论文阅读:Albert:A Lite Bert for self-supervised learning of language representations
- 发布日期:Sep 2019
- 发布期刊:
- 作者列表:ZhenZhong Lan、Mingda Chen、Sebastian Goodman、Kevin Gimpel、Piyush Sharma、Radu Soricut
- 论文链接:https://arxiv.org/abs/1909.11942
速读
Q1:论文试图解决什么问题?
针对目前预训练模型规模越来越大、训练时间越来越久的现状,作者提出了一个新的模型 Albert,在减少模型参数量的同时,却能够在 GLUE 等评估基准上达到并超过当前最佳。
Q2:论文中提到的解决方案之关键是什么?
作者提出了两种减少参数的技术,来降低模型占用的内存量、并提高模型的训练速度:
- 因式分解嵌入参数
- 跨层参数共享
此外,作者还提出了一种自监督的 loss——SOP,用以替代原始 BERT 中的 NSP 任务。SOP 着重于对句子间的连贯性进行建模。
Q3:代码有没有开源?
https://github.com/google-research/albert
Q4:这篇论文到底有什么贡献?
- 提出了一个新的 BERT-like 架构,该架构采用了因式分解嵌入参数和跨层参数共享技术来降低模型占用的内存量,但需要注意的是模型的推断速度并没有加快。此外,并使用 SOP 任务替换了 NSP 任务。
- 作者详尽的实验证明了因式分解嵌入参数和跨层参数共享技术能够减少参数量,尤其是跨层参数共享。这也从侧面证实了 self-attention 注意力头过剩。在 SOP 任务的实验过程中,指出 NSP 任务存在主题预测的问题,并没有真正对句子间的关系进行建模。
- 探究了网络深度和宽度对模型性能的影响。
摘要
在预训练自然语言表征时,增加模型规模通常可以改善下游任务的性能。然而,由于 GPU/TPU 内存的限制和训练时间的增加,在某些时候,提升模型变得越来越难。为了解决这些问题,作者提出了两种减少参数的技术,来降低模型占用的内存量,并提高 BERT 的训练速度。实验结果证明,与原始 BERT 相比,作者提出的方法让模型的扩展性更好。此外,作者还使用了一种自监督的 loss,该 loss 着重于对句子间的连贯性进行建模,并表明它始终可以帮助到输入多个句子的下游任务。
Albert 在 GLUE、RACE 和 SQuAD 基准上取得了最佳的结果,同时与 BERT-large 相比,参数更少。
Albert 的元素
在这一节中,作者提出了 Albert 的设计决策,并提供了与原始 BERT 体系结构相应配置的量化比较。
模型架构选择
Albert 架构的主干与 Bert 相似,并遵循 Bert 的标记约定:词嵌入大小表示为 E,编码器层数表示为 L,隐藏层大小表示为 H。作者将前馈/过滤器的大小设置为 4H,注意力头的数量设置为 H/64。
Albert 对 BERT 的设计决策作出了三点主要贡献:
- Factorized embedding parameterization
- Cross-layer parameter sharing
- Inter-sentence coherence loss
