论文阅读:Enhancing Retrieval and Managing Retrieval: A Four-Module Synergy for Improved Quality and Efficiency in RAG Systems
检索增强生成(RAG)技术利用大型语言模型(LLM)的上下文学习能力,生成更准确、更相关的响应。RAG 框架起源于简单的 “检索-阅读 ”方法,现已发展成为高度灵活的模块化范式。其中一个关键组件——查询重写模块,通过生成搜索友好的查询来增强知识检索。这种方法能使输入问题与知识库更紧密地结合起来。作者的研究发现了将 Query Rewriter 模块增强为 Query Rewriter+ 的机会,即通过生成多个查询来克服与单个查询相关的信息高原,以及通过重写问题来消除歧义,从而明确基本意图。作者还发现,当前的 RAG 系统在无关知识方面存在问题;为了克服这一问题,提出了知识过滤器。这两个模块都基于经过指令调整的 Gemma-2B 模型,共同提高了响应质量。最后一个确定的问题是冗余检索,作者引入了记忆知识库和检索触发器来解决这个问题。前者支持以无参数方式动态扩展 RAG 系统的知识库,后者优化了访问外部知识的成本,从而提高了资源利用率和响应效率。这四个 RAG 模块协同提高了 RAG 系统的响应质量和效率。这些模块的有效性已通过六个常见 QA 数据集的实验和消融研究得到验证。
方法介绍

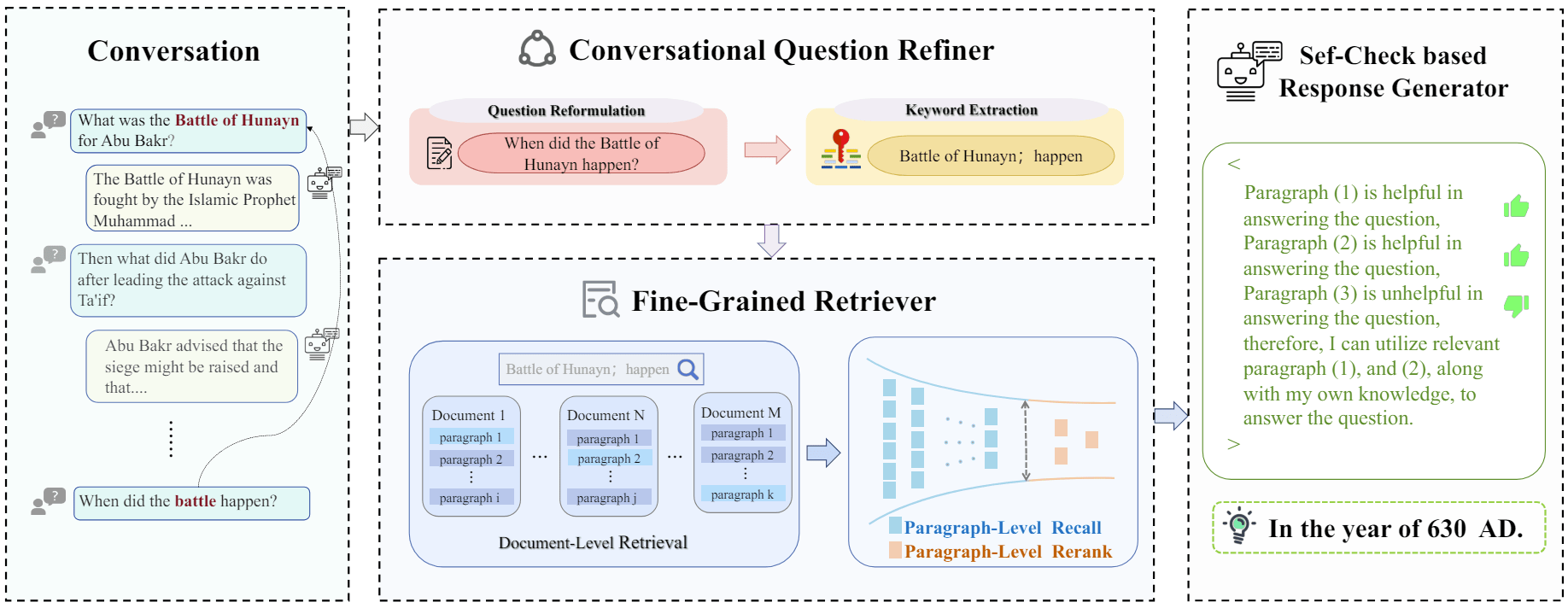
图 1:描述了将四个模块整合到基本的 “先检索后阅读”(绿色)管道中,以提高质量(橙色)和效率(紫色)的过程。蓝色文字表示从内存知识库检索的缓存知识,橙色文字表示从外部检索的知识。
Query Rewriter+
Query Rewriter+ 模块的设计包括两个主要功能:
- 将原始问题语义增强为重写问题;
- 生成多个搜索友好查询。
Query Rewriter+ 被表示为 $G_{\theta}(\cdot)$,将原始问题 p 作为输入:
$$
G_{\theta}(p) \rightarrow (s, Q)
$$
其中,s 表示重写的问题,$Q = {q_1, q_2, \ldots, q_{|Q|}}$ 是生成的查询集合。$G_{\theta}(\cdot)$ 的基本实现可以采用基于 prompt 的策略,利用任务描述、原始问题和示例来提示黑盒 LLM。这种方法充分利用了模型的上下文学习能力,通常能有效地进行问题重写和查询生成。不过,该方法的有效性高度依赖于针对特定领域数据集精心构建的 prompt,这限制了它的普遍实用性。此外,生成的 s 和 Q 可能质量不高,无法提高 RAG 性能。
为了解决这些局限性,作者提出了一种更具通用性且针对特定任务的方法。这包括对 $G_{\theta}(\cdot)$ 的 Gemma-2B 模型进行 LoRA 微调,利用通过 LLMs 生成和人工质量验证半自动构建的高质量数据集。该数据集由实例 (p、s、Q) 组成,每个实例都经过严格验证,以确保与直接询问带有 p 的 LLM 得出的答案相比,从 s 得出的答案能更准确地命中标注的答案。生成 (s,Q) 的提示模板如下:
