特征选择-过滤式选择
过滤式方法先按照某种规则对数据集进行特征选择,然后再训练学习器,特征选择过程与后续学习器无关,这相当于先用特征选择过程对初始特征进行“过滤”,再用过滤后的特征来训练模型。
【某种规则】:按照发散性或相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,从而选择满足条件的特征。
- 特征的发散性:如果一个特征不发散,例如方差接近于 0,也就是说样本在该特征上基本没有差异,那么这个特征对于样本的区分并没有什么用。
- 特征与目标的相关性:特征与目标的相关性越高说明特征的变动对目标的影响较大,因此我们应当优先选择与目标相关性高的特征。
在后续所讲的方法中除方差选择法是基于特征发散性,其余方法均是从相关性考虑。

方差选择法
计算各个特征的方差,然后根据阈值选择方差大于阈值的特征,或者指定待选择的特征数 k,然后选择 k 个最大方差的特征。
方差选择的依据是什么?举个极端的例子,在多分类问题中,如果某特征只有一个取值,那么该特征对分类结果没有任何意义,因为不管取什么值都为 1,单凭该特征是无法区分样本的分类。
需要注意的是,方差选择法只有在特征是离散型时才适用,如果是连续型则需要离散化后才能使用。此外,该方法在实际问题中效果并非很好,参考如下数据集:
1 | A B Y |
特征 A 的方差 4 要大于特征 B 的方差 1.5,但特征 A 对最终分类结果 Y 的区分度明显没有特征 B 好。单看这 6 条数据,特征 A 几乎没有办法区分 Y 是 0 还是 1。因此我们需要明确一个概念,特征值的方差越大不一定对分类结果有更好的区分。关键原因是特征值的方差仅仅只考虑自身的取值,而没有结合最终的分类结果。
【代码实现】:sklearn。
1 | from sklearn.preprocessing import VarianceThreshold |
若不传给 VarianceThreshold() 阈值,则默认移除方差为 0 的特征。同样,我们也可以给 VarianceThreshold() 传递阈值:
1 | X = [[0, 0, 1], [0, 1, 0], [1, 0, 0], [0, 1, 1], [0, 1, 0], [0, 1, 1]] |
关于 VarianceThreshold() 的实现可参考官方 API 传送门
不借助 sklearn 自行实现方差选择法,那么该如何编写代码呢?思路非常简单,先计算每一个特征的方差值,然后依次比对方差值与阈值,选择方差值大于阈值的特征。
1 | def variance_select(data, threshold=0): |
相关系数法
计算各个特征对目标值的相关系数及相关系数的 P 值。
- 相关系数:如何通俗易懂地解释「协方差」与「相关系数」的概念?知乎这篇回答浅显易懂地介绍了协方差以及相关系数,十分推荐。
在机器学习中我们一般采用皮尔逊相关系数来测量两个序列的线性关系,也就是说皮尔逊相关系数只能检测出线性关系,那么对于分类问题的适用性就远低于回归问题,因此相关系数法常用于回归问题。
为什么皮尔逊相关系数只能测量线性关系呢?具体解释可参考这篇博文 传送门。
【代码实现】:我们以 sklearn.datasets 中的波士顿房价数据集为例。
1 | import numpy as np |
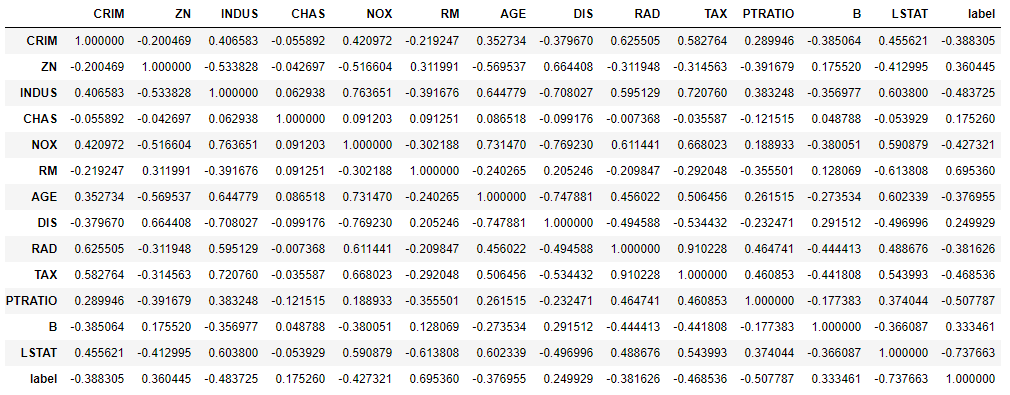
通过 df_dataset.corr(method=’pearson’) 这句指令,我们可以看到各特征两两之间的皮尔逊相关系数。当然我们更关注的是特征与最终要预测的对象(房价)的相关系数。
除了使用 pandas 的 corr(method=’pearson’) 方法之外,我们还可以使用 scipy.stats.pearsonr() 方法。
1 | from scipy.stats import pearsonr |
上述代码分别计算 CRIM、ZN 和 label 之间的相关系数,可以看到输出结果的第一项与 corr(method=’pearson’) 计算的结果相同,不同的是 pearsonr() 方法还多输出了一项 1.1739870821945733e-19 和 5.713584153081686e-17。
scipy.stats.pearsonr() 对给定两个数据序列会返回相关系数值和 p 值所组成的元组。也就是说 1.1739870821945733e-19 和 5.713584153081686e-17 就是这个 p 值,那么 p 值有什么用呢?p 值是该数据序列产生于一个不相关系统的概率,p 值越高,我们越不能信任这个相关系数。
