论文阅读:FastBERT: a Self-distilling BERT with Adaptive Inference Time
像 BERT 这一类预训练语言模型已经被证明是高性能的。然而,在许多实际场景中,它们的计算成本往往很高,因为在资源有限的情况下,这种重型模型很难轻易实现。为了在保证模型性能的前提下提高其效率,作者提出了一种新型的具有自适应推断时间的速度可调的 FastBERT。在不同的需求下,推断速度可以灵活调整,同时避免了样本的冗余计算。此外,该模型在微调时采用了独特的自蒸机制,进一步实现了以最小的性能损失获得更大的计算效能。
作者的模型在 12 个英文和中文数据集中取得了可喜的结果,如果给定不同的提速阈值来进行速度性能的权衡,它能够比 BERT 加速 1 到 12 倍不等。
介绍
为了提高 BERT 类模型的推断速度,在模型加速方面做了很多尝试,如量化(《Compressing deep convolutional networks using vector quantization》)、权重剪枝(《Learning both weights and connections for efficient neural network》)、知识蒸馏(《Fitnets:Hints for thin deep nets》)等。作为最流行的方法之一,KD 需要额外的更小的学生模型,这些模型完全依赖于更大的教师模型,并以任务的准确性来换取计算的便利性(《Distilling the knowledge in a neural network》)。然而,减小模型大小以达到可接受的速度-精度平衡,只能解决一半的问题,因为模型仍然被设定为固定的,使它们无法应对请求量的剧烈变化。
通过检查许多 NLP 数据集,作者辨别出样本具有不同的难度水平。大模型可能会对简单的输入样本进行过度计算,而小模型对复杂的输入样本的预测则显得置信度不高。由于最近的研究()显示了预训练模型的冗余性,因此设计一个一刀切(one-size-fits-all)的模型是很有用的,它可以迎合不同复杂度的样本,并以最小的精度损失获得计算功效。
基于这种诉求,作者提出了 FastBERT,这是一个具有样本自适应机制的预训练模型,它可以动态调整执行层数从而减少计算步骤。该模型还有一个独特的自蒸馏过程,只需要对结构进行最小的改变,在一个框架内实现更快但一样准确的结果。作者的模型不仅达到了与 BERT 模型相当的速度提升(2 到 11 倍),而且与更大的预训练模型相比,也达到了具有竞争力的精度。
在 6 个中文和 6 个英文 NLP 任务上的实验结果表明,FastBERT 在计算量上实现了巨大的缩减,而在精度上的损失却非常小。本文的主要贡献可以概括为以下几点。
- 本文提出了一种实用的可调速的 BERT 模型,即 FastBERT,它可以平衡不同请求量的响应速度和准确性。
- 将样本自适应机制和自蒸馏机制相结合,首次提高了 NLP 模型的推断速度。它们的效果在 12 个 NLP 数据集上得到了验证。
- 该代码已开源 https://github.com/autoliuweijie/FastBERT。
方法论
在与上述工作不同的是,作者的方法将适应和蒸馏融合成一种新型的加速方法,如图 2 所示。
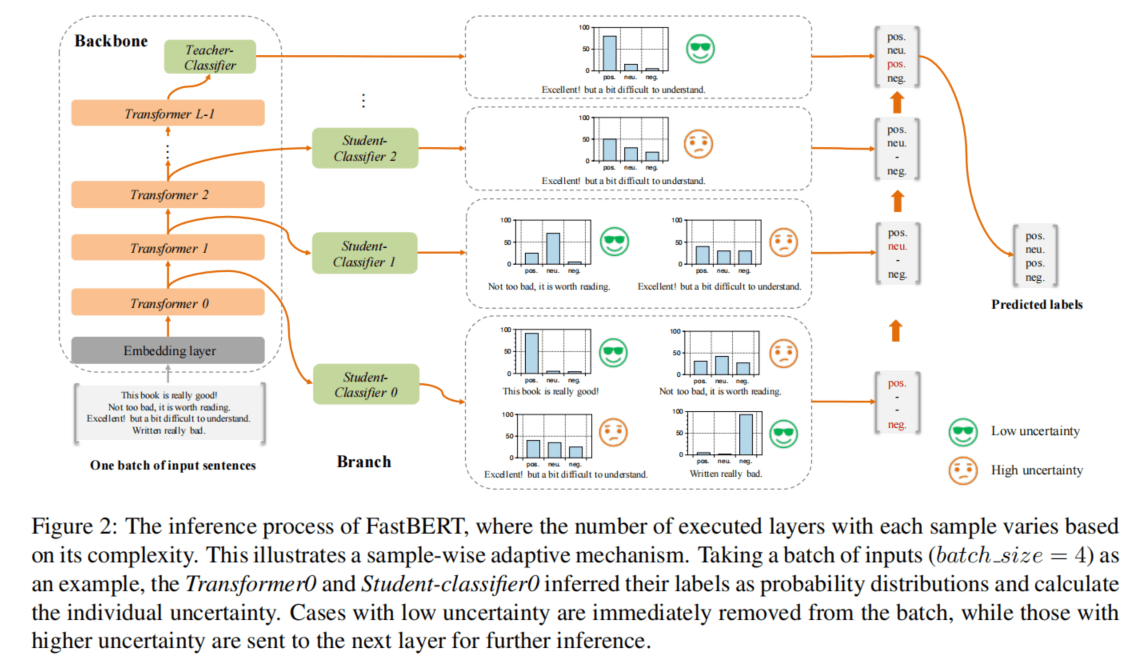
模型架构
如图 2 所示,FastBERT 由骨干和分支组成。主干是建立在 12 层 Transformer Encoder 的基础上,并增加了一个教师分类器,而分支则包括学生分类器,它附加在每个 Transformer 输出上,以实现提早输出。
骨干
