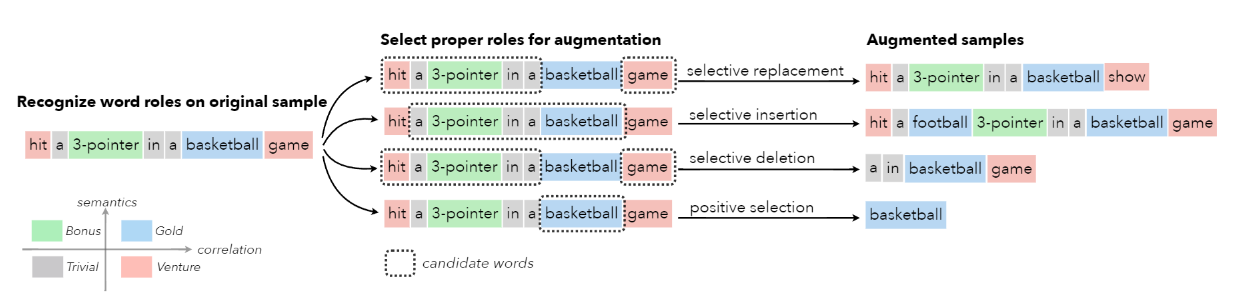
论文阅读:Selective Text Augmentation with Word Roles for Low-Resource Text Classification
数据增强技术被广泛用于文本分类任务中,以提高分类器的性能,特别是在低资源的情况下。以前的大多数方法在进行文本扩增时没有考虑文本中不同功能的词,这可能会产生不满意的样本。不同的词在文本分类中可能扮演不同的角色,这就促使我们从战略上选择适当的角色来进行文本扩增。
在这项工作中,首先从统计相关性和语义相似性的角度来识别文本中的词语和文本类别之间的关系,然后利用这些关系将词语分为四个角色–Gold、Venture、Bonus 和 Trivial,它们在文本分类中具有不同的功能。基于这些词的角色,作者提出了一种新的增强技术,称为STA(Selective Text Augmentation),其中不同的文本编辑操作被选择性地应用于具有特定角色的词。
STA 可以生成多样化和相对干净的样本,同时保留了原始的核心语义,而且实现起来也相当简单。在 5 个基准的低资源文本分类数据集上进行的大量实验表明,由 STA 产生的增强样本成功地提高了分类模型的性能,大大超过了以前的非选择性方法。跨数据集实验进一步表明,与以前的方法相比,STA 可以帮助分类器更好地推广到其他数据集上。
方法词语角色识别词语角色假设 ...
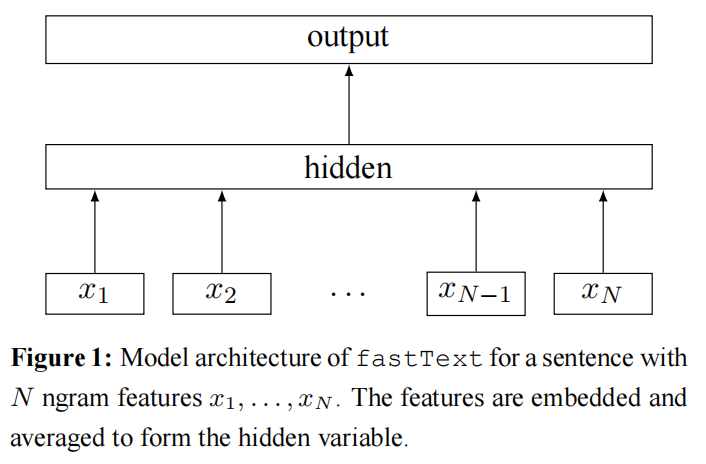
论文阅读:Bag of Tricks for Efficient Text Classification
速读Q1:论文试图解决什么问题?作者在文本分类背景下,探讨如何将基线扩展到具有大型输出、且语料库非常庞大的场景。简而言之,相比深度神经网络的训练与推测时间较长,作者希望能够扩展一些架构简单的文本分类器,使其能够近似或达到深度神经网络的性能,并且架构简单的文本分类器的资源耗费较少、训练速度更快。
Q2:论文中提到的解决方案之关键是什么?
