论文阅读:DeeBERT:Dynamic Early Exiting for Accelerating BERT Inference
大规模的预训练语言模型,如 BERT,为 NLP 应用带来了显著的改善。然而,它们也因推断速度慢而受人诟病,这使得它们难以在实时应用中部署。因此,作者提出了一种简单但有效的方法,将其命名为 DeeBERT。该方法允许待预测数据不通过整个模型而提前退出,从而加速 BERT 的推断过程。
实验表明,DeeBERT 能够尽可能保证模型效果的前提下,节省高达 40% 的推断时间。进一步的分析表明,BERT Transformer 层的不同行为也揭示了它们的冗余性。
介绍
为了加速 BERT 的推断过程,作者提出了 DeeBERT:BERT 的动态提前退出。该方案的灵感来自于计算机视觉领域的一个众所周知的观察结果:深度卷积神经网络中,较高的层通常会产生更详细、更细粒度的特征。因此,作者假设对于 BERT 来说,中间 Transformer 层提供的特征可能足以对一些输入样本进行分类。
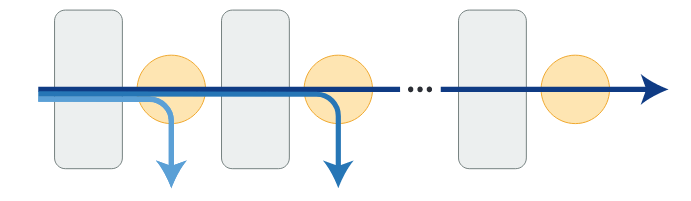
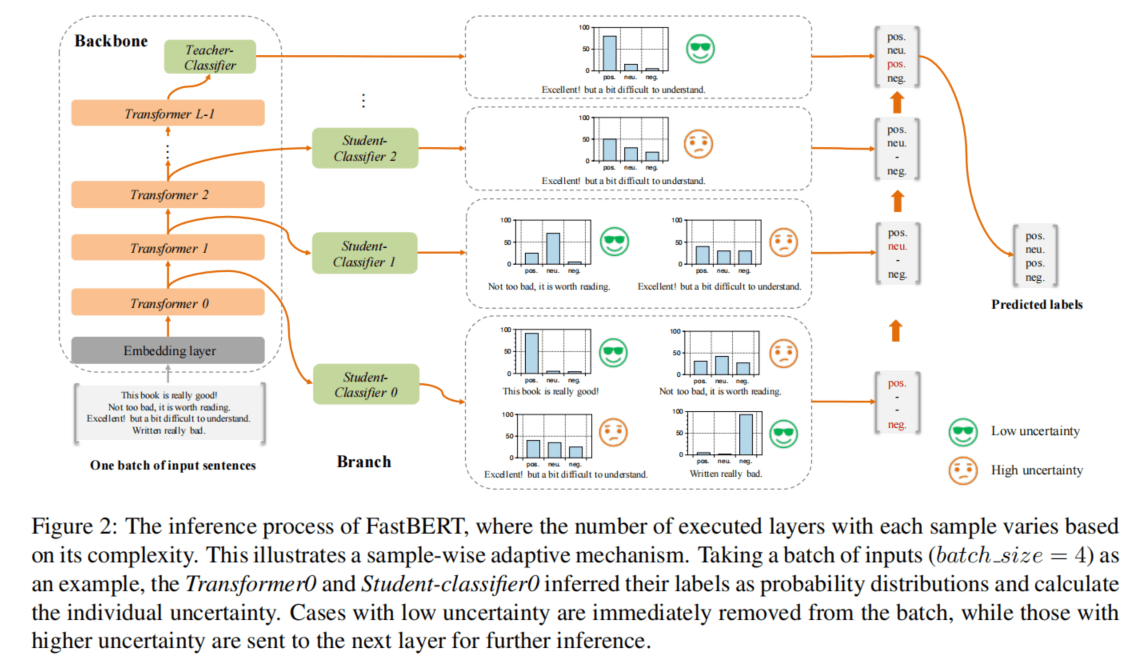
DeeBERT 通过在 BERT 的每个 Transformer 层之间插入额外的分类层(作者称之为 off-ramps)来加速 BERT 推断过程(如图 1 所示)。所有的 Transformer 层和 off-ramps 都是在一个给定的下游数据集上联合微调的。在推断时,一个样本经过一个 Transformer 层后,会被传递到后面的 off-ramp。如果 off-ramp 对预测的结果有信心,则直接返回预测结果;否则,样本将继续传递到下一个 Transformer 层。
在文本中,作者用 6 个 GLUE 数据集对 BERT 和 RoBERTa 进行了实验,结果表明 DeeBERT 能够在下游任务上以最小的模型质量降低为前提,将模型的推断速度提高 40%。进一步的分析揭示了模型的 Transformer 的有趣模式,以及 BERT 和 RoBERTa 的冗余。
BERT 推断的提前退出