1 | [Instruction]: Your task is to transform a potentially colloquial or jargon-heavy [Original Question] into a semantically enhanced Rewritten Question with a clear intention. Additionally, generating several search-friendly Queries that can help find relevant information for answering the question. You can consider the provided [Examples] and response following the [Format]. |
3.2 知识过滤器
由 LLM 生成的响应的准确性可能会因检索到的上下文存在噪声而大打折扣。为了缓解这一问题,作者引入了知识过滤器模块,旨在提高响应的准确性和鲁棒性。该模块利用 LLM 过滤掉不相关的知识。作者没有直接查询 LLM 来识别噪声,而是为此采用了自然语言推理(NLI)框架。
具体来说,对于重写的问题 s 和检索到的知识 k,自然语言推理任务会评估这些知识(作为前提)是否包含可靠的答案,或有助于回答问题的有用信息(作为假设)。由此得出的判断 j 可分为包含、矛盾或中性。知识过滤器的运行可以用数学方法表示为:
$$
F_{\theta}(s, k) \rightarrow j \in {entailment, contradiction, neural}
$$
如果 NLI 结果被归类为包含,则知识将被保留。我们可以根据具体数据集调整假设的强度。
- 对于单跳问题,可以设置更强的假设,要求知识包含直接明确的答案信息。
- 对于更复杂的多跳问题,可以设置较弱的假设,只要求知识包含可能有助于回答问题的信息。
当无法获得有效知识时,就会调用后退策略,即 LLM 在不借助外部知识扩充的情况下生成答案。知识过滤器在 Gemma-2B 模型上采用了 LoRA 微调方法,与基于提示的方法相比,具有更强的适用性和适应性。
通过向 GPT-4 提供了任务指令、重写的问题 s 以及知识上下文 k 作为提示,然后 GPT-4 会生成简要解释 e 和分类结果 j,最终生成数据实例 (s, k, (e, j)) 作为 NLI 训练数据集。提示模板如下:
1 | [Instruction]: Your task is to solve the NLI problem: given the premise in [Knowledge] and the hypothesis that "The [Knowledge] contains reliable answers aiding the response to [Question]". You should classify the response as entailment, contradiction, or neutral. |
