模型参数量及显存分析
当前业界主流的 LLM 大都是基于 Transformer 架构,按照结构的不同,可分为两大类:encoder-decoder(代表模型是 T5 和 PaLM)和 decoder-only(GPT 系列、Llama 系列等等)。
为了方便分析,事先定义好数学符号以及它们所代表的内容。
- l(layer):模型的层数。
- h(hidden size):隐藏层的维度。
- ih(intermediate size):MLP 层提升的维度。
- a(attention heads):注意力头数。
- V(vocab size):词表大小。
如果模型符合 HugginFace Transformers 库的格式,则这些信息可以在 config.json 文件中查看。下面以 mistralai/Mistral-7B-Instruct-v0.2 为例。
1 | { |
除了上述数据外,还需要考虑训练批次和序列长度。
- b(batch size):训练数据的批次大小。
- s(seq length):序列长度。
显存内容分析
该部分的内容摘录自 [LLM]大模型显存计算公式与优化。
在模型训练/推理时,显存(显卡的全局内存)分配一部分是给 AI 框架,另一部分给了系统(底层驱动)。总的显存消耗量可以通过 API 查询,比如在 NVIDIA-GPU 上通过 nvidia-smi 指令能够打印出各个进程的显存消耗量。
其中系统层的显存消耗一般由驱动控制,用户不可控;框架侧的显存消耗用户可控,也是本文分析的重点。以 PyTorch 框架为例通过显存可视化工具,看一下训练过程中显存的消耗。
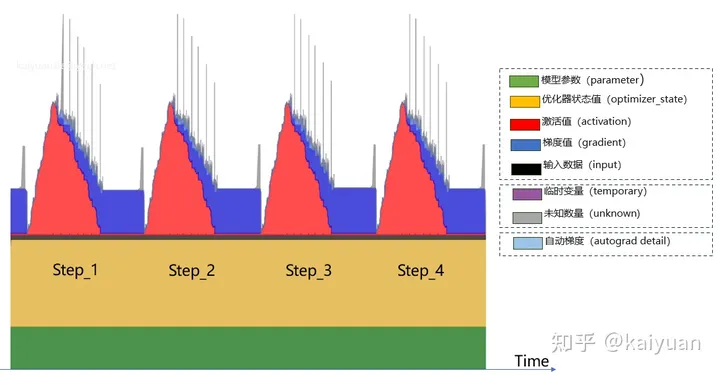
显存消耗的内容包括:模型参数(parameters)、优化器状态值(optimizer_state)、激活值(activation)、梯度值(gradient)、输入数据(input)、临时变量(temporary)、自动梯度(autograd_detail)和未知变量(unknown)。
从用户侧可以将这些数据进行一个分类:
- 可估算值:模型参数(parameter)、优化器状态值(optimizer_state)、激活值(activation)、梯度值(gradient)、输出数据(input)
- 未命名数据:临时变量(temporary)、未知数据(unknown)
- 其他(框架):自动梯度(autograd_detail)
其中“未命名数据”来源可能是用户创建的一些临时变量,这些变量未参与图的计算过程,所以未被统计;或者是一些未被框架跟踪(tracing)到的数据。“自动梯度数据”是在反向传播求解梯度时产生的一些变量;
我们在显存计算时会发现“为什么有时显存估算值和实际测量值相差较大?”其中一个可能的原因是:未知的数据太大。即显存中可估算值占比相对较小,其它不可估算值的数据占比较大,导致计算值和实际值差距较大(**误差可超过 30%**),比如估算得到的显存消耗为 50GB,而实际测试达到了 75GB。
如下图是运行一个LLM模型采集的一些过程数据,可以看到unknown占比有时能达到30%。
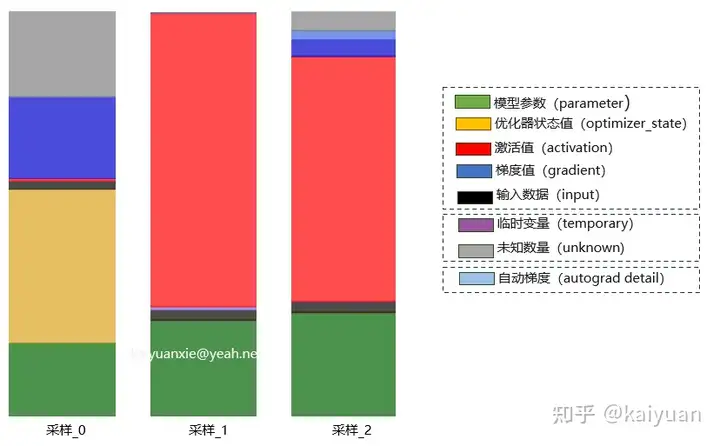
训练显存消耗(可估算部分)主要包括:模型参数(Model)+ 优化器状态(Optimizer) + 梯度值(Gradient)+ 激活值(Activation)。根据数值的变化,可将显存消耗分为静态/动态值。在训练过程中,模型参数、优化器状态一般不会变化,这两部分归属于静态值;激活值、梯度值会随着计算过程发生变化,归属于动态值。
Decoder-Only 架构
decoder-only 架构又可以进一步分为 CausalLM(代表模型是 GPT 系列,以及最近出的一系列大模型)和 PrefixLM(代表模型是 GLM)。
