DFA 算法
DFA,全称 Deterministic Finite Automaton 即确定有穷自动机:从一个状态通过一系列的事件转换到另一个状态,即 state -> event -> state。
确定:状态以及引起状态转换的事件都是可确定的,不存在“意外”。
有穷:状态以及事件的数量都是可穷举的。
计算机操作系统中的进程状态与切换可以作为 DFA 算法的一种近似理解。如下图所示,其中椭圆表示状态,状态之间的连线表示事件,进程的状态以及事件都是可确定的,且都可以穷举。
DFA 算法具有多种应用,在此先介绍在匹配关键词领域的应用。
匹配关键词我们可以将每个文本片段作为状态,例如“匹配关键词”可拆分为“匹”、“匹配”、“匹配关”、“匹配关键”和“匹配关键词”五个文本片段。
【过程】:
初始状态为空,当触发事件“匹”时转换到状态“匹”;
触发事件“配”,转换到状态“匹配”;
依次类推,直到转换为最后一个状态“匹配关键词”。
再让我们考虑多个关键词的情况,例如“匹配算法”、“匹配关键词”以及“信息抽取”。
可以看到上图的状态图类似树形结构,也正是因为这个结构,使得 DFA ...
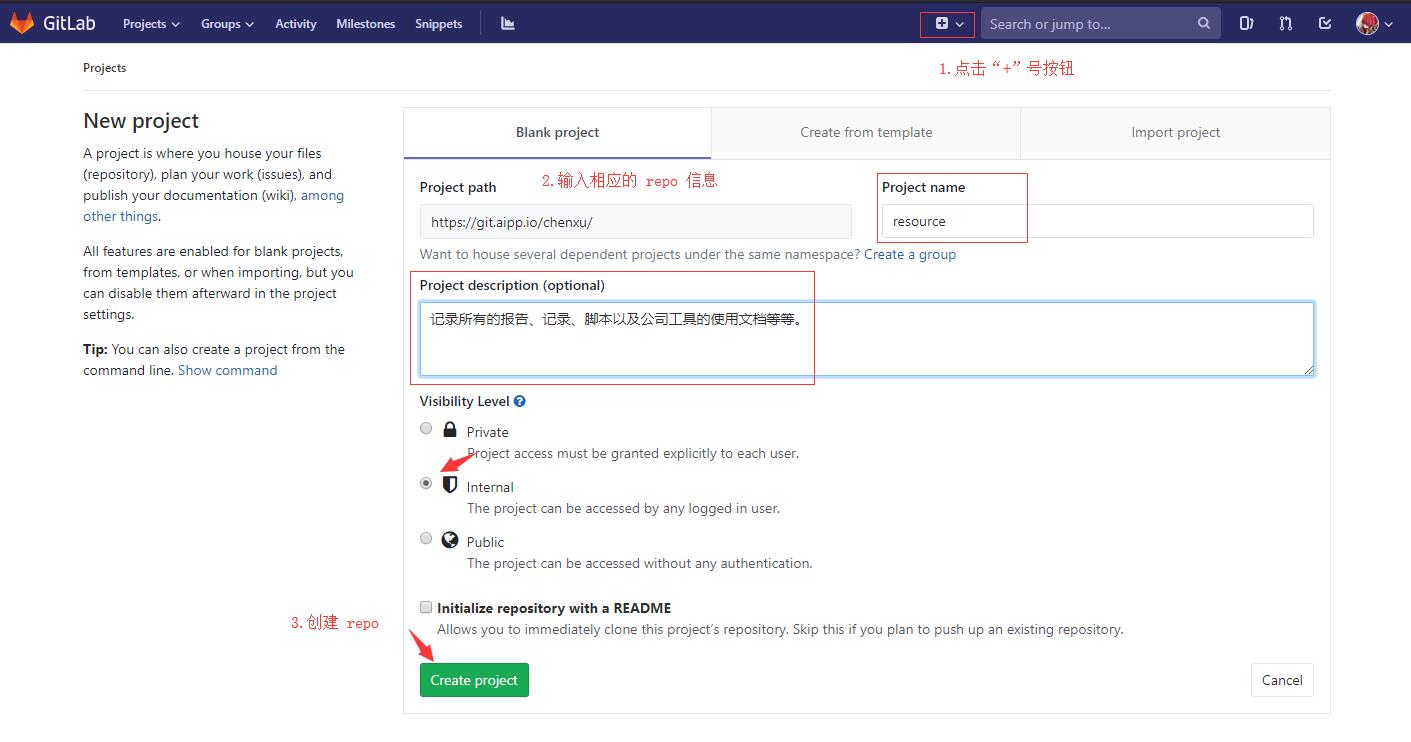
gitlab创建RepoPage
步骤 1:创建项目打开 gitlab,点击上方的“+”号按钮,在显示的页面中填入 repo 相关的信息,例如 Project name 和 description。最后,点击 Create project 按钮。
步骤 2:添加 License在斌哥提供的 Youtubu 教程中需要创建 License,但我在实践的过程中发现该步骤非必需。
创建项目后会自动跳转到 repo 的 detail 页面,在该页面的正中央有一排按钮组,点击“Add License”。
然后,在调整后的页面中,选择 Template -> Apache License 2.0。
步骤 3:添加 .gitlab-ci 配置文件完成 License 添加后,回退到 repo detail 页面,此时已有 LICENSE 文件。
然后按图所示,创建一个新的文件。
在创建新文件的页面中,先在左侧的 Template 下拉框中选择 .gitlab-ci.yml,然后在右侧的下拉框中选择 HTML。最后,点击 Commit changes。
此时,我们查看左侧栏的 CI/CD -> Pipe ...
