论文阅读:DistilBERT a distilled vesion of BERT smaller faster cheaper and lighter
在这篇论文中,作者提出了一种方法来预训练一个小的名为 DistilBERT 的通用语言表示模型。该模型可以在广泛的任务中进行 fine tune,并具有良好的性能。虽然先前的大多数工作都在研究如何使用蒸馏来构建特定任务的模型,但作者在预训练阶段就利用了知识蒸馏,并表明可以将 BERT 模型的大小减少 40%,同时保留模型 99% 的语言理解能力和提高 60% 的速度。
为了利用大模型在预训练过程中学到的归纳偏差,论文中引入了语言建模、蒸馏和余弦距离损失相结合的三重损失。消融研究进一步表明:三重损失的每一个组成部分对模型的最佳性能都很重要。
DistilBERT
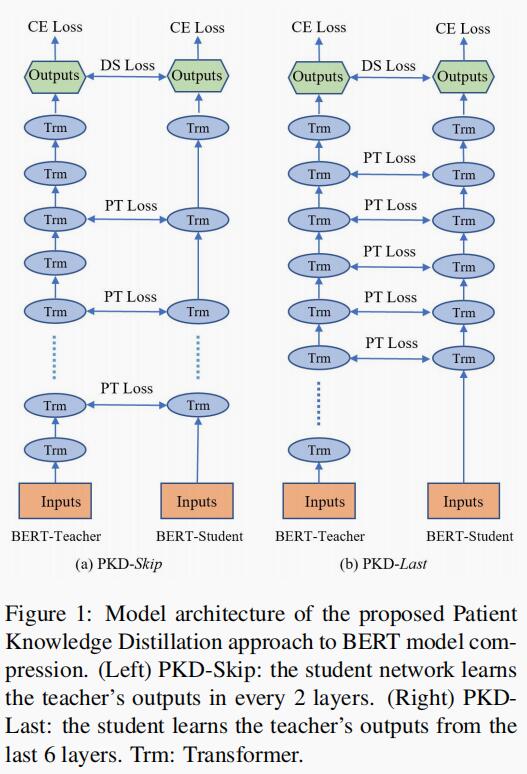
student 网络架构
DistilBERT 拥有和 BERT 相同的通用架构。不同点在于:
- 删除 token-type embeddings 和 pooler;
- 将层数减少 2 倍;
- 在现代线性代数框架内,高度优化 Transformer 体系结构中使用的大多数操作(线性层和 layer normalisation)
- 作者指出张量的最后一个维度(hidden size dimension)的变化对计算效率(对于固定参数预算)的影响比其他因素(例如层数)的变化要小。因此,DistilBERT 专注于减少层数。
student 初始化
除了前面描述的优化和网络架构的选择外,在训练过程中的一个重要元素是为子网络找到合适的初始化以收敛。利用 teacher 网络和 student 网络之间的共同维度,可以通过从两层中取出一层来初始化 student 网络。
蒸馏
作者应用最佳实践来训练 Liu 等人最近提出的 BERT 模型。利用动态 mask 在没有下一个句子预测目标的情况下,利用梯度累积在非常大的批次(每批次最多 4k 个实例)上蒸馏 DistilBERT。
实验
作者根据通用语言理解评估 GLUE 基准评估 DistiBERT 的语言理解和泛化能力。作者通过微调 DistilBERT 来报告每个任务的 dev sets 分数,将结果与 GLUE 的走着提供的基线进行比较。
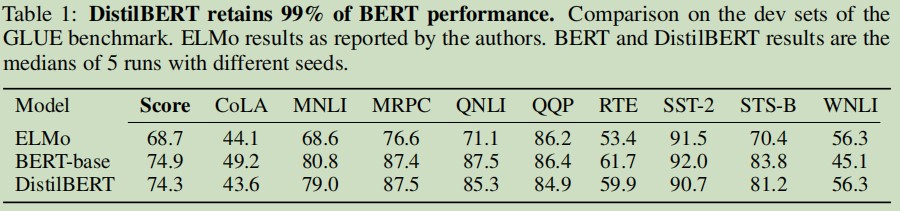
下游任务 benchmark
作者提出 DistilBERT 比 BERT 小 40%,同时提高 60% 速度是使用 CPU(英特尔至强 E5-2690 v3 Haswell @2.9GHz),批量大小为 1 STSB 数据集上测试得到。

消融研究
在这一部分中,作者研究了三重损失的各种成分和 student 网络初始化对蒸馏模型性能的影响。

表 4 列出了具有全部三重损失的增量:删除 Masked Language Modeling 损失几乎没有影响,而另外两种蒸馏损失占了很大一部分性能。
总结
这篇论文最终得出:一个通用的语言模型可以成功地训练与蒸馏,并分析各种成分的消融研究。同时,进一步证明了 DistilBERT 是一个令人信服的终端应用的选择。