论文阅读:EDA:Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
EDA 包含四个简单但功能强大的操作:同义词替换,随机插入,随机交换和随机删除。在五个文本分类任务上,作者表明 EDA 可以提高卷积神经网络和循环神经网络的性能。EDA 对较小的数据集显示出特别强的结果。平均而言,在五个数据集上,仅使用 50% 的可用训练集进行 EDA 训练就可以获得与使用所有可用数据进行的正常训练得到相同的准确性。此外,作者还进行了广泛的消融研究,并提出了实用的参数。
介绍
机器学习和深度学习已在从情感分析到主题分类的任务上实现了很高的准确性,但是高性能通常取决于训练数据的大小和质量,而这往往很难收集。自动数据增强通常用于计算机视觉和语音,可以帮助训练更强大的模型,尤其是在使用较小的数据集时。但是,提出通用的语言转换规则比较困难,因此尚未充分探索 NLP 中的通用数据增强技术。
先前已有相关的研究提出了一些在 NLP 中用于数据增强的技术:
- 通过翻译来生成新的数据,例如将中文先翻译成英文,然后再将英文翻译成中文,此时就可以生成一份与原句近似语义的新句。
- 将数据噪声来平滑(smoothing)数据集。
- 将预测语言模型用作同义词替换。
尽管这些技术是有效的,但实际上它们并不常用,因为相对于性能提高,它们具有很高的实现成本。在这篇论文中,作者为 NLP 提出了一套简单通用的数据增强技术,称为 EDA(简易数据增强)。作者系统地评估了五个基准分类任务上的 EDA,表明 EDA 在所有五个任务上都进行了重大改进,对于较小的数据集特别有用。
EDA 方法
对于训练集中给定的句子,随机执行以下操作:
- Synonym Replacement(SR):从不含停用词的句子中随机选择 n 个单词,然后随机挑选与之相关的同义词来替换这些单词。
- Random Insertion(RI):从不含停用词的句子中随机挑选一个单词,并找到这个单词的任意一个同义词,然后将这个同义词插入到当前句子的任意位置,重复该操作 n 次。
- Random Swap(RS):从句子中随机挑选两个单词,并交换它们的位置,重复该操作 n 次。
- Random Deletion(RD):以概率 p 随机删除句子中的每一个单词。