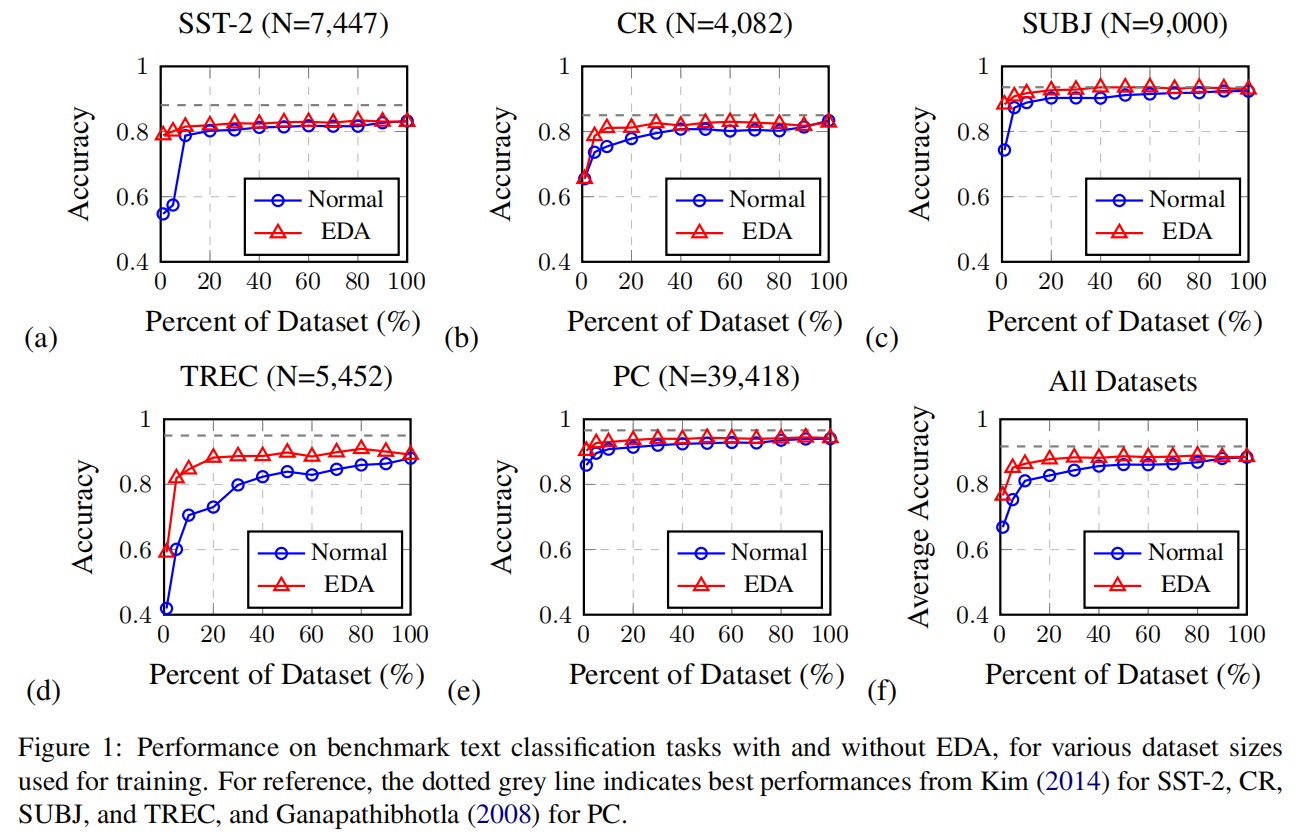
论文阅读:EDA:Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
EDA 包含四个简单但功能强大的操作:同义词替换,随机插入,随机交换和随机删除。在五个文本分类任务上,作者表明 EDA 可以提高卷积神经网络和循环神经网络的性能。EDA 对较小的数据集显示出特别强的结果。平均而言,在五个数据集上,仅使用 50% 的可用训练集进行 EDA 训练就可以获得与使用所有可用数据进行的正常训练得到相同的准确性。此外,作者还进行了广泛的消融研究,并提出了实用的参数。
介绍机器学习和深度学习已在从情感分析到主题分类的任务上实现了很高的准确性,但是高性能通常取决于训练数据的大小和质量,而这往往很难收集。自动数据增强通常用于计算机视觉和语音,可以帮助训练更强大的模型,尤其是在使用较小的数据集时。但是,提出通用的语言转换规则比较困难,因此尚未充分探索 NLP 中的通用数据增强技术。
先前已有相关的研究提出了一些在 NLP 中用于数据增强的技术:
通过翻译来生成新的数据,例如将中文先翻译成英文,然后再将英文翻译成中文,此时就可以生成一份与原句近似语义的新句。
将数据噪声来平滑(smoothing)数据集。
将预测语言模型用作同义词替换。
尽管这些技术是有效的,但实际上它 ...