不使用已有的方法自行实现相关系数的计算,依据相关系数的计算公式:
$$
\rho=\frac{\operatorname{Cov}(X, Y)}{\sigma_{X} \sigma_{Y}} \quad Cov(X, Y) = \sum\left(x-m_{x}\right)\left(y-m_{y}\right)
$$
其中,$m_x$ 和 $m_y$ 分别是向量 x 和 y 的均值。
【代码实现】:
1 | def corr(vector_A, vector_B): |
相关系数的取值在 -1 到 1 之间,-1 代表负相关、1 代表正相关、0 代表不相关。
1 | corr(np.array([1, 2, 3, 4, 5]), np.array([1, 4, 7, 10, 13])) |
通过上述示例可以发现,特征与预测值的相关系数值越接近 -1 或 1 时,特征的变化趋势与预测值的变化趋势具有高度的一致性(反向或同向),也就是说这些特征对预测值产生的影响也越大,因此,我们优先选择相关系数绝对值大的特征。
卡方检验法
检验定性自变量对定性因变量的相关性。关于卡方检验的介绍可参考这篇文章 卡方检验原理及应用。需要注意的是,卡方检验适用于分类问题。
【代码实现】:因为卡方检验适用于分类问题,因此以 sklearn.datasets 中的鸢尾花数据集为例。
1 | from sklearn.datasets import load_iris |
卡方值越大,表明特征与预测结果的相关性也越大,同时 p 值也相应较小,因此我们优先选择卡方值大的特征。
互信息法
互信息法与卡方检验法相同,都是评价定性自变量对定性因变量的相关性。互信息用以计算两个特征或自变量与因变量之间所共有的信息。
【区别】:
- 相关性:与相关性不同,互信息计算的不是数据序列,而是数据的分布,因此互信息可以用于检测特征间的非线性关系。
【互信息量计算公式】:离散随机变量 X 和 Y。
$$
I(X ; Y)=\sum_{y \in Y} \sum_{x \in X} p(x, y) \log \left(\frac{p(x, y)}{p(x) p(y)}\right)
$$
其中 p(x, y) 是 X 和 Y 的联合概率分布函数,P(x) 和 p(y) 分别是 X 和 Y 的边缘概率分布函数。
【互信息量计算公式】:连续随机变量 X 和 Y。
$$
I(X ; Y)=\int_{Y} \int_{X} p(x, y) \log \left(\frac{p(x, y)}{p(x) p(y)}\right) d x d y
$$
其中 p(x, y) 是 X 和 Y 的联合概率密度函数,p(x) 和 p(y) 分别是 X 和 Y 的边缘概率密度函数。
根据公式可以看出,若 X 与 Y 完全独立,则 p(X, Y) = p(X)p(Y),I(X, Y) = 0。也就是说 I(X, Y) 越大,则表明 X 与 Y 的相关性越大。
互信息 I(X, Y) 可以解释为由 X 引入而使 Y 的不确定度减小的量,这个减小的量为 H(Y|X)。所以,X 和 Y 关系越密切,I(X, Y) 就越大。
sklearn 提供依据互信息来挑选特征的方法,并且既可以解决分类问题,也可以解决回归问题。
【代码实现】:回归问题
1 | from sklearn.feature_selection import SelectKBest |
【代码实现】:分类问题
1 | from sklearn.feature_selection import SelectKBest |
基于模型的特征排序
该方法的思路同包裹式选择,直接使用后续要用的机器学习算法,针对每个单独的特征和预测值建立预测模型。
【步骤】:
- 判断特征和预测值之间的关系,若为线性则考虑线性算法;若为非线性,则考虑非线性算法,例如基于树模型的方法;
- 单独采用每个特征进行建模,并进行交叉验证;
- 选择指定个数评分最高的特征,组成特征子集。
【代码实现】:以鸢尾花数据集为例,模型以决策树为例。
1 | from sklearn.datasets import load_iris |
当然我们也可以指定不同的评分标准:
1 | score = cross_val_score(model_dtc, data_iris[:, i:i+1], target_iris, cv=kfold, scoring='adjusted_mutual_info_score') |
最终,根据评分标准选择最优的特征,组成特征子集。
Relief