作者提出了一个新的模型架构,类似于 Mikolov 等人的 cbow 模型,区别在于该模型架构预测句子的标签,而非中间位置的词语。
借助层次化 softmax 来降低时间复杂度。
使用 N-gram 特征来捕捉一些本地词序的局部信息。
Q3:代码有没有开源?https://github.com/facebookresearch/fastText
Q4:这篇论文到底有什么贡献?作者提出了一个简单的文本分类基线方法——fastText。
介绍在这项工作中,作者探讨了在文本分类背景下,如何将这些基线扩展到具有大型输出场景的非常大的语料库。受近期高效词表征学习工作的启发(Efficient Estimation of Word Representations ...

论文阅读:Albert:A Lite Bert for self-supervised learning of language representations
发布日期:Sep 2019
发布期刊:
作者列表:ZhenZhong Lan、Mingda Chen、Sebastian Goodman、Kevin Gimpel、Piyush Sharma、Radu Soricut
论文链接:https://arxiv.org/abs/1909.11942
速读Q1:论文试图解决什么问题?针对目前预训练模型规模越来越大、训练时间越来越久的现状,作者提出了一个新的模型 Albert,在减少模型参数量的同时,却能够在 GLUE 等评估基准上达到并超过当前最佳。
Q2:论文中提到的解决方案之关键是什么?作者提出了两种减少参数的技术,来降低模型占用的内存量、并提高模型的训练速度:
因式分解嵌入参数
跨层参数共享
此外,作者还提出了一种自监督的 loss——SOP,用以替代原始 BERT 中的 NSP 任务。SOP 着重于对句子间的连贯性进行建模。
Q3:代码有没有开源?https://github.com/google-research/albert
Q4:这篇论文到底有什么贡献?
提出了一个新的 BERT-like 架构,该架构采用了因式分解嵌入参 ...

论文阅读:Revealing the Dark Secrets of BERT
速读Q1 论文试图解决什么问题?基于 BERT 的架构在许多 NLP 任务上表现出最先进的性能,作者想探知促使其成功的底层机制。在本篇论文中,作者主要针对 self-attention 做了一系列的研究。
常见的注意力模式是什么,它们在微调过程中是如何变化的,以及这对特定任务的表现有何影响?
哪些语言知识被编码在经过微调的 self-attention 权重中,哪些部分来自预训练?
不同注意力头的 self-attention 模式有多大不同,它们对特定任务的重要性如何?
Q2 这是否是一个新的问题?不是一个新的问题。
Q3 论文中提到的解决方案之关键是什么?为每一层的每一个注意力头提取 self-attention 权重,这生成了一个形状为 L x L 的二维浮点数组,其中 L 是输入序列的长度。作者将这种二维数组称为 self-attention map。通过观察 self-attention map 来研究 self-attention 机制。
Q4 这篇论文到底有什么贡献?
提出了一套分析 BERT self-attention 的方法,并首次详细分析了 BERT 通过在 ...
论文阅读:RoBERTa: A Robustly Optimized BERT Pretraining Approach
本篇论文研究 BERT 预训练过程,仔细测量许多关键超参数和训练数据大小对模型性能的影响,作者发现 vanilla BERT 的训练不够充分,并提出了一个改进的训练 BERT 模型的配方,称之为 RoBERTa。
作者的修改很简单,它们包括:
在更多的数据上用更大的 batch_size 对模型进行更长时间的训练。
删除 NSP 任务。
在更长的序列上进行训练。
动态地改变应用于训练数据的 mask 方式。
训练过程分析本节探讨并量化哪些选择对预训练 BERT 模型有着较高的重要程度。作者保持模型架构的固定。具体来说,首先训练 BERT 模型,其配置有 $BERT_{BASE}$ 相同(L = 12,H = 768,A = 12,110M 参数)。
静态 mask VS 动态 maskVanilla BERT 在数据预处理过程中进行了一次 mask,结果是一个单一的静态 mask。为了避免在每个 epoch 中对每个训练数据使用相同的 mask,训练数据被重复了 10 次,因此在 40 个 epoch 中,每个序列被以 10 种不同的方式进行 mask ...
