论文阅读:A Survey on Data Selection for LLM Instruction Tuning
指令调整是训练大语言模型(LLM)的重要步骤,因此如何提高指令调整的效果受到越来越多的关注。现有研究表明,在 LLM 的指令调整过程中,数据集的质量比数量更为重要。因此,进来很多研究都集中于探索从指令数据集中选择高质量子集的方法,旨在降低训练成本并增强 LLM 的指令遵循能力。本文对用于 LLM 指令调整的数据选择进行了全面研究。首先,介绍了常用的指令数据集。然后,提出了新的数据选择方法分类法,并详细介绍了最新进展,还详细阐述了数据选择方法的评估策略和结果。最后,强调了这一任务所面临的挑战,并提出了新的研究领域。
2. 指令集
由 LLM 生成的各种指令调整数据集(如 Self-Instruct 和 Alpaca)无需人工即可提供丰富的样本,但其数据质量取决于 LLM 的性能,并具有不确定性。相反,人工编辑的数据集(如 LIMA 和 Dolly)通过精心的人工选择获得了更高的质量,但也可能受到人为偏见的影响。其他数据集构建方法,如即时映射(prompt mapping)和进化构建(evol-instruct),旨在提高数据集的质量和多样性,但也给质量保证带来了新的挑战。数据集构建和来源的这种差异性极大地影响了数据质量,凸显了谨慎选择数据对于 LLM 指令调整的重要性。本节将介绍几种常用指令调整数据集的规模和构建程序。
- Self-instruct:由 [Wang等人,2023] 创建的 Self-instruct 由52,000条训练指令和252条测试指令组成。使用 InstructGPT [欧阳等人,2022b] 对种子任务中的初始指令进行选择、分类和多样化,通过输出优先或输入优先策略生成输入和输出。后处理完善了数据集的独特性和相关性,为自然语言处理应用提供了多功能资源。
- Alpaca:由 [Taori等人,2023] 创建,包含52,002个样本,用于微调 LLaMA 的指令遵循能力。基于[Wang 等人,2023]的技术,样本是通过使用 text-davinci-003 生成的。
- WizardLM:由 [Xu等人,2023a] 创建,由进化算法生成的25万个样本组成。两种算法(深度进化和广度进化)用于提高基本指令的复杂性和范围,通过 ChatGPT 生成更复杂、更多样的高质量指令数据。
- LIMA:由 [Zhou等人,2023a] 创建,由1000个训练样本、300个测试样本和50个开发样本组成。除了人工撰写的样本外,从问答网站收集的样本也经过严格的人工筛选。尽管 LIMA 的规模不大,但其精心的编译和设计却非常突出。在 LIMA 上经过微调的 LLM 在遵循指令和适应未知任务方面表现出了非凡的能力。
- Dolly-v2:由 [Conover 等人,2023] 创建,包含 15,000 条指令,涉及头脑风暴、分类、QA 和总结等各种任务。员工手动撰写(提示、回复)对。他们只能使用维基百科,建议他们不要使用网络资源或生成式人工智能来制作回复。
- P3:由 [Sanh等人,2022年] 创建,集成了170个NLP数据集和2,052个提示。这些提示(也称为任务模板)将传统的 NLP 任务(如问题解答或文本分类)转换为自然语言输入-输出对。P3 数据集本身是通过从 PromptSource 中随机选择提示语,并将数据组织成输入、答案选择和目标的三元组而形成的。
3. 数据选择方法