DeeBERT 保持前期预训练不变,只修改了 BERT 模型的微调和推断过程。DeeBERT 为每个 Transformer 层增加了一个 off-ramp。在推断过程中,每个样本可以在 off-ramp 中选择提前退出,而不需要经过 BERT 的所有 Transformer 层。DeeBERT 最后一层的 off-ramp 即为原始 BERT 模型的分类层(softmax)。
DeeBERT 的微调
作者从一个有 n 个 Transformer 层的预训练 BERT 模型开始,并在其中添加 n 个 off-ramp。为了在下游任务上进行微调,第 i 层 off-ramp 的损失函数为:
$$
L_{i}(\mathcal{D} ; \theta)=\frac{1}{|\mathcal{D}|} \sum_{(x, y) \in \mathcal{D}} H\left(y, f_{i}(x ; \theta)\right) \quad (1)
$$
其中,D 是微调训练集,$\theta$是所有参数的集合,(x, y) 是样本的特征标签对,H 为交叉熵损失函数,$f_i$为第 i 个 off-ramp 的输出。
网络微调分两个阶段进行:
- 用损失函数$ L_n$更新嵌入层、所有 Transformer 层和最后一个 off-ramp(softmax 分类层)。该阶段与原论文中的 BERT 微调相同。
- 冻结第一阶段微调的所有参数,然后用损失函数$\sum_{i=1}^{n-1} L_i$更新除最后一个 off-ramp 以外的所有参数。冻结 Transformer 层的参数是为了保证最后一个 off-ramp 的最佳输出质量,否则 Transformer 层不再只针对最后一个 off-ramp 进行优化,通常会使模型的质量下降。
DeeBERT 的推断
DeeBERT 在推断时的工作方式如算法 1 所示。作者用输出概率分布$z_i$的熵来量化 off-ramp 对输入样本预测的置信度。当一个输入样本 x 到达一个 off-ramp 时,off-ramp 将其输出分布$z_i$的熵与一个预设的阈值 S 进行比较,从而确定样本是否应该返回,还是继续送到下一个 Transformer 层。