其中,因式分解嵌入参数和跨层参数共享作为两种参数减少技术,可消除扩展预训练模型时的主要障碍。
因式分解嵌入参数
在 BERT 以及随后发布的新模型,例如 XLNet 和 RoBERTa 中,WordPiece embedding 大小 E 与隐藏层大小 H 绑定在一起,即 E = H。出于建模和实际原因,此决策似乎欠优,理由如下:
- 从建模角度看:WordPiece embedding 旨在学习与上下文无关的表征,而隐藏层 embedding 旨在学习与上下文相关的表征。正如关于语境(上下文)长度实验所表明的那样(Liu 等人),类似 BERT 的表征的力量来自于使用语境来提供学习这种依赖语境的表征的信息。因此,将 WordPiece embedding 的维度 E 与隐藏层的维度 H 分开,可以使我们更有效地使用总的模型参数,这是由建模需求决定的,H >> E。
- 从实际角度看:NLP 通常要求词汇量 V 要大(与 BERT 相同,本文的所有实验都使用了 30000 的词汇量)。如果 E = H。那么增加 H 就会增加 embedding 矩阵的大小,即 V x E。这很容易形成一个具有数十亿个参数的模型,其中大部分参数在训练期间只被稀疏地更新。
因此,对于 ALBERT,作者对 embedding 参数进行分解,将它们分解为两个较小的矩阵。与其直接将 one-hot 向量直接投影到维度为 H 的隐藏层空间中,不如将它们投影到维度为 E 的低维嵌入空间中,然后再将其投影到隐藏层空间中。
通过这种分解,作者将 embedding 参数从 O(V x E) 减少到 O(V x E + E x H)。当 H >> E 时,此参数减少的意义重大。作者选择对所有 word pieces 使用相同的 E,因为与 whole-word embedding 相比,所有 word pieces 在文档中的分布要均匀得多,在 whole-word embedding 中,不同词语的 embedding size 非常重要。
对于 BERT,词向量维度 E 和隐藏层维度 H 是相等的。在 Large 和 XLarge 等更大规模的模型中,E 会随着 H 不断增加。作者认为没有这个必要,因为预训练模型主要的捕获目标是 H 所代表的“上下文相关信息”,而不是 E 所代表的“上下文无关信息”。“Factorized”说白了就是在词表 V 到隐藏层 H 的中间,插入了一个小维度 E,多做一次尺度变换。
嵌入层矩阵分解并非参数量减少的主要功臣,假设词表包含 3w 个词语,最长序列长度为 512,把 word embedding 和 position embedding 都算进来,Bert-large 在这一块的参数量约为 (3w + 512) x 1024 = 31244288,Albert-large 的参数量约为 (3w + 512) *128 + 128 * 1024 = 4036608,只有 27M。
嵌入层矩阵分解相当于词向量压缩。
—— 选自 小莲子 的评论。