新词发现
新词发现是 NLP 的基础任务之一,通过对已有语料进行挖掘,从中识别出新词。新词发现也可称为未登录词识别,严格来讲,新词是指随时代发展而新出现或旧词新用的词语。同时,我认为特定领域的专有名词也可归属于新词的范畴。何出此言呢?通常我们会很容易找到通用领域的词表,但要找到某个具体领域的专有名词则非常困难,因此特定领域的专有名词相对于通用领域的词语即为新词。换言之,“新”并非只是时间上的概念,同样可以迁移到领域或空间上。因此,新词发现不仅可以挖掘随时间变化而产生的新词,也可以挖掘不同领域的专有名词。
接下来,让我们开始一场新词发现的探索之旅吧。首先,对于“新词发现”这个标题,我们可将其拆分为“发现”和“新词”两个步骤:
“发现”:依据某种手段或方法,从文本中挖掘词语,组成新词表;
“新词”:借助挖掘得到的新词表,和之前已有的旧词表进行比对,不在旧词表中的词语即可认为是新词。
“新词发现”的难点主要在于“发现”的过程——如何从文本中挖掘到词语?那么有办法回避这个问题吗?让我们思索一下“新词”的过程:比对挖掘得到的新词表和旧词表,从代码的角度来说。
123for 新词 in 新词表: ...
n-gram 词频统计
n-gram 词频统计借助 sklearn 提供的 CountVectorizer 可以实现 n-gram 的词频统计。
实现过程首先,导入所需的包以及数据。
1234567from sklearn.feature_extraction.text import CountVectorizerfrom collections import ChainMapimport tqdmwith open("/nfs/users/chenxu/common_word_mining/dataset_word_cut_small.json", "r", encoding="utf-8") as file: content_list = json.load(file)
然后,调用 CountVectorizer,以获得每段文本的文本向量。
12vectorizer = CountVectorizer(token_pattern=r"(?u)\b\w+\b", ngram_range=(2,2), min_df=5)X ...
函数注释及其妙用
注释函数注释【示例】:
123456789101112@staticmethoddef report_info_add(report_a: dict, report_b: dict, key: str) -> int: """ 报告信息相加 :param report_a: dict 报告信息字典 A :param report_b: dict 报告信息字典 B :param key: str 指定 key 值 :return: int 相加后的数值 """ report_a_value = report_a[key] if key in report_a else 0 report_b_value = report_b[key] if key in report_b else 0 return report_a_value + report_b_value
在函数声明中 report_a 是参数,: 冒号后 dict 是参数 report_a 的 ...

模型优化
优化是应用数学的一个分支,也是机器学习的核心组成部分。实际上,机器学习算法 = 模型表征 + 模型评估 + 模型优化。其中,模型优化所做的事情就是在模型表征空间(假设空间)中找到模型评估指标最好的模型。需要注意的是不同的优化算法对应的模型表征和评估指标不尽相同。
先前,我很纠结是把损失函数放在模型评估中,还是放在模型优化这一篇博客中。准确地说,损失函数是用来作为模型评估的标准,不同的模型有不同的损失函数,例如逻辑回归使用交叉熵损失函数,线性回归使用均方误差损失函数。我们统计模型的损失,从而评估模型的优劣。因此,损失函数放到模型评估中是顺理成章的事情。但是,损失函数在模型优化中同样起到非常重要的作用。
很少有模型从一开始就是完美的,我们需要不断地优化模型,让模型逐渐达到理论最优值,而我们优化的目标就是损失函数——让损失函数达到最小值。从这角度来讲,将损失函数放到模型优化中似乎也非常有道理,因此我最终还是将损失函数放到模型优化这一篇博客中。
在本篇博客中除了讲述损失函数外,还包括机器学习中经典的优化算法、模型调参等相关知识,内容主要来源于博主阅读的书籍以及博主的个人领悟,若有偏驳 ...