模型参数量
基于 Transformer 架构的模型,往往由 l 个相同的层堆叠而成,每个层分为两部分:self-attention 块和 MLP 块。此外,每一块内还有 LayerNorm。
self-attention 块
self-attention 块的模型参数有 Q、K、V 的权重矩阵 $W_Q$、$W_K$、$W_V$ 和偏置,输出权重矩阵 $W_O$ 和偏置,4 个权重矩阵的 shape 为 [h, h],4 个偏置的 shape 为 [h]。因此,总参数量为 $4h^2 + 4h$。
但实际上,目前大多数 LLM 的 Q、K、V 权重矩阵不再有偏置项,知乎上也有相应的问题:https://www.zhihu.com/question/645810022。这里采用时间旅客的回答。
现在很多 LLM(比如 Llama)的所有模块(包括 FFN、attention 以及 LN/RMSnorm 等)都不设置 bias 项了。源于 Google 的 PaLM 发现去掉 bias 项可以增加训练的稳定性。No Biases - No biases were used in any of the dense kernels or layer norms. We found this to result in increased training stability for large models.
补充一下,“通常”不设置并不代表就不能设置 bias 项。比如微软的 Phi-1 模型,在 attention、FFN,每个 transformer layer 的 pre layernorm 以及最后的 final layernorm 都设置了 bias,也训练得很好。
因此,如果没有偏置项,self-attention 块参与训练的总参数量为 $4h^2$。下面以 HuggingFace Transformers 库的 MistralAttention 实现为例。
1 | class MistralAttention(nn.Module): |
忽略类变量的参数量,可训练参数主要是Q、K、V 和 O 这四个 nn.Linear() 层的参数,rotary_emb 是 RoPE 位置编码,不需要参与训练,但也会占用显存。
注意:mistral 使用了 GQA,而不是 MQA,
k_proj和v_proj的参数量要更少,关于 GQA 的相关内容可参考 论文阅读:GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
MLP 块
传统 MLP 块由 2 个线性层组成,一般地,第一个线性层会将维度从 h 升维(映射)到 ih,第二个线性层再将维度从 ih 降至 h。第一个线性层的权重矩阵 W1 的 shape 为 [h, ih],偏置的 shape 为 [ih]。第二个线性层权重矩阵 W2 的 shape 为 [ih, h],偏置的 shape 为 [h]。因此,总参数量为 2h x ih + ih + h。
Llama 系列以及 Mistral 系列,包括各大开源的 LLM 都使用了 GLU(Gated Linear Units,门控线性单元),用来控制信息能够通过多少。因此,除了升维和降维的线性层,还有一个门控线性层,其形状与降维线性层相同,即 [ih, h]。因此,总参数量为 3h x ih + ih + 2h,如果不考虑偏置,则总参数量为 3h x ih。
各常见 LLMs 的 h 和 ih 如下表所示。
| 模型名称 | hidden size | intermediate size | MLP 参数量 |
|---|---|---|---|
| Llama-7B | 4096 | 11008 | 135,266,304 |
| Llama2-7B | 4096 | 11008 | 135,266,304 |