词向量容易压缩是早就知道的事实,例如 massive exploration of neural machine translation architectures 中的结果就表明词向量搞个 2048 维相比 512 维提升不大。道理很简单:词向量只要能把相似单词聚在一起就完成了它的任务。即便词向量只有 100 维,并且每个维度只能取 {0, 1} 两个值,整个词向量空间也可以编码 2 ^ 100 个不同的单词,把几万个单词嵌入到这个空间里绰绰有余。Transformer 输入输出维度相同我觉得主要还是大家懒(这可不是 RNN 只有两三层,动不动要堆十几二十几层的,全搞成一样的比较省事),真到较真儿的时候一刀砍下去立竿见影,而隐藏层相对就比较难砍了,如果用矩阵分解的方法来做,砍多了影响效果,砍少了节省不了是参数可能还增加延迟,对刀法要求很高。
—— 选择 Towser 的评论
跨层参数共享
对于 ALBERT,作者提出了跨层参数共享作为提高参数效率的另一种方法。关于参数共享有多种方式,例如:
- 跨层共享前馈网络(FFN)参数。
- 跨层共享注意力层参数。
ALBERT 默认跨层共享所有参数。除非另有说明,否则本篇论文的所有试验均使用此默认策略。
Dehghani 等人(Universal Transformer,UT)和 Bai 等人(Deep Equilibrium Models,DQE)也探索了类似的策略,用于 Transformer 网络。与作者的观察结果不同,Dehghani 等人显示 UT 的性能优于 vanilla Transformer。Bai 等人表明,他们的 DQE 达到了平衡点,对于该平衡点,特定层的输入和输出 embedding 保持不变。
作者对 L2 距离和余弦相似度的测量表明:ALBERT 的 embedding 是振荡的,而不是收敛的。
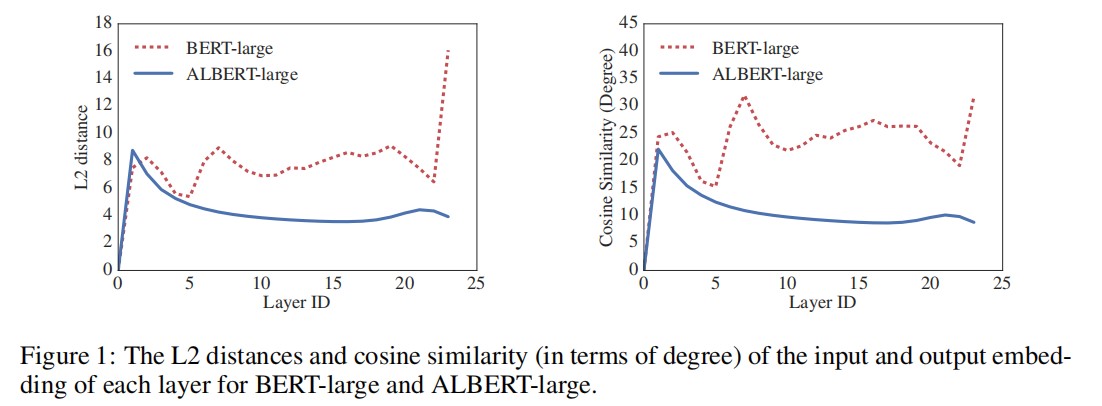
图 1 显示了使用 BERT-large 和 ALBERT-large 配置的每层输入和输出 embedding 的 L2 距离和余弦相似度(请参见表 1)。我们观察到,与 BERT 相比,ALBERT 的逐层过渡要平滑得多。这些结果表明,权重共享对稳定网络参数有影响。尽管与 BERT 相比,这两个指标都有所下降,但是即使经过 24 层,它们也不会收敛到 0。这表明 ALBERT 参数的解决方案空间与 DQE 找到的解决方案空间有很大不同。
参数量减少的大杀器来了——共享所有层的参数。具体分为三种模式:只共享 attetion 相关参数、只共享 FFN 相关参数、共享所有参数。

“all-shared”之后,Albert-base 的参数量直接从 89M 变成了 12M,毕竟这种策略就相当于把 12 个完全相同的层摞起来。从最后一列的 Avg 来看,如果是只共享 attention 参数,不仅可以降维,还能保持性能不掉。然而,作者为了追求“轻量级”,坚持把 FFN 也共享了。那掉了的指标从哪里补?答案之一就是把 Albert-large 升级为 Albert-xxlarge,进一步加大模型规模,把参数量再加回去。全文学习下来,这一步的处理是我觉得最费解的地方,有点为了凑 KPI 的别扭感觉。
—— 选自 小莲子 的评论。
这也从侧面证明了注意力头过剩,我们完全可以对训练好的模型的注意力头进行剪枝,从而降低模型的参数量,并且不会降低太多的性能。
—— 我的理解
句间连贯性损失