形式上,定义一个大小为 n 的指令数据集 X,其中$$X = {x_1, x_2, \ldots, x_n}$$,每个$$x_i$$代表一个指令微调数据实例。从 X 中采用特定的指令数据选择方法$$\pi$$,并选择大小为 m 的子集$$S_{\pi}^{(m)}$$,然后使用预定义的评价指标 Q 来评估$$S_{\pi}^{(m)}$$的质量。通过评价指标衡量获得的子集质量,可以衡量所选指令数据选择方法的有效性。设计选择方法的过程可以看作是:
$$
S_{\pi}^{(m)} = \pi(X) \tag{1}
$$
$$
\pi^{*}=\arg \max {\pi} Q\left(S{\pi}^{(m)}\right) \tag{2}
$$
指令数据选择方法的分类基于该方法使用的评分规则和模型基础。这些方法可分为以下四类:基于指标体系的方法、可训练的 LLM、功能强大的 LLM(如 ChatGPT)和小型模型。
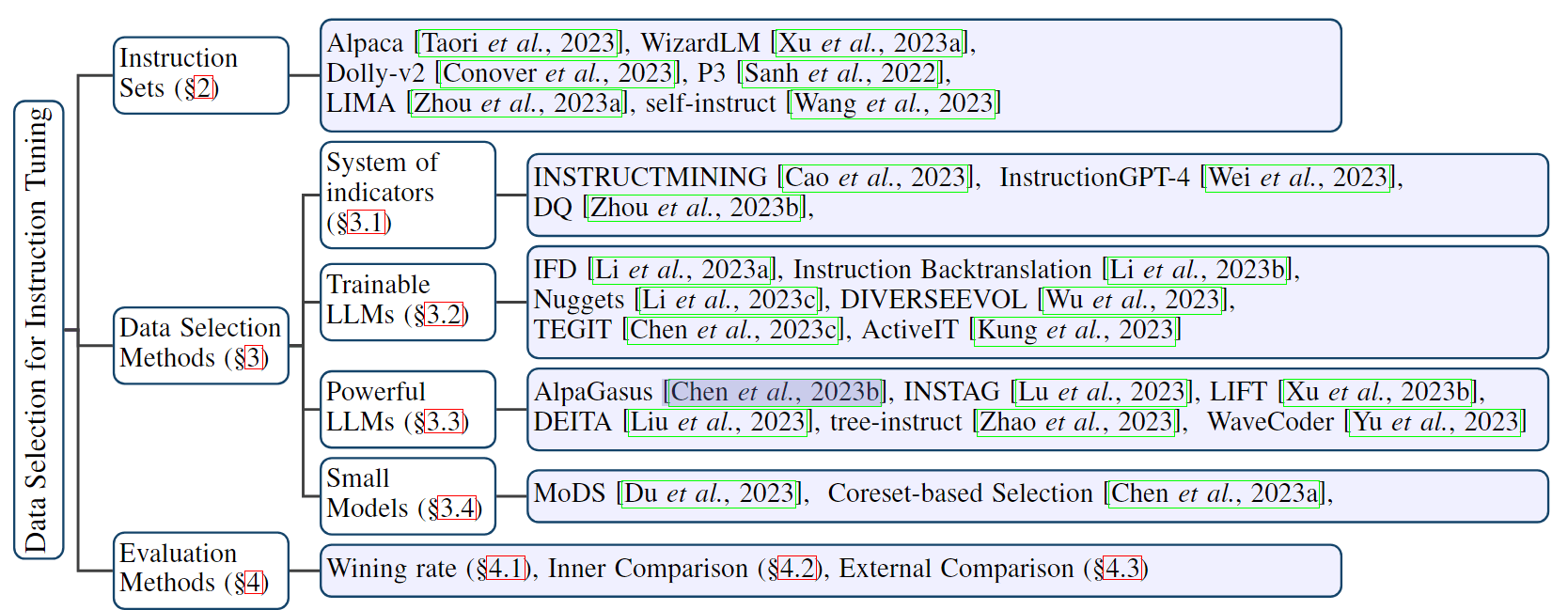
图 1:用于 LLM 指令调整的数据选择概览。
3.1 基于指标体系的方法
采用度量集系统的方法可直接识别多个度量$$I_1, I_2, \ldots, I_n$$,从而建立一套全面的度量标准。这组指标中的每个指标都由特定的计算公式定义。值得注意的是,某些指标可能会利用深度学习技术从数据集中提取特征,而深度学习技术本质上就是指标形式。这些度量标准有助于计算数据实例的个人得分,即$$score_{ij} = I_i(x_j)$$。这些分数有助于开发更强大的度量集系统。
$$
score_j = G(I_1(x_j), I_2(x_j), \ldots, I_n(x_j)) \tag{3}
$$
一旦建立,就可以直接利用度量集系统为数据集 X 中的每个数据实例计算分数。通过建立合适的阈值,该系统有助于根据各自的分数选择性地纳入数据:
$$
S_{\pi} = { x | G(x) \gt \tau} \tag{4}
$$
[Cao等人,2023年] 介绍了 INSTRUCTMINING,一种基于线性规则的指令数据质量评估方法。该方法首先确定关键的自然语言指标,如指令长度、复杂度、奖励分数、KNN-i [Reimers 和 Gurevych,2019;Dong 等人,2011] 等。这些指标随后被用来建立线性方程。为了探索数据质量与这些指标之间的相关性,并确定方程的参数,作者进行了全面的微调实验。不同质量的数据集被分割成若干子集,然后合并起来,用于大规模模型的微调。通过评估模型在测试集上的性能,得出每个子集的质量标签。最小二乘法适用于这些实验结果,以估计 INSTRUCTMINING 中的参数。一旦参数确定,就可以利用该公式计算指令的质量,从而方便数据选择。
[Wei等人,2023年] 提出了用于多模态大型模型微调的数据选择方法 InstructionGPT-4。它在使用较少数据的各种评估中超过了 MiniGPT-4。第一步,使用 CLIP 分数[Radford 等,2021]、指令长度等指标。将视觉和文本数据编码成向量,然后进行降维处理,这被视为特殊指标。这些指标被组合成一个向量。然后将向量输入可训练的数据选择器,如多层感知器或自我注意网络。这种方法在计算质量标签方面与 [Cao 等人,2023] 相似,采用聚类算法来分割数据集。在对每个子集进行微调和评估后,再分配质量标签。
[Zhou等人,2023b] 介绍了 DQ 方法,这是一种创新的数据压缩技术,适用于大规模计算机视觉数据集,但它也被调整用于 LLM 领域。
3.2 基于可训练 LLMs 的方法
本节概述了在数据选择过程中使用可训练 LLM(如 LLaMa)来开发计算公式的情况。作为可训练的数据选择器,LLM 对每条指令微调数据进行处理并分配分数。