从直觉和实验中都可以看出,S 越大,模型速度越快,但精度越低;S 越小,模型精度越高,但速度越慢。在实验中,作者根据这个原则来选择阈值 S。除此之外,作者还探索了使用多层 ensemble 而非单层的 off-ramp,但这并没有带来显著的提升。作者推测是不同层的预测结果通常是高度相关的,一个错误的预测不可能被其他层“修复”。因此,作者坚持采用简单而高效的单输出层策略(即只在每一层 Transformer 通过一个 off-ramp 进行分类判断)。
实验
实验设置
作者将 DeeBERT 应用于 BERT 和 RoBERTa,并在 GLUE 基准的 6 个分类数据集上进行实验。SST-2、MRPC、QNLI、RTE、QQP 和 MNLI。作者对 DeeBERT 的实现改编自 HuggingFace 的 Transformer Library。推断时间的测量是在单个 NVDIA Tesla P100 显卡上进行的。超参数如隐藏层状态大小、学习率、微调 epoch 和 batch size 都保持库中的设置不变。没有 early stopping 并选择完全微调后的检查点。
主要结果
作者通过设置不同的熵阈值 S 来改变 DeeBERT 的质量-效率权衡,并将结果与表 1 中的其他基线进行比较。模型质量实在测试集上测量的,结果由 GLUE 评估服务器提供。在整个测试集上用 wall-clock 推断时间(包括 CPU 和 GPU 运行时间)来量化效率,其中样本被逐一输入到模型中。对于 DeeBERT 在数据集上的每一次运行,作者根据开发集上的质量-效率权衡,选择三个熵阈值 S,旨在展示两种情况:
(1)以最小的性能下降(<0.5%)实现最大的运行时间节省;
(2)以中等的性能下降(2%-4%)实现运行时间节省。
每个数据集所选的 S 值不同。
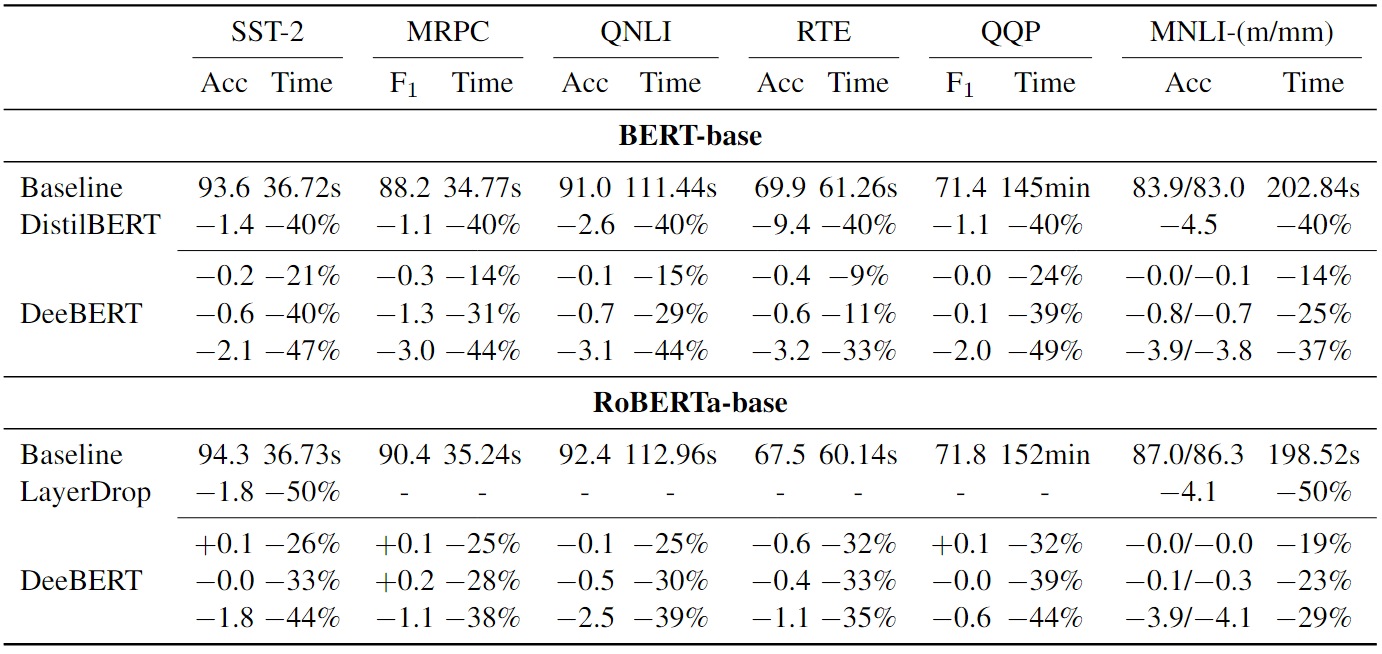
作者也在图 2 中直观地看到了这种权衡。每条曲线都是通过插值绘制的,每个点对应不同的阈值 S。由于这只涉及 DeeBERT 不同设置之间的比较,所以运行时间是在开发集上测量的。从表 1 和图 2 中,我们可以观察到以下规律。