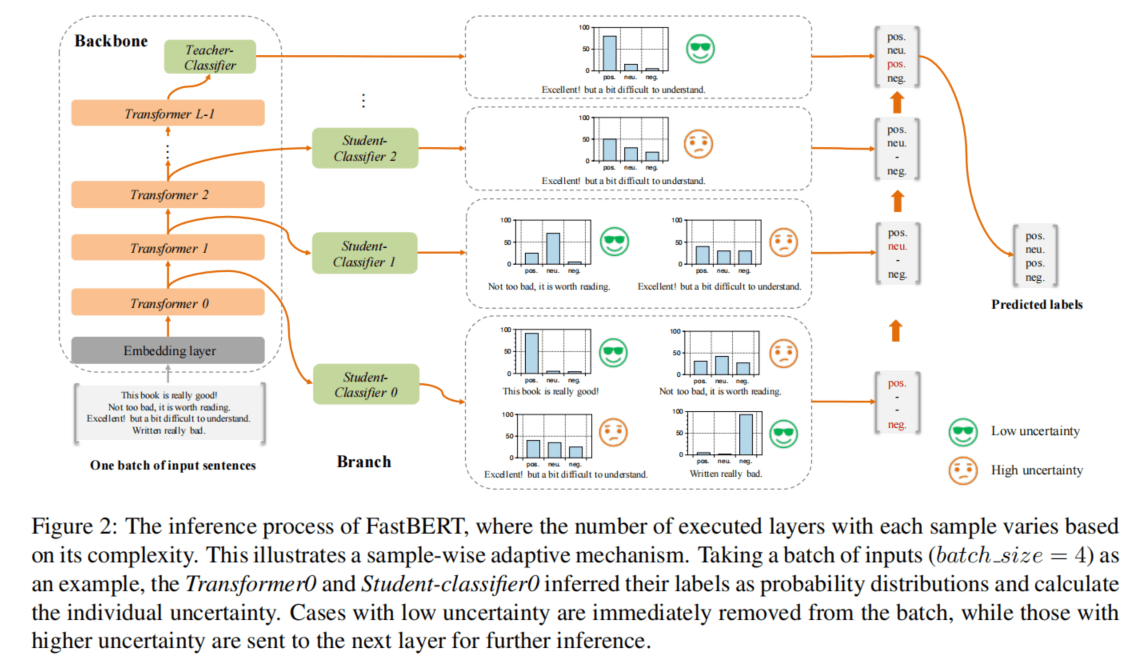
论文阅读:FastBERT: a Self-distilling BERT with Adaptive Inference Time
像 BERT 这一类预训练语言模型已经被证明是高性能的。然而,在许多实际场景中,它们的计算成本往往很高,因为在资源有限的情况下,这种重型模型很难轻易实现。为了在保证模型性能的前提下提高其效率,作者提出了一种新型的具有自适应推断时间的速度可调的 FastBERT。在不同的需求下,推断速度可以灵活调整,同时避免了样本的冗余计算。此外,该模型在微调时采用了独特的自蒸机制,进一步实现了以最小的性能损失获得更大的计算效能。
作者的模型在 12 个英文和中文数据集中取得了可喜的结果,如果给定不同的提速阈值来进行速度性能的权衡,它能够比 BERT 加速 1 到 12 倍不等。
介绍为了提高 BERT 类模型的推断速度,在模型加速方面做了很多尝试,如量化(《Compressing deep convolutional networks using vector quantization》)、权重剪枝(《Learning both weights and connections for efficient neural network》)、知识蒸馏(《Fitnets:Hints for thin dee ...