骨干由三部分组成:嵌入层、包含堆叠的 Transformer 块的编码器和教师分类器。嵌入层和编码器的结构符合 BERT 的结构。给定句子长度 n,一个输入句子$s = [w_0, w_1, \ldots, w_n]$将 embedding 层转化为像(1)这样的向量表征序列 e。
$$
e = Embedding(s) \quad (1)
$$
其中 e 是 word、position 和 segment embeddings 的总和。接下来,编码器中的Transformer block 进行逐层特征提取,如(2)。
$$
h_i = Transformer_i(h_{i-1}) \quad (2)
$$
其中$h_i(i = -1, 0, 1, \ldots, L-1)$为第 i 层的输出特征,$h_{-1}=e$,L 为 Transformer 的层数。
在最终的编码输出之后,是一个教师分类器,它提取领域内特征用于下游任务的推断。它有一个全连接层,将维度从 768 缩小到 128。自注意力加入全连接层,向量维度不发生变化,全连接层的 softmax 函数将向量投射到 N 类指标 pt 如(3)所示,其中 N 是特定任务的类数。
$$
p_t = Teacher_Classifier(h_{L-1}) \quad (3)
$$
分支
为了给 FastBERT 具有更强的适应性,在每个 Transformer block 的输出端增加了与老师处于同一架构的多个分支,即学生分类器,以实现早期输出,特别是在某些简单的情况下。学生分类器可以描述为(4)。
$$
p_{s_i} = Student_Classifier_i(h_i) \quad (4)
$$
学生分类器是经过精心设计的,以平衡模型的准确性和推断速度,因为简单的网络可能会影响性能,而重度的注意力模块则会严重拖慢推断速度。事实证明,作者的分类器在保证精度的前提下更轻巧,详细验证在 4.1 节中展示。
模型训练
FastBERT 需要对骨干和学生分类器分别进行训练。当一个模块在训练时,另一个模块的参数会被冻结。模型的训练是为下游推断做准备,有三个步骤:主要骨干的预训练、整个骨干的微调和学生分类器的自蒸馏。
预训练
骨干的预训练与 BERT 的预训练类似。任何用于 BERT 类模型的预训练方法(如 BERT-WWM)、RoBERTa 和 ERNIE 都可以直接应用。需要注意的是,教师分类器因为只用于推断,所以此时保持不受影响。同时方便的是,FastBERT 甚至不需要自己进行预训练,因为它可以自由加载高质量的预训练模型。
骨干微调
对于每一个下游任务,作者将任务的具体数据插入到模型中,对主要骨干和教师分类器进行微调。教师分类器的结构如前所述。在这个阶段,所有的学生分类器都没有启用。
分支的自蒸馏
在对骨干进行良好的知识提取训练后,其输出作为包含原始嵌入和广义知识的高质量软标签,被提炼出来用于训练学生分类器。由于学生是相互独立的,因此将它们的预测结果 ps 分别与教师软标签 pt 进行比较,用(5)中的 KL-Divergence 来衡量差异。
$$
D_{KL}(p_s, p_t) = \sum_{i=1}^N p_s(i) \cdot log \frac{p_s(i)}{p_t(j)} \quad (5)
$$
由于 FastBERT 中有 L - 1 个学生分类器,因此用它们的 KL-Divergences 之和作为自蒸馏的总损失,其公式为(6)。
$$
Loss(p_{s_0}, \ldots, p_{s_{L-2}}, p_t) = \sum_{i=0}^{L-2} D_{KL}(p_{s_i}, p_t) \quad (6)
$$
其中$p_{s_i}$指的是学生分类器 i 输出的概率分布。
由于这个过程只需要教师输出,所以我们可以自由地使用无限量的无标签数据,而不是局限于有标签的数据。这就为我们提供了充足的自蒸馏资源,也就是说,只要教师允许,我们可以随时提高学生的成绩。此外,作者的方法与以往的蒸馏方法不同,因为教师和学生的输出位于同一个模型中。这个学习过程不需要额外的预训练结构,使得蒸馏完全是一个自学习的过程。