由于长句比短句有更多的单词,它们可以吸收更多的噪音,同时保持原有的类标签。为了进行补偿,作者提出根据句子的长度 l 来设置 SR、RI、RS 的变化单词数 n,式子如下所示:
$$
n = \alpha l
$$
其中,α 是一个参数,用以指示句子中需要变动单词的百分比。对于 RD 操作而言,将 α 设置为概率 p。
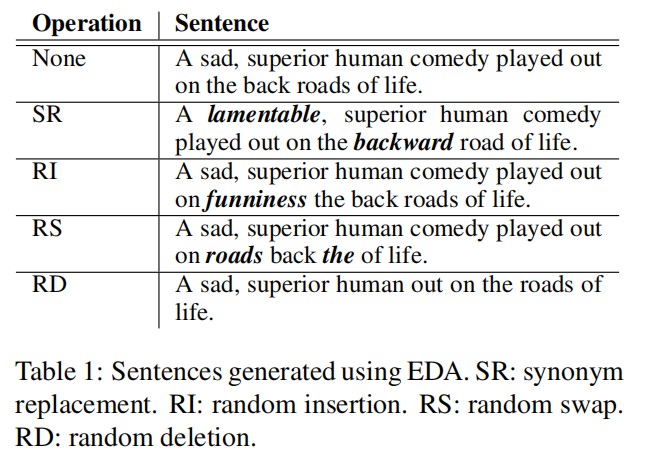
此外,对于每个原始句子,都会生成$n_{avg}$个增强句子。表 1 显示了增强句子的示例。观察表格可知,同义词替换已经开始被使用,但随机插入,交换和删除尚未得到广泛研究。
实验设置
作者选择五个基准文本分类任务和两个网络架构来评估 EDA。
基线数据集
作者对五个基准文本分类任务进行了实验:
- SST-2:Stanford Sentiment Treebank;
- CR:customer reviews;
- SUBJ:subjectivity/objectivity dataset;
- TREC:question type dataaset;
- PC:Pro-Con dataset。
此外,作者假设 EDA 对较小的数据集更有用,因此通过选择以下大小的数据集 $N_{train} = {500, 2000, 5000, \text{所有可用数据}}$ 来作为完整训练集的随机子集。
文本分类模型
作者针对文本分类中的两种流行模型进行了实验。
- 递归神经网络(RNN)适用于顺序数据,作者使用 LSTM-RNN。
- 卷积神经网络(CNN)也实现了文本分类的高性能。作者按照这篇论文《Convolutional neural networks for sentence classification》中所述实现。
结果
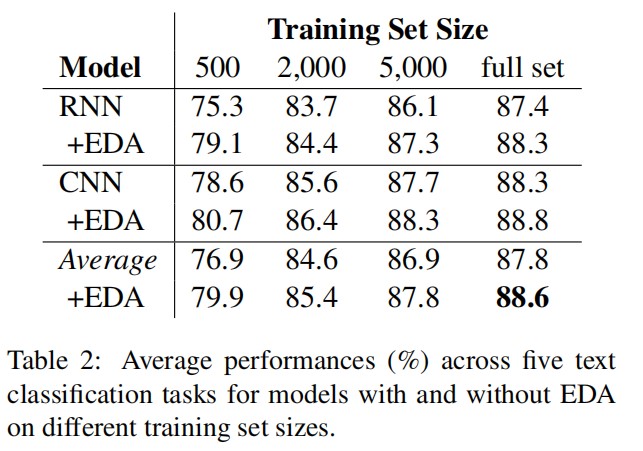
作者使用 CNNs 和 RNNs 对五个 NLP 任务进行 EDA 测试。对于所有的实验,对来自五个不同的随机种子的结果取平均值。分别对五个数据集运行带有和不带有 EDA 的 CNN 和 RNN 模型,以适应不同的训练集大小。表 2 显示了平均性能(%)。值得注意的是,完整数据集的平均改进为 0.8%,$N_{train} = 500$ 的平均改进为 3.0%。
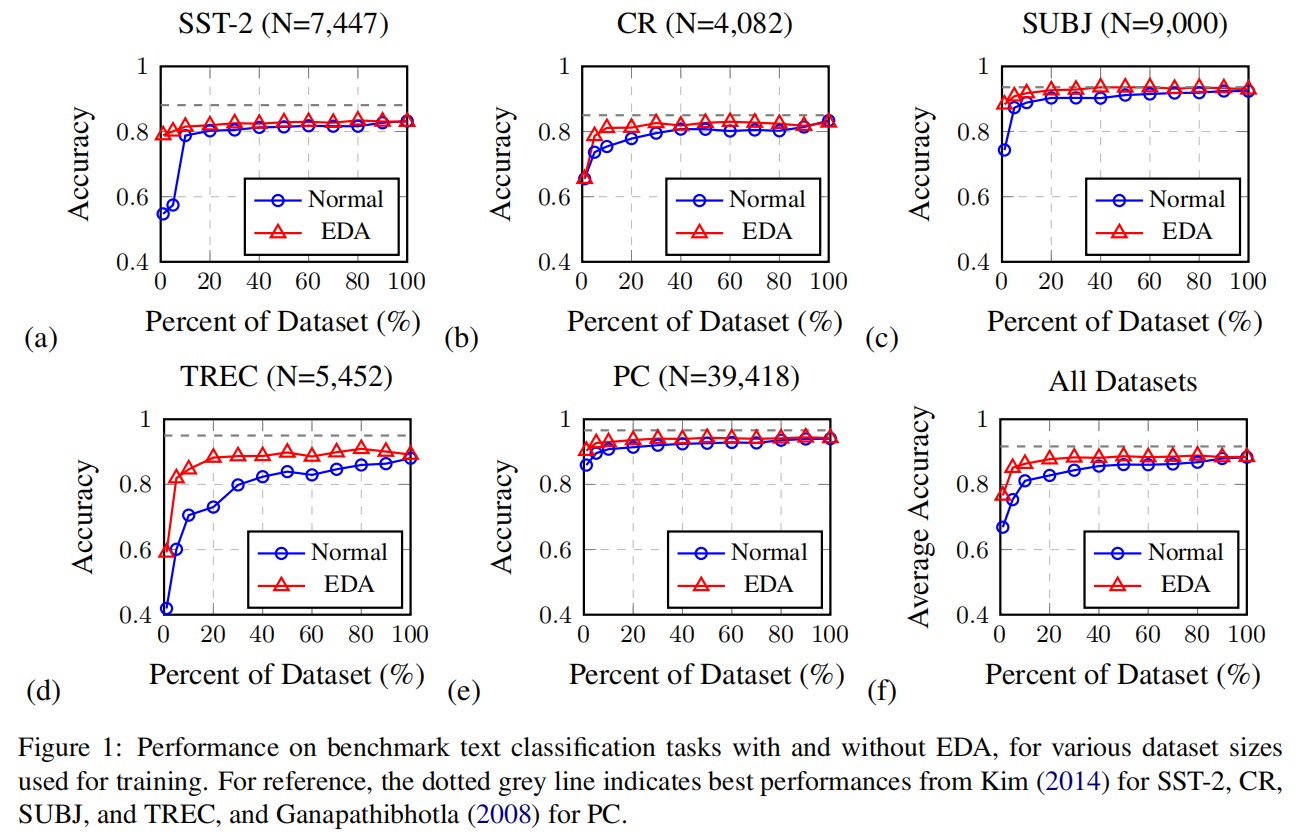