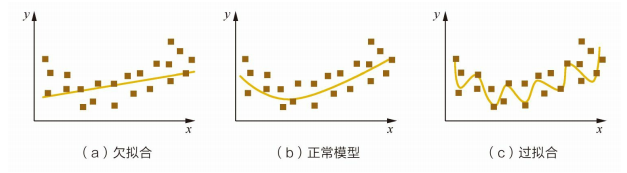
模型评估
只有选择与问题相匹配的评估方法,才能快速地发现模型选择或训练过程中出现的问题,迭代地对模型进行优化。针对分类、排序、回归、序列预测等不同类型的机器学习问题,评估指标的选择也有所不同。知道每种评估指标的精确定义、有针对性地选择合适的评估指标、根据评估指标的反馈进行模型调整,这些都是机器学习在模型评估阶段的关键问题。
首先,我们先来了解一下关于模型评估的基础概念。
【误差(error)】:学习器的预测输出与样本的真实输出之间的差异。根据产生误差的数据集,可分为:
训练误差(training error):又称为经验误差(empirical error),学习器在训练集上的误差。
测试误差(test error):学习器在测试集上的误差。
泛化误差(generalization error):学习器在未知新样本上的误差。
需要注意的是,上述所说的“误差”均指误差期望,排除数据集大小的影响。
【目的】:得到泛化误差小的学习器。然而,事先并不知道新样本,实际能做的是努力使经验误差最小化。但需要明确一点,即使分类错误率为 0,精度为 100% 的学习器,也不一定能够在新样本上取得好的预测结果。 ...
%E6%80%9D%E7%BB%B4%E5%AF%BC%E5%9B%BE.png)
模型评估-性能度量(回归问题)
对学习器的泛化性能进行评估,不仅需要有效可行的实验估计方法,还需要有衡量模型泛化能力的评价标准,这就是性能度量(performance measure)。
性能度量反映了任务需求,在对比不同模型的能力时,使用不同的性能度量往往会导致不同的评判结果,这意味着模型的“好坏”是相对的,什么样的模型是好的,不仅取决于算法和数据,还决定于任务需求。
在预测任务中,给定数据集 $D = {(x_1, y_1), (x_2, y_2), \ldots, (x_m, y_m)}$,其中 $y_i$ 是示例 $x_i$ 的真实标记。要估计学习器 f 的性能,就要把学习器预测结果 $f(x)$ 与真实标记 y 进行比较。
为了说明各性能度量指标,我们以波士顿房价数据集为例,模型选择决策树算法,通过 train_test_split() 划分数据集,最后评估各项性能指标。
123456789101112131415from sklearn.datasets import load_bostonfrom sklearn.tree import DecisionTreeRegressorfrom sk ...
模型评估-性能度量(分类问题)
对学习器的泛化性能进行评估,不仅需要有效可行的实验估计方法,还需要有衡量模型泛化能力的评价标准,这就是性能度量(performance measure)。
性能度量反映了任务需求,在对比不同模型的能力时,使用不同的性能度量往往会导致不同的评判结果,这意味着模型的“好坏”是相对的,什么样的模型是好的,不仅取决于算法和数据,还决定于任务需求。
在预测任务中,给定数据集 $D = {(x_1, y_1), (x_2, y_2), …, (x_m, y_m)}$,其中 $y_i$ 是示例 $x_i$ 的真实标记。要估计学习器 f 的性能,就要把学习器预测结果 $f(x)$ 与真实标记 y 进行比较。