考虑到 LLM 主要设计用于文本回归而非分类,仅使用 j 作为 Gemma-2B 的指令调整标签会妨碍 LLM 以生成方式准确执行分类任务。因此,除了 NLI 分类结果 j 之外,还将简明解释 e 作为标签的一部分。
3.3 记忆知识库
记忆知识库旨在缓存检索到的知识。知识的结构是标题-内容对,其中标题是一个简短的摘要,而内容则提供详细的上下文。记忆知识库通过添加新的标题-内容对以及用相同标题的新条目替换旧条目来进行更新。在数学上,记忆知识库可以表示为一个集合 $K = {k_1, k_2, \ldots, k_{|K|}}$。其中每个 $k_i$ 是一个标题内容对。
3.4 检索触发器
该模块可评估何时进行外部知识检索。该模块采用了一种基于校准的方法,将流行度作为衡量标准,以估计 RAG 系统对相关知识的熟练程度。
$K = {k_1, k_2, \ldots, k_{|K|}}$ 是记忆知识库中的知识集,$q_i \in Q$ 是生成的查询。查询 $q_i$ 与知识实例 $k_j \in K$ 之间的余弦相似度用 $S(q_i, title(k_j))$ 表示。查询 $q_i$ 的流行度 $Pop(q_i)$ 定义为:
$$
Pop(q_i) = |{k_j \in K | S(q_i, title(k_j)) \geq \tau }|
$$
其中,$\tau$ 是相似性阈值。使用流行度阈值$\theta$来确定查询在 RAG 系统知识范围之内或之外的边界条件。如果 $Pop(q_i) \geq \theta$,则认为查询 $q_i$ 在知识边界之内。
实验相关
Rewrite-Retrieve-Read 代表了当前对基本的“Retrieve-then-Read”pipeline 的最新改进。作者的方法将 Query Rewriter 增强为 Query Rewriter+,并引入了新的知识过滤器模块,从而增强现有的 RAG pipeline。
- Direct:直接向 LLM 提出原始问题。
- Rewriter-Retriever-Reader:在检索之前,使用 Query Rewriter 模块生成查询,获取外部知识。外部知识与原始问题一起用于提示生成响应。
- Rewriter+-Retriever-Reader:在检索之前,利用 Query Rewriter+ 模块生成多个查询,以获取外部知识并澄清原始问题。同时使用重写的问题和所有检索到的外部知识生成相应。
- Rewriter+-Retriever-Filter-Reader:Query Rewriter+ 模块在检索前应用,生成多个查询并澄清原始问题。知识过滤器用于剔除与改写问题无关的外部知识。然后使用过滤后的外部知识和改写后的问题生成最终相应。
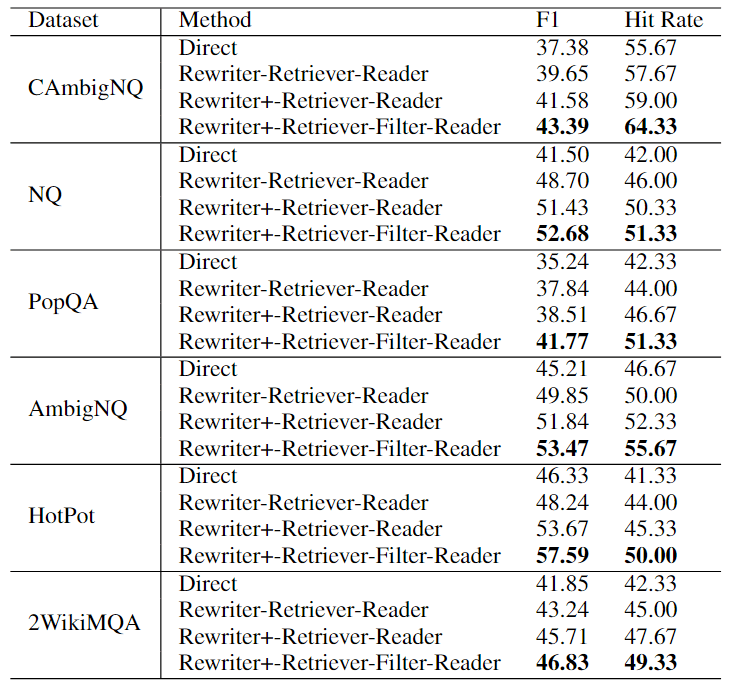
表 1:开放域 QA 性能。