- 尽管基线性能存在差异,但两种模型在所有数据集上都显示出类似的模式:性能(准确率/F1 Score)保持(大部分)不变,直到运行时间节省达到某个转折点,然后开始逐渐下降。BERT 的转折点通常比 RoBERTa 来得更早,但在转折点之后,RoBERTa 的性能比 BERT 下降得更快。其原因将在第 4.4 节中讨论。
- 偶尔,作者观察到曲线中的峰值,例如 SST-2 中的 RoBERTa,以及 RTE 中的 BERT 和 RoBERTa。作者将其归因于早期退出带来的形似正则化,因此有效模型尺寸较小,即在某些情况下,使用所有 Transformer 层可能不如只使用其中的一些层。
与其他 BERT 加速方法相比,DeeBERT 具有以下两个优势:
- DeeBERT 没有像 DistilBERT 那样产生一个固定尺寸的小模型,而是产生了一系列的选项,以便更快地进行推断,用户可以根据自己的需求灵活选择。
- 与 DistilBERT 和 LayerDrop 不同,DeeBERT 不需要对 Transformer 模型进一步的预训练,这比微调要耗时得多。
预期时间节省
由于对运行时间的测量可能并不稳定,作者提出了另一个反映效率的度量,称为预期时间节省,定义为:
$$
1 - \frac{\sum_{i=1}^n i \times N_i}{\sum_{i=1}^n n \times N_i}
$$
其中,n 为层数,$N_i$为第 i 层退出的样本数。直观地讲,预期时间节省是指使用提前退出方法从而减少 Transformer 层执行的分数。这个度量的优点是它在不同的运行之间保持不变,并且可以分析计算。为了验证,作者在图 3 中把该度量与测量节省进行了比较。总的来说,曲线显示了预期时间节省和测量节省之间的线性关系,表明作者报告的运行时间是对 DeeBERT 效率的稳定测量。

每层分析
为了了解将 DeeBERT 应用于这两种模型的效果,作者对每一个 off-ramp 层进一步分析。本节的实验也是在开发集上进行的。
各层的输出性能
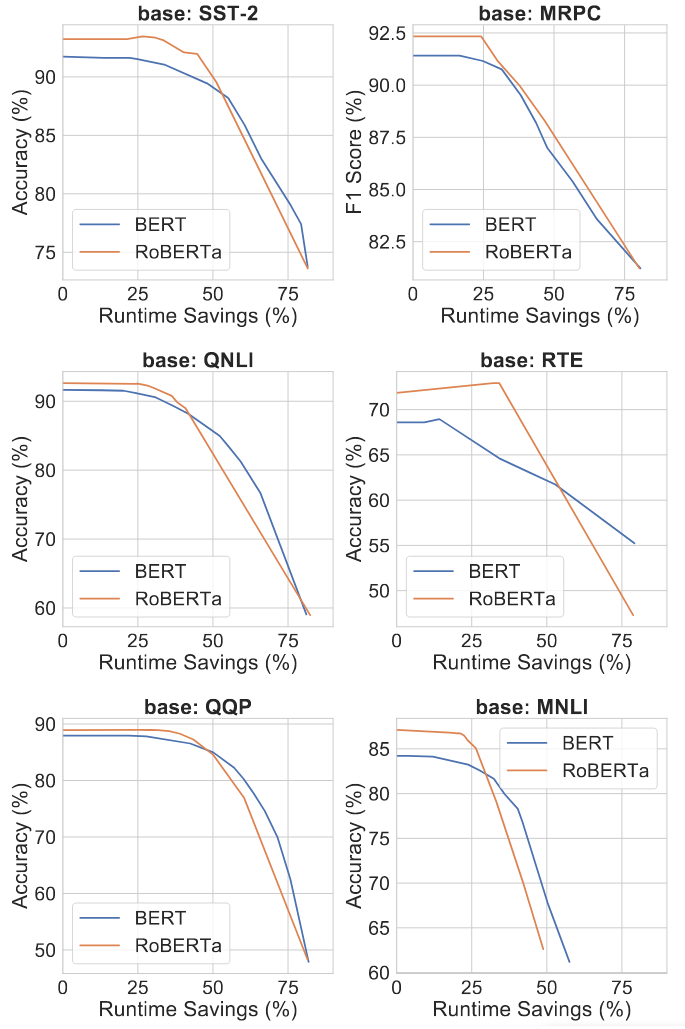