为了说明各性能度量指标,我们以鸢尾花数据集为例,模型选择决策树 CART 算法,通过 train_test_split() 划分数据集,最后评估各项性能指标。
123456789101112131415from sklearn.datasets import load_irisfrom sklearn.tree import DecisionTreeClassifierfrom skle ...
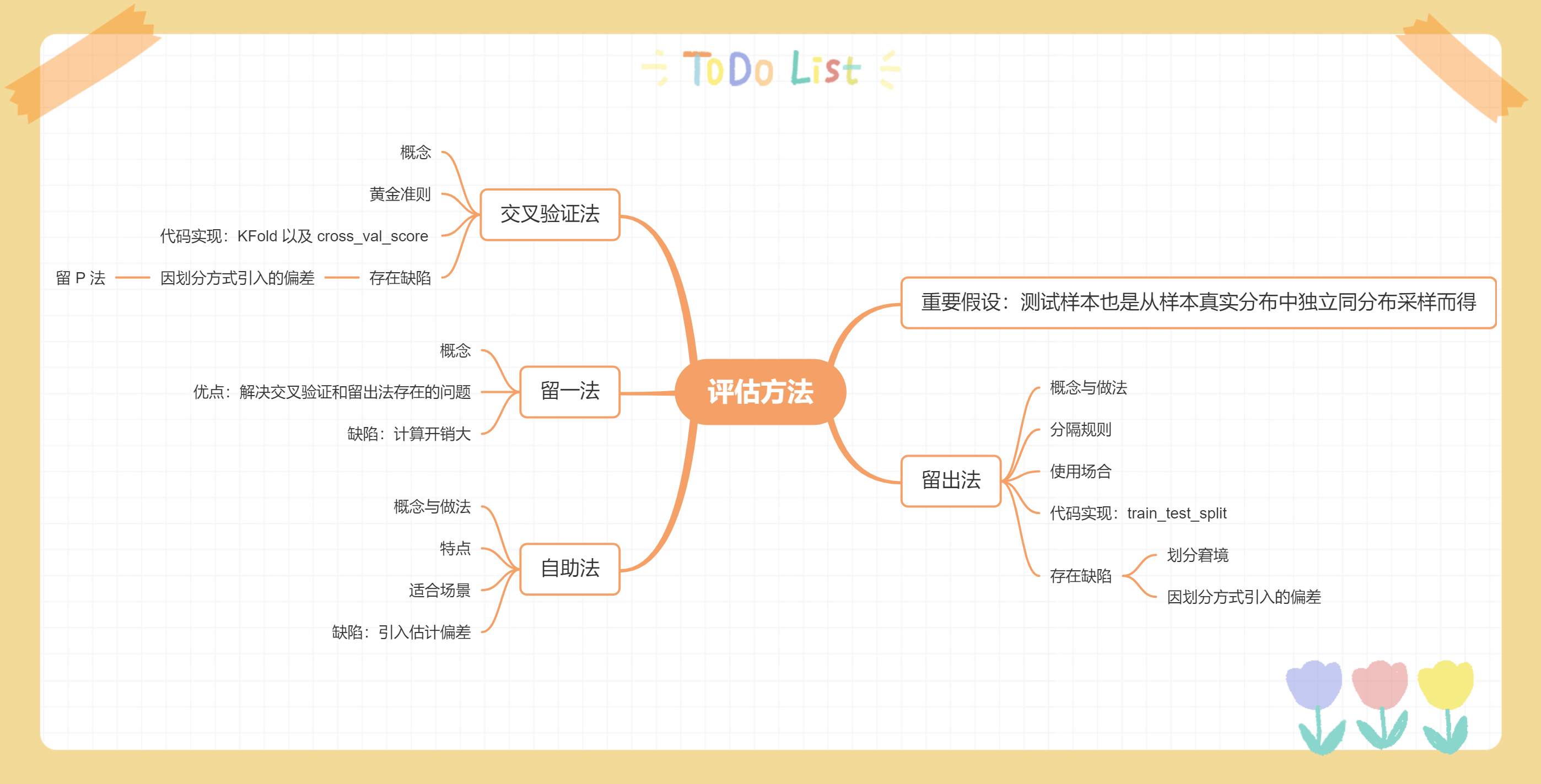
模型评估-评估方法
通常通过实验测试来对学习器的泛化误差进行评估并进而做出选择。为此,需要使用一个“测试集”(testing set)来测试学习器对新样本的判别能力,然后以测试集上的“测试误差”(testing error)作为泛化误差的近似。
【重要假设】:测试样本也是从样本真实分布中独立同分布采样而得。举个简单的例子,假设你要检验新研发的药对人的作用,你肯定是选择小白鼠,而不是红鲤鱼。因为红鲤鱼是鱼类,而小白鼠与人同属于哺乳动物。
下面将介绍机器学习中常用的评估方法,主要通过 sklearn 和鸢尾花数据集来进行说明。
1234567from sklearn.datasets import load_irisdataset = load_iris()data_iris = dataset.datatarget_iris = dataset.targetfeature_iris = dataset.feature_names
留出法留出法将测试数据集和训练数据集完全分开,采用测试数据集来评估算法模型。也就是说,我们可以简单地将原始数据集分为两部分:
第一部分作为训练数据集,用来训练算法生成模型;
第 ...

特征选择-过滤式选择
过滤式方法先按照某种规则对数据集进行特征选择,然后再训练学习器,特征选择过程与后续学习器无关,这相当于先用特征选择过程对初始特征进行“过滤”,再用过滤后的特征来训练模型。
【某种规则】:按照发散性或相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,从而选择满足条件的特征。
特征的发散性:如果一个特征不发散,例如方差接近于 0,也就是说样本在该特征上基本没有差异,那么这个特征对于样本的区分并没有什么用。
特征与目标的相关性:特征与目标的相关性越高说明特征的变动对目标的影响较大,因此我们应当优先选择与目标相关性高的特征。
在后续所讲的方法中除方差选择法是基于特征发散性,其余方法均是从相关性考虑。
方差选择法计算各个特征的方差,然后根据阈值选择方差大于阈值的特征,或者指定待选择的特征数 k,然后选择 k 个最大方差的特征。
方差选择的依据是什么?举个极端的例子,在多分类问题中,如果某特征只有一个取值,那么该特征对分类结果没有任何意义,因为不管取什么值都为 1,单凭该特征是无法区分样本的分类。
需要注意的是,方差选择法只有在特征是离散型时才适用,如果是连续型则需要离散化后才能使用。 ...