除了 MLM loss 之外,BERT 还使用了另一种 loss,称为 NSP loss。NSP 是一个二分类 loss,用于预测两个文本片段在原始文本中是否连续出现(即上下文关系)。操作过程如下所示:先从训练语料库中获取连续片段来创建正样本,然后将不同文档中的句子进行配对来创建负样本。正样本和负样本均以相同的概率采样。
NSP 旨在提高下游任务(例如 NLI)的性能,这些任务需要推理句子对之间的关系。但是,随后的研究发现 NSP 的影响不可靠,因此决定消除它,这一决定得到了多项下游任务性能改进的支持。
作者推测,与 MLM 相比,NSP 失效的主要原因是其缺乏任务难度。按照公式,NSP 可在单个任务中融合主题预测和连贯性预测。但是,与连贯性预测相比,主题预测更容易学习,并且与使用 MLM loss 学习的内容相比也有更多重叠。
句间建模是语言理解的一个重要方面,作者提出了一个新的基于连贯性的 loss,将其应用在 ALBERT 中。也就是说,对于 ALBERT,使用句子顺序预测(SOP)loss,它避免了主题预测,而是着重于句间连贯性的建模。SOP loss 使用与 BERT 相同的方法(同一文档中的两个连续片段)作为正样本,但负样本则采用与 BERT 不同的方式:将顺序互换的两个连续片段作为负样本。这迫使模型学习关于话语级连贯性的细粒度区别。正如作者在第二节中提到的。如 4.6 节所示,事实证明 NSP 根本无法解决 SOP 任务(即最终学习了更容易的主题预测信号,并在 SOP 任务上以随机基准水平执行),而 SOP 可以将 NSP 任务以合理的程度解决,大概是基于对错位相关线索的分析。结果,ALBERT 模型持续提高了下游任务——多语句编码任务的性能。
Sentence Order Prediction(SOP)目标补偿了一部分因为 embedding 和 FFN 共享而损失的性能。Bert 原版的 NSP 目标过于简单了,它把“topic prediction”和“coherence prediction”融合起来。SOP 对其加强,将负样本换成了同一篇文章中的两个逆序的句子,进而消除“topic prediction”。

SOP 对 NSP 的改进,带来了 0.9 个点的平均性能提升。
模型设置
作者在表 1 中列出了具有可比较超参数设置的 BERT 和 ALBERT 模型之间的差异。由于上述设计决策,与相应的 BERT 相比,ALBERT 模型的参数大小要小得多。

例如,相比 BERT-large(334M),ALBERT-large(18M)的参数少约 18 倍。H = 2048 的 ALBERT-xlarge 配置仅具有 6000 万个参数,H = 4096 的 ALBERT-xxlarge 配置具有 233M 参数,即约 BERT-large 参数量的 70%。请注意,对于 ALBERT-xxlarge,作者主要在 12 层网络上报告结果,因为 24 层网络(具有相同的配置)可获得相似的结果,但计算成本更高。
实验结果
实验设置
为了使比较尽可能有意义,作者遵循 BERT 的设置,使用 BOOKCORPUS 和英文 Wikipedia 进行预训练基线模型。这两个语料库包含大约 16GB 的未压缩文本。作者将输入的格式设置为“[CLS] x1 [SEP] x2 [SEP]”,其中$x_1 = x_{1, 1}, x_{1, 2}, \ldots$和$x_2 = x_{1, 1}, x_{1, 2}, \ldots$ 是两个文本片段。作者始终将最大输入长度限制为 512,并以 10% 的概率随机生成小于 512 的输入序列。同 BERT 一样,使用的词汇量为 30000,使用 XLNet 中的 SentencePiece 进行分词。
