论文阅读:DQ-LoRe:Dual Queries with Low Rank Approximation Re-ranking for In-Context Learning
大型语言模型(LLMs)展示了其基于上下文学习的卓越能力,在错综复杂的推理任务中,利用思维链(CoT)范式中的中间推理步骤来引导大型语言模型的一个很有前景的途径。然而,核心挑战在于如何有效选择范例来促进上下文学习。
先前的很多工作都是围绕添加思维链,例如一致性 CoT、思维树以及思维图,往 context 中添加更多的推理步骤,或者将推理过程拆解为多个子步骤,依次优化每个子步骤。这些操作都会让 context 越来越长,或者在推理过程中增加更多的链路,从而导致推理的时延和成本增加。这篇论文的一个核心或者说有价值的工作是考虑了时间成本,具体做法请阅读下文关于论文方法的介绍。
在本研究中,作者介绍了一种利用双查询和低秩近似重新排序(DQ-LoRe)的框架,以自动选择用于上下文学习的范例。双查询首先查询 LLM 以获得 LLM 生成的知识(如 CoT);然后查询检索器,通过问题和知识获得最终范例。此外,对于第二次查询,LoRe 采用了降维技术来完善范例选择,确保与输入问题的知识密切吻合。
通过大量实验,作者证明了 DQ-LoRe 在 GPT-4 示例自动选择方面的性能明显优于之前的先进方法,从 92.5% 提高到 94.2%。综合分析进一步表明,DQ-LoRe 在性能和适应性方面始终优于基于检索的方法,尤其是在以分布变化为特征的场景中。
方法介绍

图 1:DQ-LoRe 的整体流程。它由三部分组成: 双查询首先查询 LLM 以获得 CoT y;然后查询检索器,通过问题和 LLM 生成的知识获得最终范例。LoRe 利用 PCA 来近似检索到范例的低秩嵌入,使检索器能够更好地区分它们。检索器会根据 BM25 和 LLM 生成的 CoT 相似度,通过正负集的训练来获取具有相似 CoT 的范例。
步骤 1:双查询推理 - 第一次查询
如图 1 上方左边所示,作者使用 Complex-CoT 方法来获取初始的 n 个范例,因为作者观察到,使用 Complex-CoT prompt 格式来组织初始 n-shot 范例和问题 $x_i$,用于查询 LLM 可获得推理信息更丰富的 CoT $y_i$。当然,也可以使用其他基于检索的方法,例如根据查询与输入问题的语义相似性使用 BM25 进行检索。范例也可以包括人工设计的范例,包括 CoT 和其他模板,如思维树和思维图。
步骤 2:双查询推理 - 检索器训练
如图 1 下方 Retriever 虚线部分所示,展示了检索器的训练过程。作者将该检索器称之为 CoT 感知检索器(编码器模型),用来获得范例和测试样本的表征,并测量 CoT 与范例之间的相似性。
与之前使用对比学习训练 sentence embedding 模型类似,作者应用对比学习来训练检索器 $s_e$。具体来说,使用训练集中的数据来构建训练数据,其中每个样本 $d_i = (x_i, y_i)$ 由一个问题 $x_i$ 及其对应的 CoT $y_i$ 组成(图 1 下方的 Question X 和 CoT Y)。作者使用 BM25 从整个训练集中检索出前 k 个相似的训练样本作为候选样本,记为 $D’ = {d_1’,d_2’, \ldots, d_k’}$。获得这 k 个样本后,考虑 $d_j’$ 和 $d_i$ 的距离来重新排序。作者使用 text-davinci-003 等语言模型来计算概率:
$$
score(d_j’) = P_{LM}(y_i | d_j’, x_i), \quad j = 1, 2, \ldots, k \tag{1}
$$