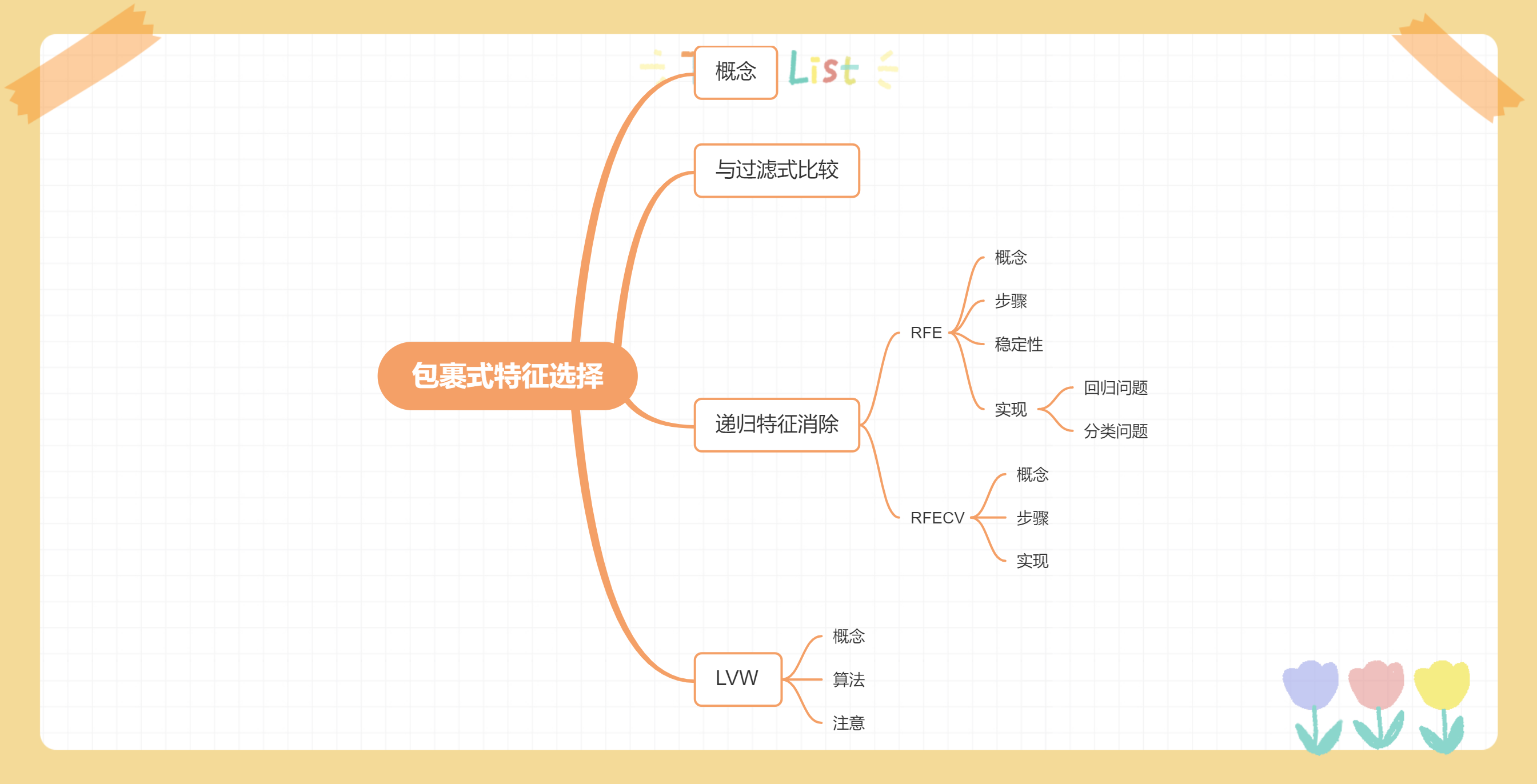
特征选择-包裹式选择
包裹式选择与过滤式选择不考虑后续学习器不同,直接把最终使用的学习器的性能作为特征子集的评价准则。换言之,包裹式选择的目的就是为给定学习器选择最有利于其性能、“量身定做”的特征子集。
【与过滤式选择的区别】:
包裹式选择方法直接针对给定学习器进行优化,因此,从最终学习器性能来看,包裹式选择比过滤式选择更好;
但另一方面,由于在特征选择过程中需多次训练学习器,因此包裹式选择的计算开销通常比过滤式选择大得多。
递归特征消除递归特征消除(Recursive Feature Elimination)使用一个基模型(学习器)来进行多轮训练,每轮训练后移除若干特征,再基于新的特征集进行下一轮训练。
【sklearn 官方解释】:对特征含有权重的预测模型,RFE 通过递归减少待考察特征集规模来选择特征。
首先,预测模型在原始特征集上进行训练,通过 coef_ 属性或 feature_importances_ 属性为每个特征指定一个权重;
然后,剔除那些权重绝对值较小的特征;
如此循环,直到剩余的特征数量达到所需的特征数量。
需要注意的是,RFE 的稳定性很大程度上取决于迭代时,底层使用的预测 ...