在较小的数据集上进行训练时,过拟合往往会更加严重。通过使用有限数量的可用训练数据进行实验,作者表明 EDA 对于较小的训练集具有更大的改进。作者按照以下训练集分区(%)进行正常训练和 EDA 训练:{1、5、10、20、30、40、50、60、70、80、90、100}。图 1(a)-(e)显示了每个数据集在有 EDA 和没有 EDA 情况下的性能,图1(f)显示了所有数据集的平均性能。
- 不使用数据增强,需要使用 100% 的训练数据达到 88.3% 的最佳平均准确率;
- 使用 EDA 训练的模型通仅使用可用训练数据集的 50% 就达到了 88.6%的平均准确率。
EDA 是否保留了真正的标签?
在数据增强中,往往在更改输入数据的同时保持类标签不变。但是,如果对句子进行了重大更改,则原始类标签可能不再有效。作者提供了一种可视化的方法去测试 EDA 操作是否明显地修改了增强句子的语义。
【步骤】:
- 在 pro-con 分类任务上不使用数据增强来训练 RNN 模型;
- 然后,在每一条原句上生成九条增强句子构成测试集,在测试集上应用 EDA。这些增强句子和原始句子一同输入到 RNN 模型中,接着从最后一层全连接层中抽取输出;
- 最后在上一步抽取得到的输出向量上使用 t-SNE,并绘制这些输出向量的 2D 表示。

观察上图可发现,由 EDA 产生的增强句子的潜在空间表示紧密地包围了原始句子的空间表示,这表明在大多数情况下,使用 EDA 产生的增强句子保留了它们原来句子的标签。
消融分析:EDA 分解
到目前为止,我们已经看到了令人鼓舞的实验结果。接下来,作者进行了消融研究,以探索 EDA 中每个操作的效果。先前已经使用了同义词替换,但尚未探索 RI、RS 和 RD 操作。有人可能会认为,EDA 的大部分性能提升都来自于同义词替换,因此作者将每个 EDA 操作隔离,以确定它们各自提高性能的能力,同时更改了增强参数 α={0.05,0.1,0.2,0.3,0.4,0.5} 见下图。
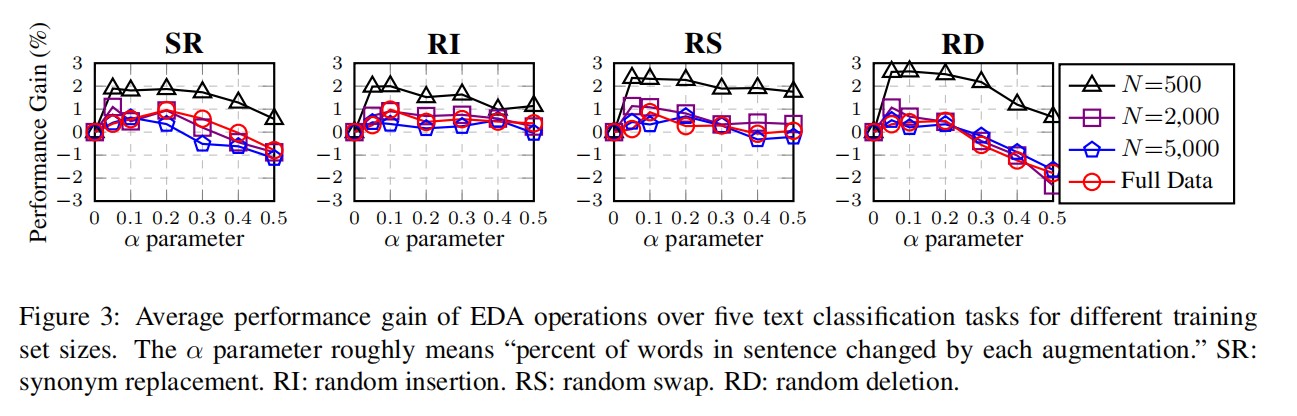
事实证明,所有四个EDA操作都有助于提高性能。
- SR:小 α 能够提高性能,但高 α 则会降低性能,这很可能是因为替换句子中的过多单词会改变句子本身。