| Llama2-13B | 5120 | 13824 | 212,336,640 |
| Mistral-7B | 4096 | 14336 | 176,160,768 |
| Zephyr-7B | 4096 | 14336 | 176,160,768 |
| Starling-LM-7B | 4096 | 14336 | 176,160,768 |
| Qwen-7B | 4096 | 22016 | 270,532,608 |
| Qwen-14B | 5120 | 27392 | 420,741,120 |
训练过程的显存占用
在模型训练过程中,占用显存的主要内容为:模型参数、前向计算过程中产生的中间激活、反向传播计算得到的梯度以及优化器状态。这里着重分析参数、梯度和优化器状态的显存占用,中间激活的显存占用下文再详细介绍。
在一次训练迭代中,每个可训练模型参数都会对应一个梯度,并对应优化器状态(不同的优化器有不同的参数量,例如 Adam 优化器,需要存储梯度的一阶动量和二阶动量)。设模型参数量为$\Phi$,梯度的元素数量为$\Phi$,AdamW 优化器的元素数量为 2$\Phi$。
- 不使用混合精度训练:模型参数、梯度和 AdamW 优化器状态都用 float32 存储,float32 数据类型的元素占 4 bytes,共计 16$\Phi$bytes。
- 使用混合精度训练:使用 float16 数据类型的模型参数进行前向传播和反向传播,计算得到 float16 数据类型的梯度;在优化器更新模型参数时,会使用 float32 数据类型的优化器状态、梯度和模型参数来更新模型参数。在下一个 step 时,将这些 float32 数据类型的模型参数再转化为 float16 数据类型。因此,共计 ((2 + 4) + (2 + 4) + (4 + 4))$\Phi$ = 20$\Phi$bytes。
在传统的单精度训练中,所有的计算和参数保存都是以 float32 浮点格式进行的,不需要额外的精度备份。参数更新、梯度计算和权重存储都使用同一种精度,因此只需要一份参数的拷贝。在混合精度训练中,情况略有不同。虽然大部分前向和反向传播的计算都使用 float16 浮点格式(半精度)来加速运算和减少显存占用,但为了保持训练的稳定性和模型最终的精度,通常需要保留一份 float32 的模型权重副本。这是因为半精度浮点数由于其较小的表示范围和精度,可能在训练过程中引入数值不稳定性。
问题:混合精度训练时,虽然将模型参数用 float16 数据类型存储,但在反向传播时,仍然要以 float32 数据类型进行参数更新,从而导致还要额外保存一份模型参数和梯度的 float32 数据类型备份,总的显存占用比不使用混合精度训练还要高,这是为什么?
回答:混合精度训练节省的显存在混合精度训练中主要来自于前向传播过程中的中间激活值,以及反向传播中计算梯度所需的激活值。这些中间激活值通常占用了大量的显存,尤其是在深层和宽层的神经网络中。上述的计算过程中没有考虑中间激活的显存占用,因此会觉得使用混合精度训练反而增加了显存。
在混合精度训练中,通过将这些中间激活值存储为16位浮点数(半精度),而不是传统的32位浮点数(单精度),可以减少显存的使用。由于半精度浮点数只需要单精度浮点数一半的位数,因此理论上可以减少一半的显存占用。这使得可以使用更大的批量大小进行训练,或者在相同的批量大小下使用更复杂的模型,同时还能加快计算速度。
问题:在 ZeRO 论文中是 16$\Phi$= (2 + 4) + 2 + (4 + 4),没有梯度的 fp32 副本,如下图所示。在 ZeRO 论文中,将模型参数的 fp32 副本算在优化器内,整体的显存占用量用 K 表示,取决于优化器的算法,如果是 Adam,则 K = 12 = 4 + (4 + 4)。那么,到底是按20$\Phi$还是16$\Phi$计算呢?