$$
score_i = LLM_{trainable}(x_i) \tag{6}
$$
这种方法不仅专注于分析单个指令,还强调了数据选择与微调所用大模型功能同步的必要性。后续章节将详细介绍具体方法。
[Li 等人,2023a] 提出了 From Quantity to Quality: Boosting LLM Performance with Self-Guided Data Selection for Instruction Tuning(IFD)方法,该方法认为 LLM 最初可以学会从精心挑选的数据中识别指令,从而增强其评估更广泛数据集质量和估计指令执行难度的能力。最初,该方法涉及在指令数据集的一个小型聚类子集上对 LLM 进行微调,以培养基本的指令遵循技能。随后,引入了一个新的指标——“指令执行难度(IFD)”,用于评估对特定指令做出反应的难度。IFD 比较的是在没有特定指令的情况下的回答质量。
[Li 等人,2023b] 提出了 Self-Alignment with Instruction Backtranslation 方法,一种用于生成和过滤指令的方法——指令回译。从基线指令遵循模型和网络语料库开始,该模型为每个网络文档生成指令,形成一个数据集。然后利用种子指令对模型进行微调,以获得基本能力。它还会对每条指令进行自主评分,超过设定阈值的指令会形成高分子集,以便进一步微调。这种迭代过程提高了指令生成和过滤效率。
[Li等人,2023c]提出了Nuggets框架,该框架采用双阶段方法。首先,它采用各种预定义任务来评估 LLM 在多个场景中的熟练程度,这一过程被称为 zero-shot 评分。随后,指令数据集中的每个元素都会被用作 one-shot 的独特 prompt。这些 prompt 会在预定任务之前出现,并对 LLM 的表现进行重新评估,这一步骤被称为 one-shot 评分。这种方法利用 one-shot 评分和 zero-shot 评分之间的差距,为每条指令计算出明确的“黄金评分”。在获得所有指令的黄金分数后,得分最高的子集将被选为“黄金子集”。然后直接使用该子集对模型进行微调。这种方法利用了广泛模型固有的上下文学习能力。
[Wu 等人,2023 年] 引入了 Self-Evolved Diverse Data Sampling for Efficient Instruction Tuning DIVERSEEVOL 机制,这是一种创新的迭代数据选择策略。它利用 LLaMa 等大模型为指令数据生成嵌入向量。该机制采用 k-center-greedy,以促进选择数据子集的多样性,从而对 LLaMa 模型进行微调。这一过程会重复应用,逐步扩大所选子集,最终创建出高质量的指令数据集。
[Chen 等人,2023c] 提出了 TEGIT 方法,提供了一种生成优质指令微调数据的新方法。特别值得一提的是他们过滤指令数据的方法。利用 ChatGPT,一个小型文档语料库被转换成适合指令数据的格式,形成一个元数据集。然后,该数据集用于训练两个 Llama2 模型——一个作为任务生成器,另一个作为任务判别器。生成器的作用是根据提供的文本设计任务,而鉴别器则对这些任务进行评估,确保其质量。