- RI:对于不同的 α 值,性能提升更为稳定,这可能是因为在此操作中,句子中的原始单词及其相对顺序得以保留。
- RS:在 α ≤ 0.2 时获得了较高的性能增益,但是在 α ≥ 0.3 时却下降了,因为执行过多的交换等同于改组整个句子。
- RD:低 α 值具有最高的收益,但是在高 α 值时性能会受到严重损害,因为如果最多删除一半的单词,可能就很难再理解句子的意思。此外,删除一些关键词会对句子的语义造成极大的损失。
对于所有操作,较小的数据集上的改进更为显著,并且 α = 0.1 似乎是全面的“最佳位置”。
数据增强数量
接下来,作者通过实验来确定每个原始句子产生的增强句子数量是如何影响性能。在下图中,作者显式了 $n_{avg} = {1, 2, 4, 8, 16, 32}$ 所有数据集的平均性能。
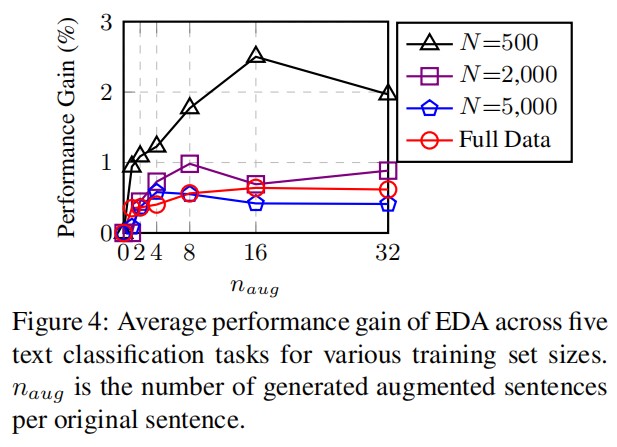
- 对于较小的训练集,过度拟合的可能性更大,因此生成许多增强句子会大大提高性能。
- 对于较大的训练集,每个原始句子添加四个以上的增强句子是无济于事的,因为当大量实际数据可用时,模型往往会适当地泛化(generalize)。
根据这些结果,作者建议使用下表中的参数。
| $N_{train}$ | α | $n_{avg}$ |
|---|---|---|
| 500 | 0.05 | 16 |
| 2000 | 0.05 | 8 |
| 5000 | 0.1 | 4 |
| More | 0.1 | 4 |
局限性
- 当数据充足时,EDA 性能提升可能很小。对于五个分类任务,使用完整数据集进行训练时,EDA 的平均性能提升不到 1%。尽管对于小型数据集,性能提升似乎很明显,但使用预训练模型时,EDA 可能不会产生实质性的改进。一项研究发现,使用 ULMFit 时 EDA 的改进可忽略不计,作者预计在 ELMo 和 BERT 上的结果和 ULMFit 一样——改进效果可忽略不计。
- 尽管作者评估了五个基准数据集,但其他有关 NLP 数据增强的研究使用了不同的模型和数据集,因此,与相关工作进行公平的比较是非常重要的。
总结
简单的数据增强操作可以提高文本分类任务的性能.尽管有时改进很少,但在较小的数据集上进行训练时,EDA 可以显着提高性能并减少过拟合。作者后续工作会考虑为 EDA 操作提供理论基础,并希望 EDA 的简单性能为进一步思考提供充分的理由。