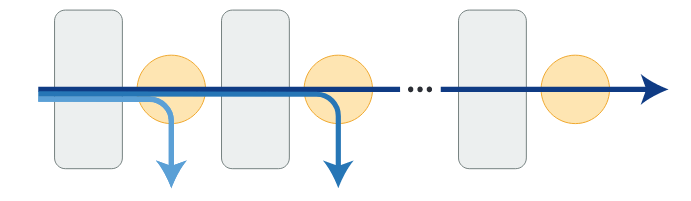
论文阅读:DeeBERT:Dynamic Early Exiting for Accelerating BERT Inference
大规模的预训练语言模型,如 BERT,为 NLP 应用带来了显著的改善。然而,它们也因推断速度慢而受人诟病,这使得它们难以在实时应用中部署。因此,作者提出了一种简单但有效的方法,将其命名为 DeeBERT。该方法允许待预测数据不通过整个模型而提前退出,从而加速 BERT 的推断过程。
实验表明,DeeBERT 能够尽可能保证模型效果的前提下,节省高达 40% 的推断时间。进一步的分析表明,BERT Transformer 层的不同行为也揭示了它们的冗余性。
代码传送门:https://github.com/castorini/DeeBERT
介绍为了加速 BERT 的推断过程,作者提出了 DeeBERT:BERT 的动态提前退出。该方案的灵感来自于计算机视觉领域的一个众所周知的观察结果:深度卷积神经网络中,较高的层通常会产生更详细、更细粒度的特征。因此,作者假设对于 BERT 来说,中间 Transformer 层提供的特征可能足以对一些输入样本进行分类。
DeeBERT 通过在 BERT 的每个 Transformer 层之间插入额外的分类层(作者称之为 off-ramps)来 ...
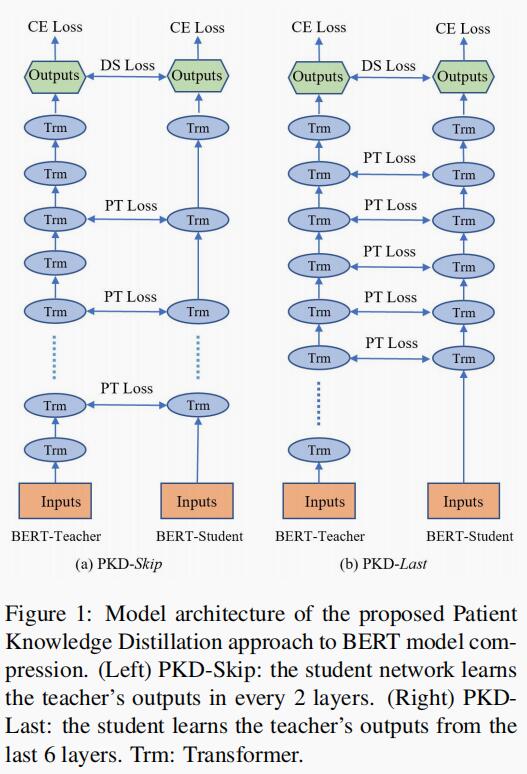
论文阅读:Patient Knowledge Distillation for BERT Model Compression
事实证明,像 BERT 这一类的预训练语言模型对 NLP 任务非常有效。但是,在训练此类模型时对计算资源的高需求阻碍了它们在实践中的应用。为了减轻大规模模型训练中的资源匮乏,作者提出了一种 Patient Knowledge Distillation(耐心的知识蒸馏)方法,将原始的大型模型(教师网络)压缩为同样有效的轻量小型模型(学生网络)。
与之前的知识蒸馏方法不同,前者仅使用教师网络最后一层的输出(《Distilling》)进行蒸馏,而本篇论文中提出的方法则是让学生网络“耐心”地从教师网络的多个中间层学习,并遵循以下两种策略来增加:
PKD-Last:从最后 K 层学习;
PKD-Skip:从每隔 K 层学习。
这两种蒸馏策略可以在教师网络的隐藏层中利用丰富的信息,并鼓励学生网络通过多层蒸馏耐心地向教师网络学习和模仿。
从经验上讲,这可以转化为多个 NLP 任务的改进结果,并且训练效率显著提高,而不会牺牲模型的准确性。
介绍在大规模未标记数据中进行语言模型预训练,从而学习通用语言表征已被证明非常有效。ELMo、GPT 和 BERT 在许多 NLP 任务中都取得了巨大成功,例如情 ...