作者使用 n-gram mask 的方式为 MLM 目标生成 mask input,每个 n-gram mask 的长度是随机选择的。长度为 n 的概率为:
$$
p(n) = \frac{1/n}{\sum_{k=1}^N 1/k}
$$
作者将 n-gram 中 n 的最大长度设置为 3,即 MLM 目标最多可以包含 3-gram 的完整词组,例如“White House correspondents”。
所有模型更新均使用 4096 的 batch_size和学习率为 0.00176 的 LAMB 优化器。除非另有说明,否则作者训练的所有模型步数都为 125000 步。在 Cloud TPU V3 上进行训练,用于训练的 TPU 数量范围从 64 到 512,具体取决于模型的大小。
嵌入参数化分解
表 3 显示了使用基于 ALBERT 的配置设置(表 1)和相同的代表性下游任务集来更改 word embedding 维度 E 的效果。
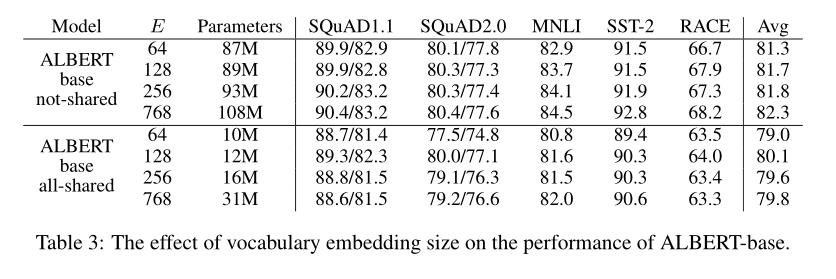
- 在 not-shared 策略下,较大的 E 可以提供更好的性能,但提升幅度不大。
- 在 all-shared 策略下,E = 128 时,效果似乎是最好的。
根据上表的结果,作者在之后的所有设置中将 E 设置为 128,这是进一步缩放的必要步骤。
跨层参数共享
表 4 给出了使用具有两种 embedding 维度(E = 768 和 E = 128)的基于 ALBERT 配置(表 1)进行的各种跨层参数共享策略的实验。
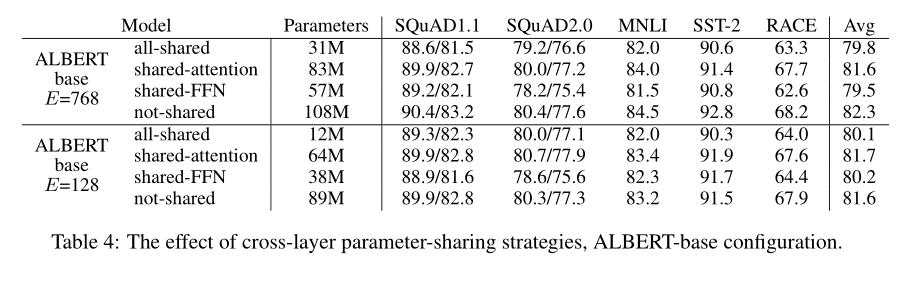
作者比较了 all-shared 策略(ALBERT 的设置)、not-shared 策略(BERT 的设置)、shared-attention 策略和 shared-FFN 策略。
- all-shared 策略:在两种 E 设置下都会影响性能,但是与 E = 768(Avg = -2.5)相比,E = 128(Avg = -1.5)则情况不那么严重。此外,大多数性能下降似乎来自 shared-FFN 参数,而 shared-attention 参数时,E = 128(Avg = +0.1)不下降,E = 768(Avg = -0.7)略有下降。
还有其他策略可以跨层共享参数。例如,作者将 L 层划分为大小为 M 的 N 个组,每个大小为 M 的组共享参数(12 层拆分为 4 x 3)。总体而言,作者的实验结果表明,N 越大 M 越小,获得的性能越好(换言之,即 M = 1,也就是不共享参数)。但是,减小 M,也会大大增加模型的总参数量。因此,作者将 all-shared 策略作为默认选择。
SOP
作者使用 ALBERT-base 配置来比较句子间损失的三个实验场景:无(XLNet 和 RoBERTa)、NSP(BERT)和 SOP(ALBERT)。结果显示在表 5 中,包括固有任务(MLM、NSP 和 SOP 任务的准确性)和下游任务的结果。