对于每一个 off-ramp,作者将开发集中的所有样本从当前 off-ramp 中强制退出,并测量输出的质量,将结果可视化,如图 4 所示。从图中,作者注意到 BERT 和 RoBERTa 的区别。随着 off-ramp 数量的增加,BERT 的输出质量以相对稳定的速度提升。另一方面,RoBERTa 的输出质量在几层中几乎保持不变(甚至恶化),然后迅速提高,并在 BERT 之前达到饱和点。这为 4.2 节中提到的现象提供了一个解释:在相同的数据集上,RoBERTa 往往能在保持大致相同的输出质量的情况下,实现更多的运行时间节省,但到了转折点之后,质量却下降得更快。
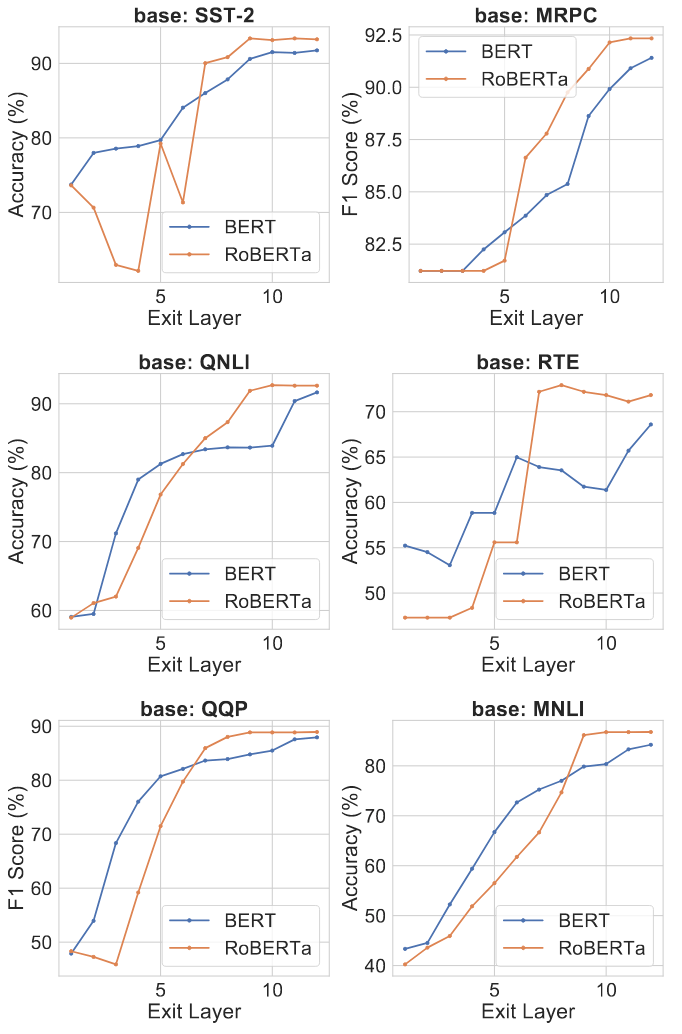
作者还在图 5 中展示了 BERT-large 和 RoBERTa-large 的结果。从右边的两张图中,作者观察到 BERT-large 和 RoBERTa-large 都有共同的冗余迹象:与前几层相比,最后几层的性能并没有太大的改善(在某些情况下性能甚至略有下降)。这种冗余也可以在图 4 中看到。

各层退出的样本数量
作者进一步展示了图 6 中给定熵阈值的样本在每个 off-ramp 退出的分数。熵阈值 S=0 为基线,所有样本在最后一层退出;随着 S 的增加,逐渐有更多样本提前退出。除了显而易见的,作者还观察到了额外的、有趣的模式。
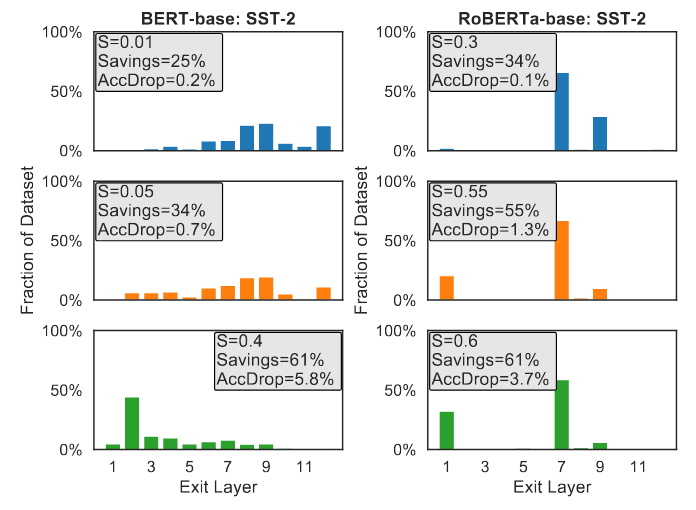
如果某一层没有提供比之前层更好的输出质量,例如 BERT-base 中的第 11 层和 RoBERTa-base 中的第 2-4 和 6 层(可以在图 4 左上角看到),它通常被极少数样本选择;“受欢迎”的层通常是那些比之前层有大幅改进的层,例如 RoBERTa-base 中的第 7 层和第 9 层。
由此可见,熵阈值能够在质量相当的情况下,选择最快的 off-ramp,实现了质量和效率的良好权衡。
总结和未来工作
作者提出的 DeeBERT 是一种有效的方法,它可以利用 BERT 模型中的冗余度来实现更好的质量-效率权衡。实验证明 DeeBERT 能够加快 BERT 和 RoBERTa 的推断速度,最高可达 40%,同时也揭示了 BERT 模型中不同 Transformer 层的有趣模式。