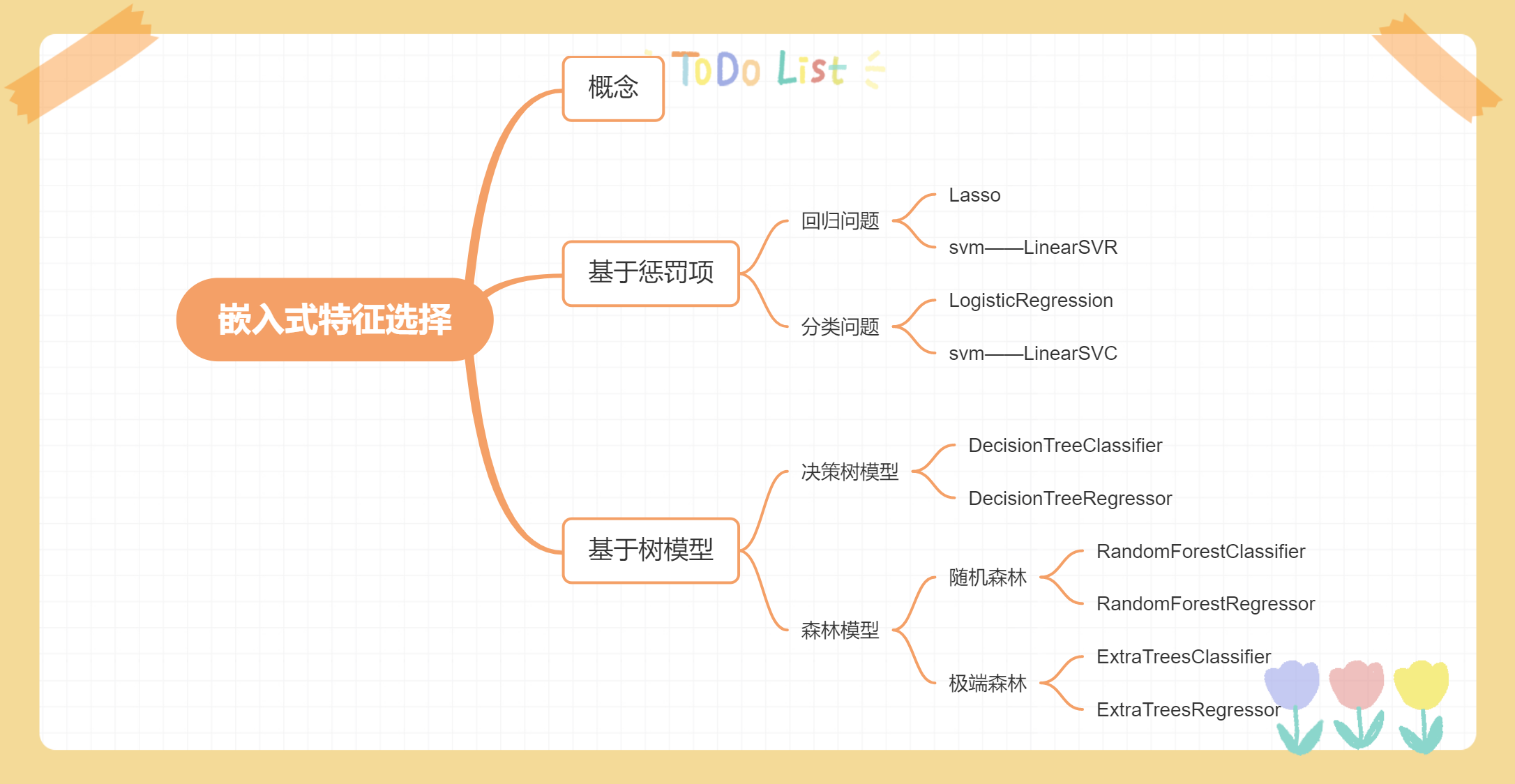
特征选择-嵌入式选择
嵌入式特征选择是将特征选择过程与学习器训练过程融为一体,两者在同一个优化过程中完成,即在学习器训练过程中自动地进行了特征选择。
基于惩罚项的特征选择法给定数据集 $D = {(x_1, y_1), (x_2, y_2), \cdots, (x_n, y_n)}$,其中 $x \in R^d, y \in R$。我们考虑最简单的线性回归模型,以平方误差为损失函数,则优化目标为$$min_w \sum_{i=1}^n(y_i - w^Tx_i)^2$$当样本特征很多,而样本数相对较少时,上式很容易陷入过拟合。为了缓解过拟合问题,可对上式引入正则化项。
使用 L2 范数正则化,则称为“岭回归”(ridge regression)。
$$min_w \sum_{i=1}^n(y_i - w^Tx_i)^2 + \lambda ||w||_2^2$$通过引入 L2 范数正则化,确能显著降低过拟合的风险。
使用 L1 范数正则化,则称为 LASSO(Least Absolute Shrinkage and Selection Operator)。
$$min ...