Relief(Relevant Features)是一种著名的过滤式特征选择方法,该方法设计了一个“相关统计量”来度量特征的重要性。该统计量是一个向量,其每个分量分别对应于一个初始特征,而特征子集的重要性则是由子集中每个特征所对应的相关统计量分量之和来决定。
【选择方式】:
- 指定一个阈值 r,然后选择比 r 大的相关统计量分量所对应的特征即可;
- 指定要选取的特征个数 k,然后选择相关统计量分量最大的 k 个特征。
【关键】:如何确定相关统计量。
给定训练集 ${(x_1, y_1), (x_2, y_2), \cdots, (x_n, y_n)}$,对每个实例 $x_i$,Relief 先在 $x_i$ 的同类样本中寻找其最近邻 $x_{i,nh}$,称为“猜中近邻”(near-hit),再从 $x_i$ 的异类样本中寻找其最近邻 $x_{i,nm}$ 称为“猜错近邻”(near-miss),然后,相关统计量对应于特征 j 的分量为
$$
\delta^j = \sum_{i=1}^n -diff(x_i^j, x_{i,nh}^j)^2 + diff(x_i^j, x_{i, nm}^j)^2
$$
其中 $x_a^j$ 表示样本 $x_a$ 在特征 j 上的取值,$diff(x_a^j, x_b^j)$ 取决于特征 j 的类型:
- 若特征 j 为离散型,则 $x_a^j = x_b^j$ 时,$diff(x_a^j, x_b^j) = 0$,否则为 1;
- 若特征 j 为连续型,则 $diff(x_a^j, x_b^j) = |x_a^j - x_b^j|$,注意 $x_a^j, x_b^j$ 已规范化到 [0, 1] 区间。
从上式中可以看出,若 $x_i$ 与其猜中近邻 $x_{i,nh}$ 在特征 j 上的距离小于 $x_i$ 与其猜错近邻 $x_{i, nm}$ 的距离,则说明特征 j 对区分同类与异类样本是有益的,于是增大特征 j 所对应的统计量分量;反之,若则说明特征 j 起负面作用,于是减小特征 j 所对应的统计量分量。
最后,对基于不同样本得到的估计结果进行平均,就得到各特征的相关统计量分量,分量值越大,则对应特征的分类能力就越强。
实际上 Relief 只需在数据集的采样上而不必在整个数据集上估计相关统计量。Relief 的时间开销随采样次数以及原始特征数呈线性增长,因此是一个运行效率很高的过滤式特征选择算法。
Relief 是为二分类问题设计的,其扩展变体 Relief-F 能处理多分类问题。
【Relief-F】:假定数据集 D 中的样本来自 |Y| 个类别。对实例 $x_i$,若它属于第 k 类,则 Relief-F 先在第 k 类的样本中寻找 $x_i$ 的最近邻实例 $x_{i, nh}$ 并将其作为猜中近邻,然后在第 k 类之外的每个类中找到一个 $x_i$ 的最近邻实例走位猜错近邻,记为 $x_{i,l,nm}(l = 1, 2, \cdots, |Y|; l \neq k)$。于是,相关统计量对应于特征 j 的分量为
$$
\delta^j = \sum_{i=1}^n -diff(x_i^j, x_{i,nh}^j)^2 + \sum_{l \neq k}(p_l \times diff(x_i^j, x_{i,l,nm}^j)^2)
$$
其中,$p_l$ 为第 l 类样本在数据集 D 中所占的比例。
参考
- 《机器学习》周志华
- 《百面机器学习》
- 特征选择:https://blog.csdn.net/shingle_/article/details/51725054
- 特征选择 (feature_selection):https://www.cnblogs.com/stevenlk/p/6543628.html#%E7%A7%BB%E9%99%A4%E4%BD%8E%E6%96%B9%E5%B7%AE%E7%9A%84%E7%89%B9%E5%BE%81-removing-features-with-low-variance
- SelectKBest:https://blog.csdn.net/weixin_33962923/article/details/87837426
- 如何通俗易懂地解释「协方差」与「相关系数」的概念?:https://www.zhihu.com/question/20852004
- 卡方检验原理及应用:https://segmentfault.com/a/1190000003719712
- 互信息:https://www.cnblogs.com/gatherstars/p/6004075.html