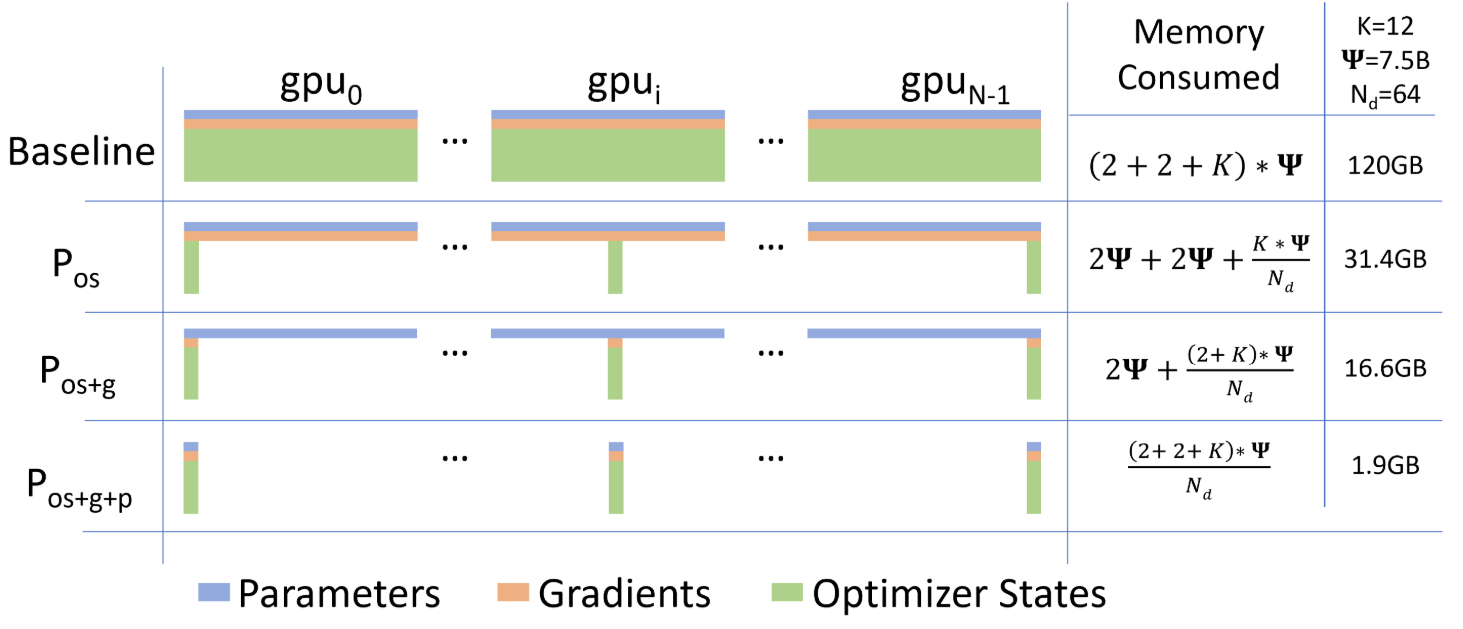
回答:在混合精度训练中,梯度通常使用全精度(fp32)进行累积和存储,而不是半精度(fp16)。这是因为在反向传播过程中,梯度的累积和求和操作可能会导致数值精度问题。因此模型参数会有一份 fp32 的副本,而该副本的梯度也是 fp32,因此在实现层面上会有梯度的 fp32 副本,按照20$\Phi$进行计算。

deepspeed 代码地址:https://github.com/microsoft/DeepSpeed/blob/master/deepspeed/runtime/bf16_optimizer.py#L162
在 2024 年 6 月 29 日在微信公众号上看到一篇文章现在 LLM 的大小为什都设计成6/7B、13B 和 130B 几个档次。里面提到 megatron 框架的显存占用系数是 18 = 2(半精度模型参数) + 4(单精度梯度)+4(单精度模型参数副本)+ 4(单精度一阶动量)+ 4(单精度二阶动量)。实际上半精度模型参数并不需要再存储一份半精度的梯度,因此总的系数是 18,而非 20。
训练的并行计算
随着大模型的参数量突飞猛进,单张 GPU 的显存难以承载,一般会采用模型并行方式来降低单卡显存消耗。常见的几种方法:TP、SP、PP、Zero 和重计算,这些方法出现在 DeepSpeed、Megtron 等并行框架中,目标是让 GPU 能够装下更大的模型,关于这部分的内容请参阅 分布式并行训练。
单卡场景下,不考虑中间激活时,各并行策略的显存计算:
- 当没有并行策略时:TotalMemory = Model + Optimizer + Activation + Gradient。
- 经过并行策略的调整:$TotalMemory = \frac{Model}{PP * TP} + \frac{Optimizer}{N} + \frac{Activation}{TP} + \frac{Gradient}{PP}$。
3D 并行主要是 TP(SP)/PP/DP,其中 DP 为数据并行主要用于提升 batch size,不降低单卡的显存消耗,但 3D 存在一个耦合关系,DP 的设置一般满足:$DPsize(degree) = GPUs/(PP * TP)$。而 TP(SP)/PP 可降低模型、激活值、梯度的显存占用大小。PP 和 TP 共同降低模型参数的显存占用,PP 降低梯度的显存占用。
