论文阅读:Bag of Tricks for Efficient Text Classification
速读
Q1:论文试图解决什么问题?
作者在文本分类背景下,探讨如何将基线扩展到具有大型输出、且语料库非常庞大的场景。简而言之,相比深度神经网络的训练与推测时间较长,作者希望能够扩展一些架构简单的文本分类器,使其能够近似或达到深度神经网络的性能,并且架构简单的文本分类器的资源耗费较少、训练速度更快。
Q2:论文中提到的解决方案之关键是什么?
- 作者提出了一个新的模型架构,类似于 Mikolov 等人的 cbow 模型,区别在于该模型架构预测句子的标签,而非中间位置的词语。
- 借助层次化 softmax 来降低时间复杂度。
- 使用 N-gram 特征来捕捉一些本地词序的局部信息。
Q3:代码有没有开源?
https://github.com/facebookresearch/fastText
Q4:这篇论文到底有什么贡献?
作者提出了一个简单的文本分类基线方法——fastText。
介绍
在这项工作中,作者探讨了在文本分类背景下,如何将这些基线扩展到具有大型输出场景的非常大的语料库。受近期高效词表征学习工作的启发(Efficient Estimation of Word Representations in Vector Space;Levy 等人,2015 年),作者表明具有 rank 约束和快速损失近似的线性模型可以在十分钟内对十亿个词进行训练,同时取得与最先进水平相当的性能。
模型架构
一个简单有效的句子分类基线是将句子表示为 bag of words(BoW),并训练一个线性分类器,例如逻辑回归或 SVM。然而,线性分类器在特征和类别之间不共享参数[//]: # (线性分类器中通过权重来将每个特征线性组合起来,每个特征之间相互独立,因此特征之间不共享参数。并且,分类任务的标签往往也都是相互独立,因此类别之间也不共享参数。),这可能限制了它们在大的输出空间背景下的泛化性,因为有些类的数据非常少。这个问题的常见解决方案是将线性分类器分解为低等级(rank)矩阵(Schutze 1992;Mikolov 等人,2013)或使用多层神经网络。
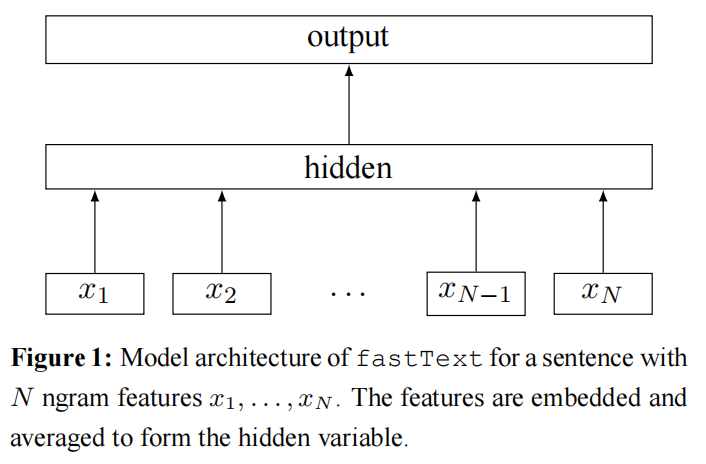
图 1 显示了一个带有 rank 约束的简单线性模型。第一个权重矩阵 A 是一个关于词语的查找表(look-up table)。 然后,这些词的表征被平均为一个文本表征,反过来又被送入一个线性分类器。文本表征是一个隐藏变量,可以被潜在地重复使用。这个架构类似于 Mikolov 等人的 cbow 模型,区别在于 cbow 预测中间位置的词语,而 fastText 预测句子的标签。
作者使用 softmax 函数 f 来计算预先定义的类别的概率分布。对于一组 N 个文档来说,最小化类别的负对数似然函数。
$$
- \frac{1}{N} \sum_{n = 1}^N y_n log(f(BAx_n))
$$
其中,$x_n$ 是第 n 个文档的标准化特征包,$y_n$ 是标签,A 和 B 是权重矩阵。这个模型是在多个 CPU 上使用随机梯度下降和线性衰减的学习速率进行异步训练。
层次化 softmax
当类的数量很大时,计算线性分类器的成本很高。更确切地说,计算复杂度是 $O(kh)$,其中 k 是类的数量,h 是文本表征的维度。为了改善运行时间,使用了基于 Huffman 编码树的分层 softmax。在训练期间,计算复杂度下降到 $O(h log_2(k))$。
在测试时,层次化的 softmax 在搜索最可能的类别时也很有优势。每个节点都有一个概率,即从根到该节点路径的概率。如果该节点处于深度为 l + 1 的位置,其 parents $n_1, \ldots, n_l$,路径概率为:
$$
P(n_{l + 1}) = \prod_{i = 1}^l P(n_i)
$$
这意味着一个节点的概率总是低于其父节点的概率。用 DFS 方法搜索树,并跟踪叶子中的最大概率,使我们能够放弃任何与小概率有关的分支。在实践中,作者观察到测试时的复杂度降低到 $O(h log_2(k))$。这种方法被进一步扩展,使用 binary heap 以 $O(log(T))$ 的代价计算 T-top 目标。
N-gram 特征
词袋不考虑词序(词序是不变的),但明确考虑到这一顺序往往在计算上非常昂贵。相反,作者使用一袋 n-grams 作为额外的特征来捕捉一些关于本地词序的部分信息。这在实践中是非常有效的,同时取得了与明确使用词序的方法相当的结果。
通过使用散列技巧来保持 n-grams 的快速和内存效率的映射,散列函数与 Mikolov 等人的做法相同,如果我们只使用 bigrams,则为 10M,否则为 100M。
讨论与总结
在这项工作中,作者提出了一个简单的文本分类的基线方法。与来自 word2vec 无监督训练的词向量不同,本项工作中的词特征可以被平均到一起,作为句子表征。在一些任务中,fastText 获得了与最近提出的受深度学习启发的方法相同的性能,同时速度更快。虽然深度神经网络在理论上具有比浅层模型高得多的表征能力,但目前还不清楚像情感分析这样的简单文本分类问题是否适合用来评估它们。