自适应推断
通过上述步骤,FastBERT 为以自适应的方式进行推理做好了准备,这意味着我们可以根据样本的复杂性来调整模型内执行的 encoder layer 的数量。在每个 Transformer 层,我们对每个样本进行判断,看当前层的推断是否足够可信,是否可以提前退出。
给定一个输入序列,学生分类器输出的不确定性是用公式(7)中的归一化熵计算所得。
$$
Uncertainty = \frac{\sum_{i=1}^N p_s(i)log p_s(i)}{log\frac{1}{N}} \quad (7)
$$
其中$p_s$是输出概率的分布,N 是类别的数量。
通过对不确定性的定义,作者提出了一个重要的假设。
- 假设 1. LUHA:不确定性越低,准确度就越高。
- 定义 1. Speed:区分高和低不确定性的阈值。
LUHA 在第 4.4 节中得到了验证。不确定性和速度的范围都在 0 到 1 之间。自适应推理机制可以被描述为:在 FastBERt 的每一层,相应的学生分类器将以评估的不确定性来预测每个样本的标签。不确定性低于该 speed 的样本将被筛选到早期输出,而不确定性高与该 speed 的样本将进入下一层。
直观的说,speed 越高,发送到上层的样本就越少,整体推理速度就越快,反之亦然。因此,speed 可以作为权衡推理精度和效率的一个超参数。
实验结果
作者在 12 个 NLP 数据集(6 个英文数据集和 6 个中文数据集)上验证 FastBERT 的有效性,并进行详细解释。
FLOPs 分析
浮点运算(FLOPs)是衡量模型计算复杂性的一个指标,它表示模型对单个进程进行的浮点运算的数量。FLOPs 与模型的运行环境(CPU、GPU 或 TPU)无关,只显示了计算的复杂性。一般来说,模型的 FLOPs 越大,推理时间就越长。在同样的精度下,低 FLOPs 的模型效率更高,更适合于工业用途。
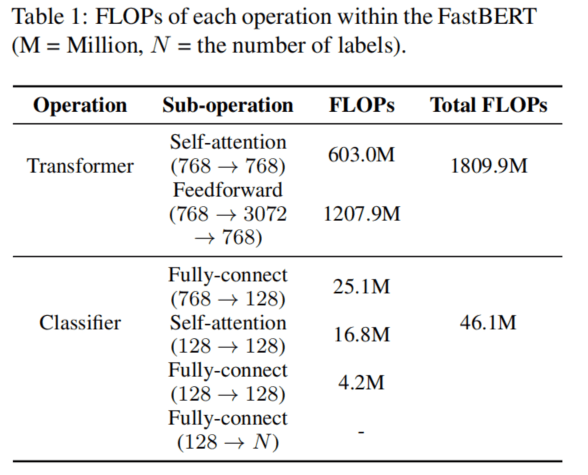
作者在表 1 中列出了两种结构的测量 FLOPs,从中可以推断出,分类器的计算负载(FLOPs)比 Transformer 的计算负载要轻得多。这是 FastBERT 加速的基础,因为尽管它增加了外的分类器,但它通过减少 Transformer 中的更多计算来实现加速。
基线和数据集
基线
在本节中,作者将 FastBERT 与两个基线进行比较。
- BERT:由 Google 发布的12 层 BERT-base 模型,该模型在 Wiki 语料库上进行了预训练。
- DistilBERT:最著名的具有 6 层 BERT 蒸馏方法是由 Huggingface 发布的。此外,作者用同样的方法分别蒸馏出具有 3 层和 1 层的 DistilBERT。
总结
在本文中,作者提出了 BERT 的一种快速版本,即 FastBERT。具体来说,FastBERT 在训练阶段采用了自蒸馏机制,在推理阶段采用了自适应机制,实现了损失较少精度来获取更高的效率。且首次将自蒸馏和自适应推理引入 NLP 模型。此外,FastBERT 在工业场景中具有一个非常实用的特点,即其推理速度是可以调整的。
在 12 个 NLP 数据集上的结果显示,该模型是有效果的。实验结果表明,FastBERT 可以比 BERT 快 2 到 3 倍,且性能不下降。如果,我们将容忍的精度损失放宽,该模型可以在 1 到 12 倍之间自由调整其速度。
此外,FastBERT 与其他类 BERT 的模型(如 BERT_WWM、ERNIE 和 RoBERTa)的参数设置保持兼容,这意味着这些公共可用的模型可以随时加载到 FastBERT 初始化中。