注意:梯度显存没有除以 TP,主要是考虑到反向计算时需要 All-Gather 完整梯度。
重计算(Recomputation)
在深度学习模型训练过程中,重计算(Recomputation)是指在反向传播过程中,为了节省显存而重新计算某些中间激活值。重计算技术可以有效减少显存开销,使得在显存有限的设备也能训练更大规模的模型。
结合论文 [Reducing Activation Recomputation in Large Transformer Models] 里面给出的计算公式,激活值所占用的显存计算公式如下:

- 选择重计算 + 张量并行:$s * b * h * (10 + \frac{24}{t}) * L * \gamma$
- 选择重计算 + 张量、序列并行:$s * b * h * (\frac{34}{t}) * L * \gamma$
- 全部重计算:$s * b * h * (2) * L * \gamma$
其中,$\gamma$为比例系数,当数据类型为 fp16 时,值等于 1/(1024 * 1024 * 1024) GB。
ZeRO 方法
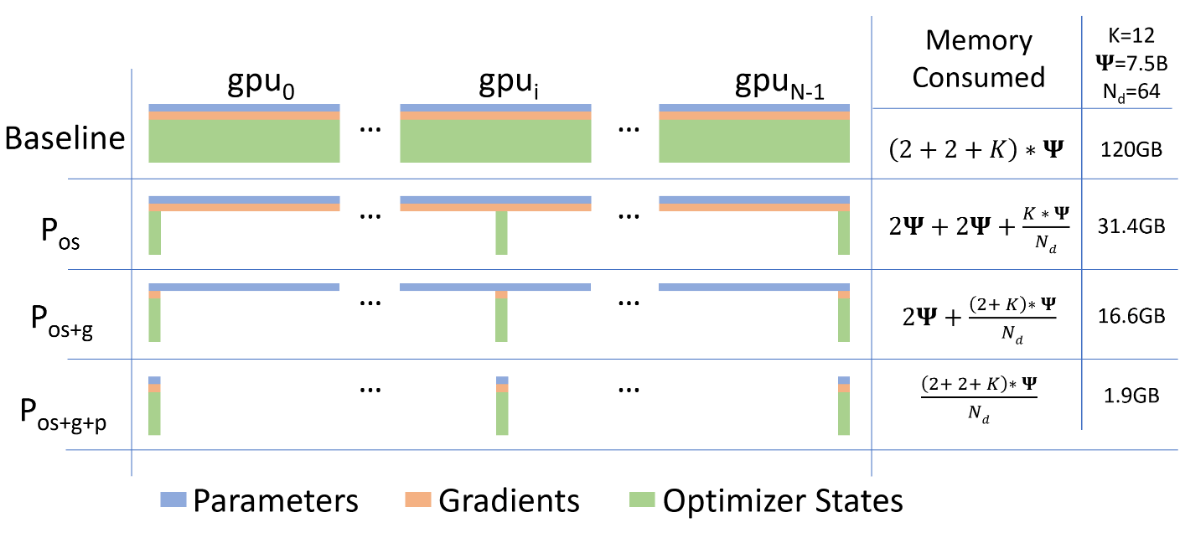
仅开启 ZeRo 的计算公式为:
- ZeRO1:TotalMemory = Model + Optimizer / N + Activation + Gradient
- ZeRO2:TotalMemory = Model + Activation + (Optimizer + Gradient) / N
- ZeRO3:TotalMemory = Activation + (Model + Optimizer + Gradient) / N + LiveParams
其中 N 是 GPU 的数量,LiveParams 是 ZeRO3 引入的参数,这些参数用于控制模型中哪些参数需要加载到 GPU,本身的显存占用不可忽视。
中间激活值计算
暂时有些问题,在查阅资料中
推理过程的显存占用