- Rewriter+-Retriever-Reader 设置与 Rewriter-Retriever-Reader 设置进行比较:在所有数据集上,Query Rewriter+模块的性能都优于Query Rewriter模块,这证明了多重查询和澄清问题比单一查询和未澄清问题更能帮助RAG系统正确回答用户的问题,验证了 Query Rewriter+ 模块的优越性。
- Rewriter+-Retriever-Filter-Reader 设置与 Rewriter+-Retriever-Reader 设置进行比较:在传统的三步 RAG 流程中添加知识过滤器模块可显著提高性能。这表明,仅仅向 RAG 系统添加外部知识可能会带来不利影响,尤其是对于多跳问题。知识过滤模块能有效消除噪音和无关内容,提高 RAG 系统回复的准确性和稳健性。
此外,作者探讨在回答具有历史相似语义的重复性问题时,如何有效地减少冗余检索,以及研究了超参数 τ,以平衡效率和回答准确性。实验过程如下:
- 从 AmbigNQ 数据集中随机选取了 100 个问题,使用提出的方法生成回复。将知识检索器模块中的参数n设为5,没有使用网页片段作为知识实例的内容,而是访问了搜索到的 URL,阅读了整个网页文本,并使用 BM25 算法过滤掉了无关信息。响应结束后,网页内容被缓存到内存知识库中。
- 随后,又从 AmbigNQ 中挑选了 200 个与之前解决的问题语义相似的问题。这些问题在记忆知识库和检索触发器模块的支持下进行回复,受欢迎程度阈值θ设为3。
作者设计了几个指标来评估每个问题的资源成本,包括在 RAG pipeline 中花费的平均时间(时间成本)、外部知识实例的平均数量(外部知识)、内存知识实例的平均数量(内存知识)、过滤掉的知识实例的平均数量(无关知识)以及性能指标命中率。这些指标都是在答题过程中记录下来的。
表 2 列出了在不同 τ 设置下回答历史上相似问题时,回答质量和效率之间的权衡分析。一个重要发现是,当相似性阈值τ = 0.6 时,时间成本指标达到最小值。同时,外部知识度量也非常小,约为 4.39,大致相当于一次查询搜索。这表明这种配置主要是利用内存知识而不是外部资源来生成响应,从而提高了响应效率。值得注意的是,在 τ = 0.6 的设置下,答案质量并未受到严重影响,仍然非常接近在 τ = 1.0 时完全依赖外部知识所获得的答案质量。这表明,部署记忆知识模块可以显著缩短响应时间(约 46%),而不会严重影响答案质量。此外,将阈值调整到 0.8 还能提高应答质量,超过 τ = 1.0 时的应答质量,这表明利用高度相关的历史经验可以生成质量上乘的应答。
总结
在本文中,作者介绍了一种增强 RAG 系统的四个模块。
- Query Rewriter+ 模块:可生成更清晰的问题,以便 LLM 更好地理解意图,并生成多个语义不同的查询,以查找更多相关信息。
- 知识过滤器:通过消除不相关和嘈杂的上下文来完善检索到的信息,从而提高 LLM 生成响应的精确度和稳健性。
- 记忆知识库和检索触发模块:优化了历史数据的使用,并动态管理外部信息检索需求,提高了系统效率。
这些进步共同提高了 RAG 系统的准确性和效率。