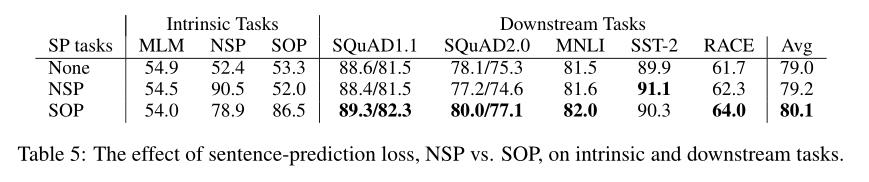
固有任务的结果表明,NSP loss 对 SOP 任务没有任何判别能力(准确性为 52.0%,类似于随机猜测)。这使作者可以得出结论:NSP 最终仅对主题预测建模。
相反,SOP loss 确实可以较好地解决 NSP 任务(准确性为 78.9%),而 SOP 任务甚至更好(准确性为 86.5%)。更重要的是,SOP loss 似乎可以持续提高下游任务(多句编码任务)的性能,例如 SQuAD1.1 提高约为 1%,SQuAD2.0 约为 2%,RACE 约为 1.7%。从而提高 Avg 得分大约 1%。
讨论
尽管 ALBERT-xxlarge 的参数比 BERT-large 的参数少,并且获得了明显更好的结果,但由于其较大的结构 ,其计算成本更高。因此,下一步的研究方向是通过稀疏注意力和阻止注意力的方式来加快 ALBERT 的训练和推理速度。可以提供更多表征能力的正交研究方向,包括 hard example 挖掘和更有效的语言建模训练。
此外,尽管作者有令人信服的证据表明 SOP 是一项更有用的学习任务,可以带来更好的语言表征。但假设当前的自监督训练损失可能尚未捕捉到更多维度,这可能会对结果表征产生额外的表征能力。
附录
A.1 网络深度和宽度的影响
在本节中,作者研究深度(层数 L)和宽度(隐藏层大小 H)如何影响 ALBERT 的性能,表 11 显示了使用不同层数的 ALBERT-large 配置(见表 1)的性能。
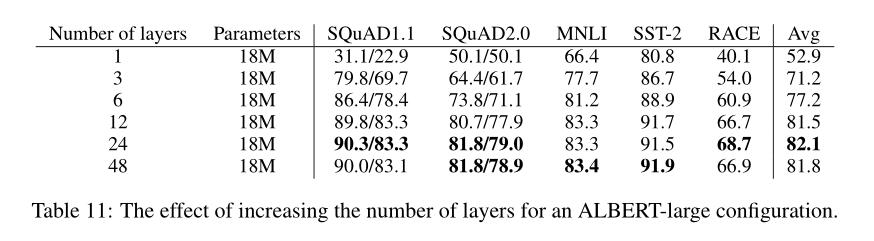
通过使用之前深度的参数进行微调来训练具有 3 层或更多层的网络(例如,从 6 层网络参数的检查点微调 12 层网络参数)。Gong 等人已经使用了类似的技术。
如果将 3 层 ALBERT 模型与 1 层 ALBERT 模型进行比较,尽管它们具有相同的参数量,但性能会显著提高。但是,当继续增加层数 L 时,收益递减:12 层网络的结果相对接近 24 层网络的结果,而 48 层网络的性能似乎下降(过拟合?)。

表 12 所示为 3 层 ALBERT-large 配置的类似现象,即宽度随着隐藏层大小 H 的增加,性能会得到提高,但收益随之减少。在 6144 的隐藏层大小下,性能似乎显著下降。作者注意到,这些模型似乎都对训练数据过拟合了,与性能最佳的 ALBERT 配置相比,它们都具有更高的 train 和 dev loss。
A.2 是否需要更深的 ALBERT 模型?
在第 A.1 节中,作者表明对于 ALBERT-Large(H = 1024),12 层和 24 层配置间的差异很小。这个结果是否仍然适用于更广泛的 ALBERT 配置,例如 ALBERT-xxlarge(H = 4096)?

由表 13 可知:12 层和 24 层 ALBERT-xxlarge 配置在下游任务精度方面的差异可以忽略不计,Avg 分数相同。作者得出的结论是——当共享所有跨层参数(包括前馈网络 FFN和注意力层参数)时,不需要比 12 层配置更深的模型。
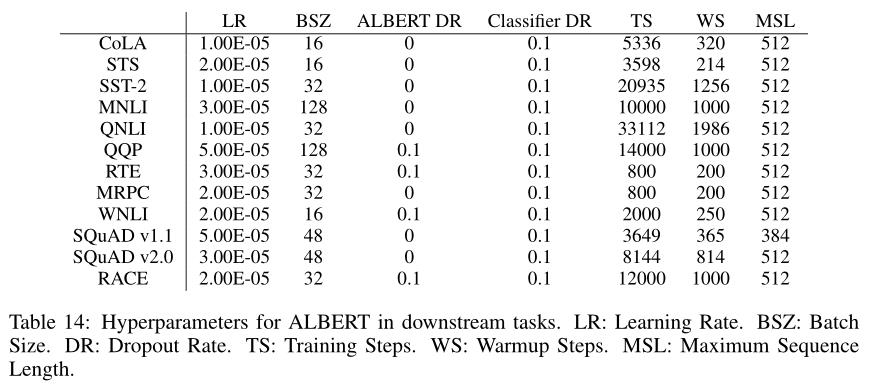
A.4 超参数
表 14 显示了用于下游任务的超参数,作者采用了 Liu、Devlin 和 Yang 等人设置的超参数。