论文阅读:DistilBERT a distilled vesion of BERT smaller faster cheaper and lighter
在这篇论文中,作者提出了一种方法来预训练一个小的名为 DistilBERT 的通用语言表示模型。该模型可以在广泛的任务中进行 fine tune,并具有良好的性能。虽然先前的大多数工作都在研究如何使用蒸馏来构建特定任务的模型,但作者在预训练阶段就利用了知识蒸馏,并表明可以将 BERT 模型的大小减少 40%,同时保留模型 99% 的语言理解能力和提高 60% 的速度。
为了利用大模型在预训练过程中学到的归纳偏差,论文中引入了语言建模、蒸馏和余弦距离损失相结合的三重损失。消融研究进一步表明:三重损失的每一个组成部分对模型的最佳性能都很重要。
DistilBERTstudent 网络架构DistilBERT 拥有和 BERT 相同的通用架构。不同点在于:
删除 token-type embeddings 和 pooler;
将层数减少 2 倍;
在现代线性代数框架内,高度优化 Transformer 体系结构中使用的大多数操作(线性层和 layer normalisation)
作者指出张量的最后一个维度(hidden size dimension)的变化对计算效率(对于固定参数预算)的 ...
基于 BK 树的中文拼写纠错候选召回
最近在研究中文拼写纠错,在查阅资料的时候看到了这篇文章《从编辑距离、BK树到文本纠错 - JadePeng - 博客园》,觉得 BK 树挺有意思的,决定深入研究一下,并在其基础上重新整理一遍,希望能够对各位读者大大们有所帮助。
前置知识本节介绍实现基于 BK 树的中文拼写纠错候选召回所需要的前置知识,包括文本纠错的主流方案、编辑距离和 BK 树等相关概念。
文本纠错目前业界主流的方案仍然是以 pipeline 的方式:“错误检测 -> 候选召回 -> 候选排序”的步骤依次进行。以平安寿险纠错方案(《NLP上层应用的关键一环——中文纠错技术简述》)为例,其系统整体架构如下图所示(侵权则删):整体上,平安寿险团队将纠错流程分解为错误检测 -> 候选召回 -> 候选排序三个关键步骤。
错误检测:为了解决资源受限问题以及音近错误问题,提出了基于字音混合语言模型的错误检测算法。该模型可以通过未标注的无监督原始语料进行训练,同时利用字音混合特征限制预测概率分布。
候选召回:结合双数组字典树以及 CSR 存储架构优化整体字典存储方案,同时优化内存空间及索引效果。此外,提出创 ...
Alibaba at IJCNLP-2017 Task 1
发布时间:2017
论文作者:阿里巴巴 NLP 团队
本篇论文介绍阿里巴巴 NLP 团队在 IJCNLP 2017 任务 No. 1 中文语法错误诊断(CGED)的做法。任务是诊断四种语法错误,即冗余词语(R)、缺失词语(M)、错误词语(S)和乱序词语(W)。作者将该任务视作序列标注问题,并设计了一些手工特征来解决这个问题。作者的系统主要基于 LSTM-CRF 模型,并应用 3 种集成策略来提高性能。
1. 介绍CGED 任务为中国 NLP 研究人员提供了构建和开发中文语法错误诊断系统,比较其结果并交流学习方法的机会。本篇论文的组织结构如下:
第 2 节:介绍了任务的细节;
第 3 节:介绍了一些相关的中英文著作;
第 4 节:介绍了作者提出的方法,包括特征生成、模型架构和集成策略。
第 5 节:显示评估数据集上的数据分析和最终结果;
第 6 节:总结并展望了未来的工作。
2. 中文语法错误诊断NLPTea CGED 自 2014 年以来一直举办,它提供了几套由中文外语学习者编写的训练数据。在这些训练数据集中,已标记了 4 种 错误:
R:冗余词语;
S:错误词语;
M: ...
快速加载常用数据集
快速加载常用数据集通常情况下,我们会针对不同的数据格式采用不同的数据读取方式,例如使用 json 来读取 .json 文件,使用 jsonlines 来读取 .jsonl 文件,使用 pandas 或者 Python 的文件读取方式来获取 .csv 文件。但这些方法的读取时间各不相同,有快有慢,具体可参考《Python 数据读取方式以及时间比对》。
本文主要介绍如何快速加载常用的数据集。
jsonlines 读取数据集此时,我们有一个 13G jsonlines 格式的数据集,我们使用 jsonlines 包进行读取。
读取代码:
1234%%timefile = "/data/xueyou/data/taobao_note/redbook/0516/data.json"with open(file, "r", encoding="utf-8") as file: datasets_redbook = [line for line in jsonlines.Reader(file)]
所需时间:
12CPU t ...