[Kung 等人,2023 年] 提出了“主动指令调整”(Active Instruction Tuning)方法,这是一种侧重于任务敏感性选择的独特方法,其目标是利用更少的任务来加强大型模型的微调,同时提高任务外的泛化能力。该技术引入了“prompt 不确定性”的概念,通过随机删除原始指令中的单词来生成 k 个扰动指令,从而确定“prompt 不确定性”。然后对这 k 个扰动指令的 LLM 概率偏差输出进行平均。利用提示不确定性的程度作为任务不确定性的衡量标准,优先对提示不确定性较高的任务进行指令微调。
3.3 基于强大 LLM(如 ChatGPT)的方法
本节将介绍使用 GPT-4 和 ChatGPT 等功能强大的 LLM 作为数据选择器的方法。该方法主要涉及设计 prompt 模板和利用 LLM 的功能来评估指令数据的质量。
$$
S_{\pi} = { x | ChatGPT(score | prompt, x), score > \tau } \tag{9}
$$
[Chen等人,2023b]提出的 ALPAGASUS 是一种创新的数据过滤方法,旨在提高指令遵循任务(IFT)数据整理的效率和准确性。这种方法利用精心设计的应用于 ChatGPT prompt 来评估每个数据元组(包括指令、输入和响应)的质量。该方法的重点是排除低于预定义质量阈值的元组。在对大量数据集进行过滤时,发现相当一部分数据存在质量问题。值得注意的是,在应用基于 LLM 的过滤过程后,开发出的模型性能超过了使用未过滤数据集和基于指令的微调训练出的原始模型。
[Lu 等人,2023 年] 介绍了一种自动指令标注方法(INSTAG),该方法利用 ChatGPT 为指令生成详细的开放式标签,并证明子集的多样性和复杂性。这一过程包括用反映每条指令语义和意图的标签对数据进行注释,并将其归一化,以用于基于标签的选择方法。这种方法采用复杂性优先的多样化采样策略。
- 首先,它按照标签数量降序对查询进行排序;
- 然后根据标签的唯一性将查询迭代添加到一个子集中,直到子集达到所需的大小 N。
为了提高数据集的分布和质量,[Xu 等人,2023b] 提出了减少样本冗余的 LIFT 方法。它包括两个阶段:扩大数据集的分布和提高数据集的多样性和质量。最初,ChatGPT 通过生成不同的指令并对其进行向量化来增强数据。然后根据行方差选择一个子集。其次,ChatGPT 会对指令的准确性、可解释性、清晰度、难度和长度进行评分。根据这些分数重新选择初始子集。
[Liu 等人,2023] 介绍了 DELTA 方法,该方法综合了选择指令数据的多方面方法,侧重于复杂性、质量和多样性。复杂性描述了指令的长度、难度和复杂性等因素。而质量则反映了输出的准确性。利用 WizardLM 技术,ChatGPT 被用来增强指令,然后对其复杂性和质量进行评估。这些评估包括使用经过专门训练的复杂性评分器,根据复杂性对指令进行评分,并评估输出质量。数据集中的每条指令都会被分配复杂性分数(c)和质量分数(q),并通过将这两个指标相乘计算出综合分数。然后,根据这些综合得分对数据集进行整理,并进行矢量化,以便进一步分析。为确保多样性,在创建子集时,会添加与子集中最近邻距离超过设定距离阈值(τ)的样本。这个过程一直持续到子集达到预定大小为止。
[Zhao等人,2023] 提出了 tree-instruct 法,通过提高指令的复杂度来提高指令的质量。[Liu等人,2023年] 使用这种方法来测量指令复杂度,并为指令过滤设置阈值。Tree-instruct 采用 GPT-4 为指令数据生成语义解析树,用树上的节点数来衡量复杂度。通过在树上添加节点来提高复杂度,然后使用 GPT-4 将新的树转换回自然语言,从而生成新的高质量指令。
