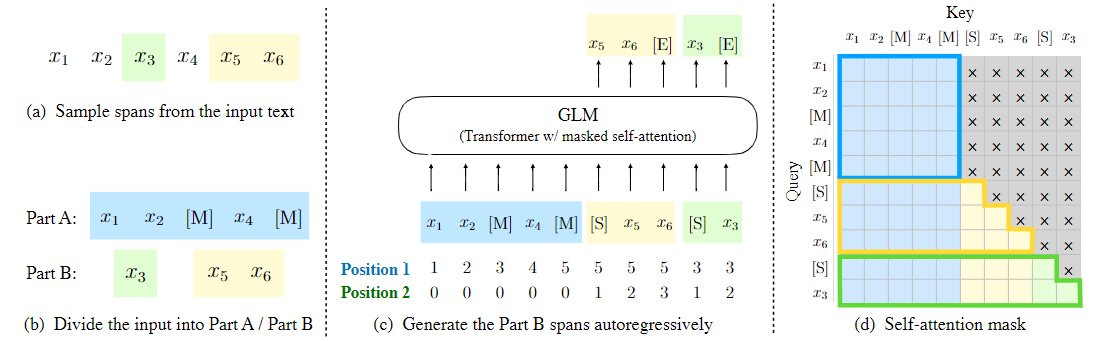
论文阅读:GLM:General Language Model Pretraining with Autoregressive Blank Infilling
已经有各种类型的预训练架构,包括自动编码模型(如 BERT),自回归模型(如 GPT),以及编码器-解码器模型(如 T5)。然而,在自然语言理解(NLU)、无条件生成和有条件生成等三大类任务中,没有一个预训练框架的表现是最好的。作者提出了一个基于自回归填空的通用语言模型(GLM)来应对这一挑战。GLM 通过增加 2D 位置编码和允许以任意顺序预测 span 来改进填空预训练,这使得 NLU 任务的性能比 BERT 和 T5 有所提高。同时,GLM 可以通过改变空白的数量和长度为不同类型的任务进行预训练。在横跨 NLU、有条件和无条件生成的广泛的任务上,GLM 在给定相同的模型大小和数据的情况下优于 BERT、T5 和 GPT,并从一个参数为 BERT-Large 1.25 倍的单一预训练模型中获得了最佳性能,证明了其对不同下游任务的通用性。
介绍在无标签文本上进行预训练的语言模型大大推进了各种 NLP 任务的技术水平,从自然语言理解(NLU)到文本生成。在过去的几年里,下游任务的表现以及参数的规模也不断增加。
一般来说,现有的预训练框架可以分为三个系列:自回归、自编码和编码器-解码器模 ...
最新文章