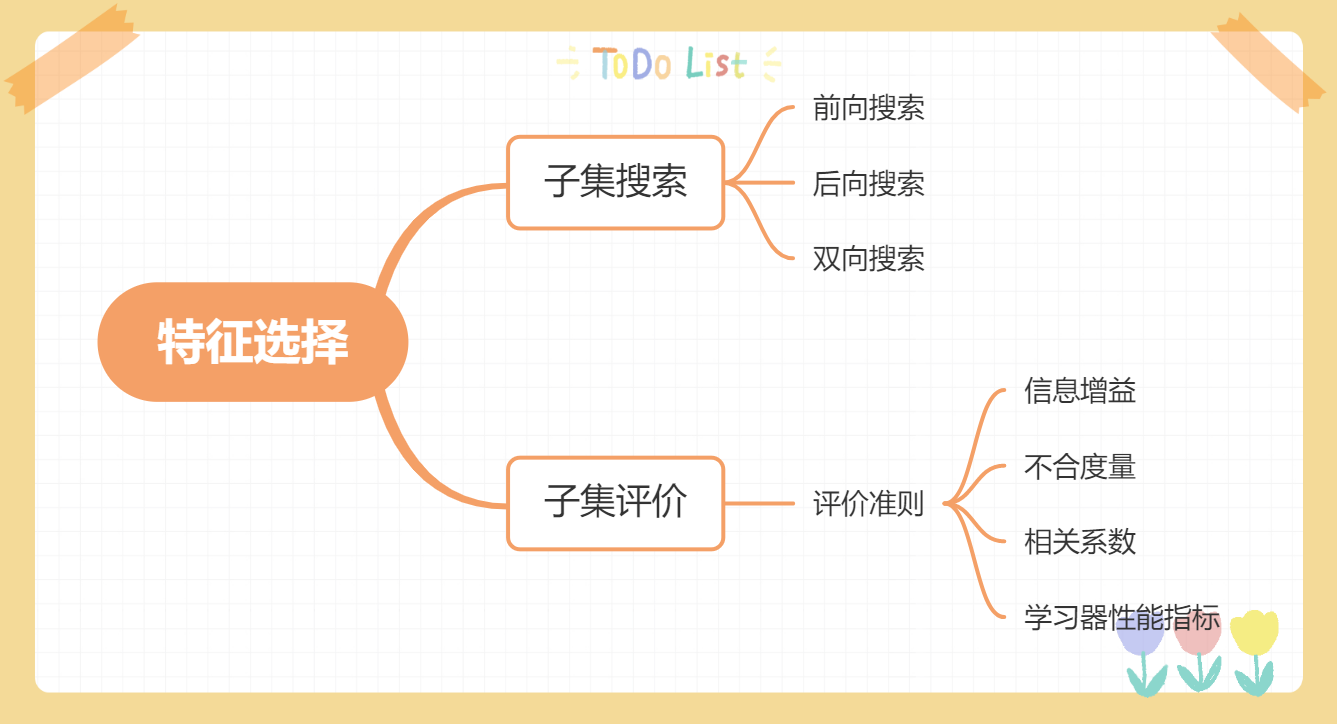
特征选择
对一个学习任务来说,给定属性集,其中有些属性可能很关键、很有用,另一些属性则可能没什么用,我们将属性称为“特征”(feature),对当前学习任务有用的属性称为“相关特征”(relevant feature)、没什么用的属性称为“无关特征”(irrelavant feature)。从给定的特征集合中选择出相关特征子集的过程,称为“特征选择”(feature selection)。
【注意】:
特征的相关与无关是相对当前学习任务而言,若更换学习任务则有可能使得原本相关特征变为无关特征。例如姓名特征对于预测年龄几乎没有什么作用,但对于预测性别则有一定的参考价值。
特征选择过程必须确保不丢失重要特征,否则后续学习过程会因为重要信息的缺失而无法获得好的性能。
特征选择是一个重要的“数据预处理”过程,在现实机器学习任务中,获得数据之后通常先进行特征选择,此后再训练学习器,那么为什么要进行特征选择呢?
首先,我们在现实任务中经常会遇到维数灾难问题,这是由于特征过多而造成的,若能从中选择出重要的特征,使得后续学习过程仅需在一部分特征上构建模型,则维数灾难问题会大为减轻。从这个意义上来说,特征选 ...

特征归一化
概念消除数据特征之间的量纲影响,可以将所有的特征都统一到一个大致相同的数值区间内,使得不同指标之间具有可比性。例如,分析一个人的身高和年龄对健康的影响,通常身高用 cm 作为单位,而年龄用岁作为单位,那么身高特征会大致在 160180 cm 的数值范围内,年龄特征会在 1100 岁的范围内,分析的结果显然会倾向于数值差别比较大的身高特征。想要得到更为准确的结果,就需要对数据进行特征归一化(Normalization)处理,使各指标处于同一数值量级,以便进行分析。特征归一化有时被称为特征缩放或特征规范化。
【量纲(dimension)】:物理量固有的、可度量的物理属性。例如,人的身高、体重和年龄等。
【问答 QA】:
问:为什么对拥有不同数值量级特征的数据集进行分析,其结果会倾向于数值差别较大的特征?
答:具体内容可以参考这篇博文 K-近邻算法 问题 QA 中的“为什么要做数据归一化”。
通常对于需要计算数据集特征距离的模型,我们都需要提前对数据集做特征归一化,尤其是数值型的数据。
常用方法
线性函数归一化(Min-Max Scaling):又称为 min-max 缩放,是对原始数据 ...
最新文章