[Yu 等人,2023 年] 提出了 WaveCoder,这是一种通过指令改进技术增强的以代码为中心的 LLM。它的训练结合了生成的数据,其中数据过滤阶段尤为重要。在生成数据后,基于 LLM 的判别器利用 GPT-4 根据分成子主题的既定标准对指令数据进行评估。这种方法能对过滤过程进行更精细的控制,有效地消除低质量的指令实例。
3.4 基于小模型的方法
本节介绍的方法涉及使用外部小模型作为评分器,或使用小模型将指令转换为嵌入向量,然后进行进一步处理。一般来说,这些方法都比较全面。小模型的评分过滤或嵌入生成通常只是整个方法过程的一部分。
[Du等人,2023年]介绍了MoDS:Model-oriented Data Selection for Instruction Tuning方法,重点是通过三个标准选择指令:质量(指令数据的保真度)、覆盖面(指令类型的多样性)和必要性(指令对LLM微调的影响)。这一过程分为四个关键步骤:
- 首先,采用奖励模型来评估指令数据集的质量,选择一个子集(记为$$D_h$$),由超过预定质量阈值的指令组成;
- 其次,利用 k-center-greedy 算法来识别种子指令,从而确保指令数据集样本的多样性和代表性。
- 第三,使用种子指令对预训练的 LLM 进行微调。随后,将这一改进后的模型应用于$$D_h$$,生成新的数据集$$D_{inference}$$。然后使用奖励模型对该数据集进行评估,该模型通过关注得分较低的指令来识别对学习 LLM 至关重要的指令。
- 最后,种子指令与增强指令数据组成高质量指令子集,以促进 LLM 的有效微调。
Maybe only 0.5% Data is Needed: A Preliminary Exploration of Low Training Data Instruction Tuning 提出了一种基于核心集且与任务相关的数据选择方法:首先,通过预训练的语言模型(如BERT)获取样本的句子嵌入,然后通过对这些嵌入进行无监督聚类来选择中心点,最后使用KCenterGreedy 算法从给定数据集中检索核心样本。这种方法能有效减少所需的训练数据量,保持或可能提高模型性能。
4. 评估方法和结果分析
数据选择方法的有效性取决于从给定数据集中筛选出的子集的质量。为了衡量子集的质量,采用不同的方法在不同的基准上对子集上微调的 LLM 进行评估,这些基准可分为三类:胜率、内部比较和外部比较。
4.1 胜率
为了评估数据集选择方法的有效性,与基本 LLM 相比,LLM-sub 的胜率计算公式为:
LLM-sub 表示对通过选择方法从训练集中筛选出的子集进行微调的 LLM,而基本 LLM 通常包括两种类型:i) 对整个训练集进行微调;ii) 对通过常规选择(如随机抽样和指令长度)筛选出的同比例子集进行微调。在公式 10 中,Num(win) 表示测试基准中获胜案例的数量,Num(lose) 表示测试基准中失败案例的数量,Num(all) 表示测试基准中所有案例的数量。
LLM-sub 和基本 LLM 的输出由评委按 1 到 10 的等级进行评分,通常采用 GPT4 作为评委。为了解决评委的位置偏差问题,[Li 等人,2023a] 将这两个 LLM 的输出以不同的顺序两次发送给评委。根据[Li 等人,2023a],获胜的情况是指 LLM-sub两次都优于基本 LLM,或一次获胜而另一次打平。失败案例指的是 LLM-sub两次都落后于基础 LLM,或者一次打平,另一次失败。表 1 总结了不同选择方法在测试基准上的胜率。
4.2 内部比较
为了简单直接地评估数据集选择方法的有效性,作者将 LLM-sub 与相同的 LLM 进行了比较,但 LLM-sub 是在整个训练集或经过常规选择过滤的相同规模子集上进行微调的。作者将这种评估方法称为内部比较,因为它只将在子集上微调过的 LLM 与自身进行比较。