谐音字典构建方案
谐音字典构建方案计算词语与词语之间的音距,将音距相近的词语聚到一块,从而构造出一个谐音字典。通过该谐音字典,我们可以快速获取指定词语 top k 个谐音词语。
要达成这个目标,我们首先要有一个词典。通过整合目前已有的全部数据集,并对数据集进行清洗,包括去除重复的数据,滤除特殊符号、表情等。然后再对清洗后的数据进行分词、词频过滤,最终得到一个尽可能完备的词典。
全部数据集:/nfs/users/chenxu/project/OpenNMT-tf/asr_correct/data/food_redbook_wiki_dataset.txt
分词后结果:/nfs/users/chenxu/project/OpenNMT-tf/asr_correct/data/data_word_list.json
词频过滤后结果:/nfs/users/chenxu/project/OpenNMT-t ...
基于词向量的相似度短语挖掘
短语挖掘在应用层面上与新词发现有重叠部分,关于新词发现的内容可以参考我的这篇博客《新词发现》。如果我们希望能够从一大段文本中挖掘出新的短语,那么短语挖掘的做法与新词发现相差不大,通过凝聚程度、自由程度等指标对文本片段进行划分,找出新的文本片段作为新的短语。
另一个应用是根据已有的短语从文本中找出语义相似的短语,本篇博客主要介绍这一应用的一个简单实践。
实现思路
首先,我们可以借助分词工具对文本进行分词;
然后,将分词后的词列表映射到词向量空间;
接着,把已有的短语视为启动词,依次便利每个启动词,以启动词在词向量空间中的位置和指定长度半径寻找相似的新词语;
重复第三个步骤,将找到的新词语作为启动词继续挖掘,但这次减小半径长度;
不断重复第 3 和第 4 步骤,直到找不到新的词语。
上述做法与聚类算法中的 DBSCAN(可以参考这篇博客《聚类算法之DBSCAN算法之一:经典DBSCAN》)类似,区别在于 DBSCAN 的半径保持不变,而上述做法中的半径会随着迭代逐渐减小。
【问】:为什么要在迭代的过程中减小半径呢?
【答】:如果按照固定的半径不断寻找新的词语,那么就会发生下图所示的问题, ...
Google Bert 框架训练、验证、推断和导出简单说明
实习的这段期间,在公司做了不少 NLP 分类任务,歧义车系判断、字词重复纠错等等,期间有用过 Google 开源的 Bert 框架,也用过公司大佬制作的 T5 模型。但无论使用什么,起手 Bert 仿佛已经成为了一种“本能”(笑哭.jpg),Bert NLP 算法工程师的至交好友。
写这篇博客的目的一是为了记录先前工作的经验,此外也简单地介绍一下如何使用 Google 官方开源的 Bert 框架,因为目前很少有博客会讲如何将 Bert 训练得到的 checkpoint 转换为 savedModel,这何尝不是一种遗憾,因此我打算将这遗憾填补。对于第一次使用 Bert 框架的读者,我建议从头开始看,若已经有熟练的使用经验,只想了解如何导出模型和使用,可以直接跳到模型导出和使用。
【项目地址】:https://github.com/clvsit/bert-simple-use
准备工作首先,到 GitHub 上 clone Bert 源代码。
google-research/bert:https://github.com/google-research/bert
然后下载预训 ...
python 数据读取方式以及时间比较
先前一直在做汽车项目的数据 Pipeline 搭建,目前终于告一段落,于是打算将这段期间的工作做个总结,整理自身的最佳实践外,也希望能够帮助到有相同需求的读者们。
这篇博客主要介绍几类常见的数据读取方式以及时间比对,json、jsonlines、csv、tsv、pandas 等。后续如果接触到更多的存储形式,则会继续完善这篇博客。需要注意的是,我仅站在使用者的角度去度量这些数据读取方式,对于其内部的运行原理则没有完整的了解,如有错误请麻烦各种大佬不吝指出。
首先,我准备了一批数据,将这批数据分别存储为 json、jsonl、csv、hdf5。
接下来,在 jupyter 中测试 json、jsonlines、pandas、vaex 这四个包的数据读取速度。
json 读取首先,导入 json 包。
1import json
然后,读取 dataset_test.json 文件。
123%%timewith open(os.path.join(project_path, "dataset_test.json"), "r", encoding=& ...
最新文章