其中,$P_{LM}(y_i | d_j’, x_i)$ 是在 $d_j’$ 和输入上下文 $x_i$ 的条件下,LM 生成 CoT $y_i$ 的概率。得分越高,表示 $d_j’$ 包含 CoT $y_i$ 的概率越高,并且具有相似的推理逻辑。作者根据得分对 D’ 中的样本重新排序,并选择前 t 个样本作为正例,记为 $pos_i$,最后 t 个样本作为硬负例,记为 $neg_i$。通常,2 * t ≤ k。
后面就是常规的对比学习训练 sentence embedding 模型的过程,具体可以去看 simcse 的论文 https://arxiv.org/abs/2104.08821。
这样训练后的检索器就能从若干范例中挑选出适配当前问题 $x_i$ 和 CoT $y_i$ 的范例(获取得分后重新排序,挑选 top-k 范例,如图 1 下方右边所示)。
步骤 3:LoRE:低秩近似重新排序
作者认为从检索器挑选出的 top-k 个范例是根据语义相似性检索的,通常表现出高度相似的 CoT。这就导致与当前问题呈现虚假相关性的范例和在 CoT 中真正具有逻辑相关性的范例混杂在一起,难以区分。为了解决这个问题,作者采用主成分分析法(PCA)将 top-k 个范例和目标样本 $t_i$ 的嵌入维度降低到最终维度 e。在数学推理任务中,使用向量内积来计算缩减嵌入之间的相似度。但是,在常识推理任务中,为了区分这些示例,同时尽可能多地保留 CoT 信息,采用了高斯核函数来计算嵌入之间的相似性。高斯核的表示方法如下:
$$
k(s_e(t_i), s_e(e_j)) = exp(- \frac{||s_e(t_i) - s_e(e_j)||^2}{2 \sigma^2}) \tag{4}
$$
其中,$||s_e(t_i) - s_e(e_j)||$ 表示 $s_e(t_i)$ 和 $s_e(e_j)$ 之间的欧几里得距离。
根据重新排序后的相似性得分(k ≥ n),得到 top-n 个范例。再将其与 $x_i$ 拼接输入到 LLM,从而得到 ICL 的最终 CoT。有了这些 CoT 范例,就可以提示 LLM,得到最终答案。
实验相关
主要结果
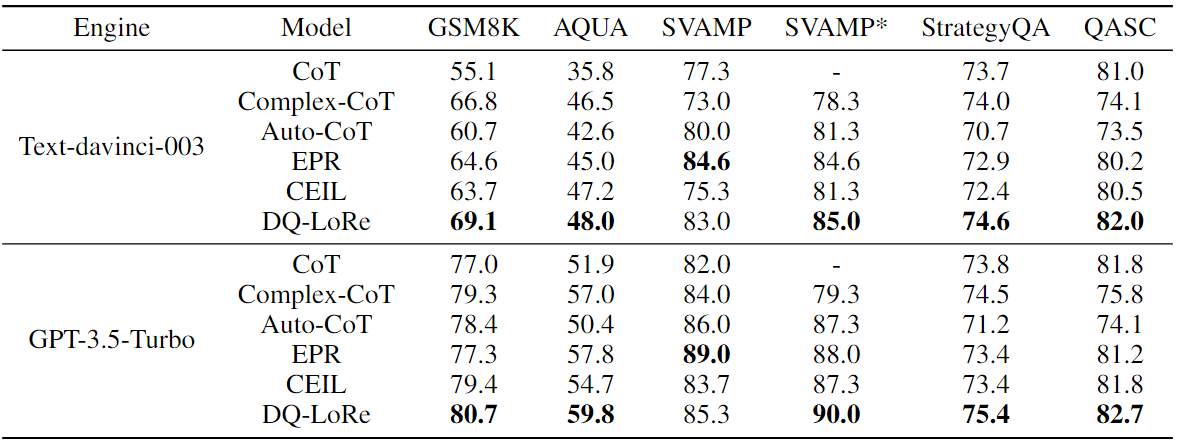
表 1:不同模型在 i.i.d. 设置下的准确率(%)。Complex-CoT 从标注或 GPT-3.5-Turbo 输出中选择最复杂的 CoT。除 CoT 使用 4-shot 手动标注的范例外,所有方法都选择 8-shot 标注的范例。SVAMP* 表示在 GSM8K 数据集上训练检索器,然后通过检索 SVAMP 上的示例进行测试所获得的结果。
表 1 显示了模型在 i.i.d. 设置下的性能。它表明该方法在 GSM8K 和 AQUA 数据集上取得了最有希望的结果。在 SVAMP 数据集上,使用生成的 CoT 对检索器进行训练,LoRE 模型并不优于 ERP 模型。因为ERP 模型倾向于捕捉和利用这些词的共现模式。此外,在 SVAMP 数据集中,测试集和训练集之间存在大量的词语共现样本。因此,ERP 将检索所有与测试样本有词共现的示例。
为了避免在 SVAMP 上检索受到这些虚假相关性的影响,并测试模型的真实性能,作者在分布偏移的条件下进行了实验。在 GSM8K 数据集上训练检索器,在 SVAMP 测试集上进行检索和测试。在这种分布偏移设置下,事实证明它能有效中和虚假相关性的影响,LoRe 模型最终在 SVAMP* 数据集上获得了 90% 的准确率,大大超过了存在严重虚假相关性的 EPR。作者认为这是由于 EPR 主要依赖于问题之间的词语共现模式,而没有考虑 CoT 之间的相似性。

表 2:在 i.i.d. 设置下,不同 ICL 方法与 GPT-4 在 GSM8K 数据集上的准确率(%)。
表 2 显示了 GPT-4 在 GSM8K 数据集上的 ICL 结果。LoRe 模型的性能以 1.7% 的准确率大幅超越了之前基于检索的最先进方法 CEIL。
初始范例的影响