表 2 总结了不同选择方法在测试基准上的内部比较性能。
4.3 外部比较
另一种简单明了的评估方法是外部比较法,即在不同测试基准上将 LLM-sub 与外部 LLM(即不同于 LLMsub 的模型)进行比较。表 3 总结了不同选择方法在测试基准上的外部比较性能。
4.4 结果分析
所提出的选择方法优于常规选择方法,这证明了数据选择在指令调整中的重要性。如表 1 和表 2 所示,在混合数据集上调整 llama-13b 时,TAGLM-13b-v1.0 和 IFD 在 MT-bench 上优于基于指令长度和随机抽样的常规选择;在 alpaca 数据集上微调 llama-7b 时,Alpagsaus 和 IFD 在总 WS 上优于随机抽样。
更先进的 LLM(llama2-7b)比标准 LLM(llama-7b)取得了更高的性能,两者都在相同的子集上进行了微调。表 3 显示,TAGLM-13b-v2.0 优于 TAGLM-13b-v1.0;表 1 显示,采用 IFD 选择方法时,llama2-7b(5%) 优于 llama-7b(5%)。这些改进归因于高级 LLM 本身的复杂性,从而提高了子集的学习效率。
在更大的子集上对特定 LLM 进行指令调整并不一定能保证性能的提高。这可能与选择方法的固有特征有关。如表 1 所示,在训练集 alpaca 应用 IFD 方法时,随着子集规模的扩大,llama-7b 的性能并没有提高。但是,当在同一训练集中使用 Alpagsaus 方法时,随着子集规模的增加,llama-7b 的性能会有所提高。
5. 总结和开放式挑战
本文全面概述了指令调整数据选择的方法和挑战,强调了高质量数据在微调阶段的关键作用。作者展示了一些现有的数据集及其相应的构建方法。这些数据集存在数据分布不平衡和数据质量不一致等问题。在此基础上,作者介绍了现有的四种数据选择方法。仅依靠度量集的方法可以有效评估单个数据的质量,但缺乏对复杂数据集特征的考虑。设计评分公式的可训练大型模型方法可以选择适合 LLM 本身的数据,而使用 GPT-4 等外部强大 LLM 进行评分的方法则具有卓越的数据选择能力。此外,利用小型模型的方法通常设计有多个模块,考虑到各个方面。最后,介绍了如何评估数据选择方法,包括胜率、内部比较和外部比较。尽管现有方法取得了值得称赞的性能,但仍存在一些挑战。
目前明显缺乏统一的评估标准。在第 4 节中,介绍了有关 LLM 的多种评估方法和各种基准。各种数据选择方法通常会选择不同的评价标准,这给确定哪种方法更具优势造成了相当大的困难。未来的研究可以致力于为选择方法建立一种合理、全面和自动的评价方法,从而统一方法的评价过程。
事实证明,处理海量数据往往效率低下,而且严重依赖功能强大的 LLM。当要过滤的指令数据集规模过大时,现有方法的处理时间通常过长,尤其是在使用 LLMs 提取指令特征或执行相关度量计算时。使用 LLM 处理数十万条指令数据可能非常耗时。此外,如果使用 GPT4 API 等功能强大的 LLM 处理数十万条指令,成本也会非常高。未来的工作应探索使用更小的模型,并努力与 LLM 的选择能力相匹配。
现有的数据质量评估模型和方法主要集中在英语和一般领域,缺乏其他语言的模型和特定领域的选择方法。未来的研究应探索其他语言的指令质量评估模型,并研究特定任务选择方法的设计。未来的研究应探索其他语言的指令质量评估模型,并研究设计针对特定任务的选择方法,从而提高各种方法在不同规模、领域和语言的指令集中的性能。