在模型推理阶段,没有优化器状态和梯度,也不需要保存中间激活,因此占用的显存要远小于训练阶段。占用显存的大头主要是模型参数,令模型参数量为 $\Phi$,加载模型参数所需的显存 = $\Phi \times 精度类型存储量$。目前通常使用半精度部署模型,因此精度类型存储量为 2。如果使用 int4 进行量化,则精度类型存储量为 1/2。
模型参数 + 中间激活所需的总显存占用可通过该估算公式得出(https://kipp.ly/transformer-inference-arithmetic/):
$$
\text{总显存占用}: InferMemory \approx 1.2 \ * \ ModelMemory
$$
在推理阶段,基于 Transformer 的 Decoder-Only 架构可以通过使用 kv cache 技术来加速推理,下面将介绍 kv cache 的显存占用计算。
KV cache 的显存占用
先将相关的变量进行声明,输入序列的长度仍然用 s 表示,输出序列的长度用 n 表示。kv cache 的峰值显存占用大小 = $b * (s + n) * h * l * 2 * 2 = 4blh(s + n)$,这里的第一个 2 表示 k 和 v cache,第二个 2 表示 float16 数据格式存储 kv cache,每个元素占 2 bytes。如果使用 GQA,公式中的 h 还能更小。
示例:
- GPT-3:假设 b = 64,s = 512,n = 32,则 kv cache 占用显存大小为 $4 \times 64 \times 96 \times 12288 \times (512 + 32) = 164,282,499,072 \approx 164GB$。
- Llama3-8B:假设 b = 64,s = 512,n = 32,则 kv cache 占用显存大小为 $64 \times 32 \times 4096 \times (512 + 32) = 4563402752 \approx 4.25GB$。
参考资料
- 分析transformer模型的参数量、计算量、中间激活、KV cache - 回旋托马斯x的文章 - 知乎:https://zhuanlan.zhihu.com/p/624740065
- [LLM]大模型显存计算公式与优化 - kaiyuan的文章 - 知乎:https://zhuanlan.zhihu.com/p/687226668