分析获取初始范例的各种方法对最终结果的影响。在实验中:
- “Random”指的是每次推理时从训练集中随机选择 8 个范例。
- “EPR”和“CEIL”表示通过在 SVAMP 上检索获得的初始 8 个范例。
- “Scoratic-CoT ”涉及使用来自 Complex-CoT 范例的分解子问题和求解步骤来标注 SVAMP 训练集,成功标注了 GPT-3.5-Turbo 最终 700 个训练数据点中的 624 个。随后,使用 DQ-LoRe 对产生的 Scoratic 格式范例进行了训练和检索,并使用了这些最初的 8 个示例。

表 5:在 SVAMP 数据集上,在 i.i.d. 设置中使用不同初始 n 个范例的最终准确率(%)。
从表 5 可以看出,获取初始范例的方法对最终结果有很大影响,精心选择初始示例的 EPR 和 CEIL 等方法的性能明显优于随机选择 8 个初始示例的方法。另外,在 SVAMP 的 i.i.d. 设置下,Scoratic-CoT 的表现优于 Complex-CoT,这表明不同的初始 prompt 格式对模型的最终性能有显著影响。
LoRe 可视化
分析 PCA 对 DQ-LoRe 方法的影响。在训练有素的检索器的高维空间中,从离查询最远的 8 个范例中直接选择嵌入。这些被选中的嵌入在检索过程中充当范例,并代表最差的情况。在 GSM8K 数据集的 i.i.d 设置下,使用 text-davinci-003 模型,使用这些最差范例的准确率为 48.1%。这一结果证明,训练有素的检索器有能力区分“好”与“坏”范例。在此基础上,作者根据检索器的辨别能力来识别和选择被归类为“好”或“坏”的 M 个范例,并使用 t-SNE 进行 LoRe 降维前后 M 个范例的嵌入可视化。

图 2:LoRe 前后嵌入的 T-SNE 可视化结果。
在 SVAMP 测试数据集上,基于 GSM8K 训练的检索器比基于 SVAMP 训练的检索器性能更好。因此,作者进一步绘制了相应的 t-SNE 可视化图,如图 2 所示。
- 在第二次查询中,首先使用检索器检索了 64 个嵌入。这些嵌入随后进行了降维处理。与在 SVAMP 上训练的检索器的 “好 ”和 “坏 ”嵌入相比,在 GSM8K 上训练的检索器的 “好 ”和 “坏 ”嵌入变得更加明显,这表明扩大 “好 ”和 “坏 ”嵌入之间的差异可以进一步提高性能。
- 图 2(b) 显示,在 LoRe PCA 处理之前,“好 ”嵌入和 “坏 ”嵌入的分布是混合的。在 LoRe PCA 处理之后,“好 ”嵌入以明显的趋势向外迁移,而 “坏 ”嵌入则在同一方向上表现出轻微的趋势,从而导致两者之间的差距扩大。这种差异有助于提高性能。因此,LoRe 的 PCA 流程有效地扩大了 “好 ”嵌入和 “坏 ”嵌入之间的区别,进一步提高了整体性能。
- 比较图 2(a)和图 2(b),可以发现,在 LoRe 引起的样本间距离扩展后,图 2(b)中正样本的离散趋势变得更加明显。相反,图 2(a)显示,在 LoRe 扩大样本间距离后,正负样本间的差距明显小于图 2(b)中的结果。另一个耐人寻味的现象是,在投影之前,负样本聚集在一个狭窄的区域,而正样本则更均匀地分布在整个空间。这意味着它们在高维空间中占据了一个狭窄的锥形区域。通过 LoRe,这个锥形可以变得更加 “扁平”。这些观察结果表明,LoRe 可以通过调节样本间的距离扩散速度来提高模型性能。
总结
作者引入了一种被称为 DQ-LoRe 的创新方法,这是一种具有低秩近似重新排序功能的双重查询框架,可增强多步骤推理任务的上下文学习。这是通过考虑输入问题和范例中的思维链来实现的,然后使用 PCA 过滤掉嵌入中的冗余信息,随后重新排序以获得最终的范例。这种方法增强了模型辨别不同范例的能力。
实验结果表明,DQ-LoRe 优于现有的方法,尤其是在涉及分布变化的情况下,表现出了显著的功效。这凸显了它在各种情况下的稳健性和通用性。