论文阅读:GLM:General Language Model Pretraining with Autoregressive Blank Infilling
已经有各种类型的预训练架构,包括自动编码模型(如 BERT),自回归模型(如 GPT),以及编码器-解码器模型(如 T5)。然而,在自然语言理解(NLU)、无条件生成和有条件生成等三大类任务中,没有一个预训练框架的表现是最好的。作者提出了一个基于自回归填空的通用语言模型(GLM)来应对这一挑战。GLM 通过增加 2D 位置编码和允许以任意顺序预测 span 来改进填空预训练,这使得 NLU 任务的性能比 BERT 和 T5 有所提高。同时,GLM 可以通过改变空白的数量和长度为不同类型的任务进行预训练。在横跨 NLU、有条件和无条件生成的广泛的任务上,GLM 在给定相同的模型大小和数据的情况下优于 BERT、T5 和 GPT,并从一个参数为 BERT-Large 1.25 倍的单一预训练模型中获得了最佳性能,证明了其对不同下游任务的通用性。
介绍
在无标签文本上进行预训练的语言模型大大推进了各种 NLP 任务的技术水平,从自然语言理解(NLU)到文本生成。在过去的几年里,下游任务的表现以及参数的规模也不断增加。
一般来说,现有的预训练框架可以分为三个系列:自回归、自编码和编码器-解码器模型。
- 自回归模型,如 GPT(Radford等人,2018a),学习从左到右的语言模型。虽然它们在长文生成中获得了成功,并且在扩展到数十亿个参数时表现出少许学习能力(Radford等人,2018b;Brown等人,2020),但其固有的缺点——单向注意力机制,不能完全捕捉 NLU 任务中上下文词之间的依赖关系。
- 自编码模型,如 BERT(Devlin等人,2019年),通过去噪目标学习双向上下文编码器,如 MLM。编码器生成适合自然语言理解任务的上下文化表征,但不能直接应用于文本生成。
- 编码器-解码器模型对编码器采用双向注意力,对解码器采用单向注意力,以及它们之间的交叉注意力。它们通常被部署在条件生成任务中,如文本摘要和回答生成中。T5 通过编码器-解码器模型统一了 NLU 和条件生成,但需要更多的参数来匹配基于 BERT 模型的性能,如 RoBERTa 和 DeBERTa。
无条件生成指的是将文本作为语言模型生成,而不进行微调;而有条件生成指的是序列到序列的任务。
这些预训练框架都不够灵活,无法在所有的 NLP 任务中发挥竞争优势。以前的工作曾试图通过多任务学习将不同的框架的目标结合起来,以达到统一。然而,由于自编码和自回归目标的性质不同,简单的统一不能完全继承两个框架的优点。
在本文中,作者提出了一个名为 GLM(通用语言模型)的预训练框架,基于自回归填空。作者按照自编码的思路,从输入文本中随机地空出连续的 span tokens,并按照自回归预训练的思路,训练模型来依次重建这些 span tokens(见图1)。
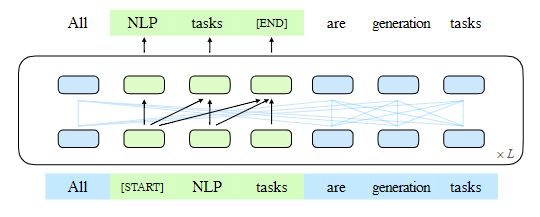
图 1:GLM 的说明。我们把文本 span(绿色部分)清空,并以自回归方式生成(一些注意力的边缘被省略了,参见图 2)。
虽然填空已经在 T5(Raffel等人,2020)中用于文本到文本的预训练,但作者提出两项改进,即 span shuffle 和 2D 位置编码。经验表明,在参数数量和计算成本相同的情况下,GLM 在 SuperGLUE 基准上以 4.6% - 5.0% 的巨大优势明显优于 BERT,并且在对类似大小的语料库(158GB)进行预训练时,GLM 优于 RoBERTa 和 BART。在参数和数据较少的 NLU 和生成任务上,GLM 也明显优于 T5。
受 Pattern-Exploiting Training(PET)(Schick和Schütze,2020a)的启发,作者将 NLU 任务重新表述为模仿人类语言的手工制作的 cloze 问题。与 PET 使用的基于 BERT 的模型不同,GLM 可以通过自回归填空自然地处理对 cloze 问题的多 token 答案。
此外,作者表明,通过改变缺失 span 的数量和长度,自回归填空目标可以为有条件和无条件的生成预训练语言模型。通过对不同预训练目标的多任务学习,单个 GLM 可以在 NLU 和(有条件和无条件的)文本生成方面表现出色。根据经验,与独立的基线相比,带有多任务预训练的 GLM 通过共享参数,在 NLU、条件文本生成和语言建模任务中都取得了改进。
GLM 预训练框架
作者提出了一个通用的预训练框架 GLM,它基于一个新颖的自回归填空目标。GLM 将 NUL 任务制定为包含任务描述的 cloze 问题,这些问题可以通过自回归生成来回答。
预训练目标
自回归填空
GLM 是通过优化自回归填空目标来训练的。给定一个输入文本 $x = [x_1, \ldots, x_n]$,对多个文本 span ${s_1, \ldots, s_m}$ 进行采样,其中每个 span $s_i$ 对应于 x 中的一串连续 token $[s_{i,1}, \ldots, s_{i, l_i}]$。每个 span 都被替换成一个 [MASK] token,形成一个被破坏的文本 $x_{corrupt}$。该模型以自回归的方式预测被破坏的文本中缺少的 token,这意味着当预测一个 span 中缺少的 token 时,该模型可以访问被破坏的文本和以前预测的 span。为了充分捕捉不同 span 之间的相互依存关系,作者随机地对 span 的顺序进行了置换,类似于置换语言模型(permutation language model)。形式上,让 $Z_m$ 是长度为 m 的索引序列 $[1, 2, \ldots, m]$ 的所有可能的排列组合的集合,$s_{z \lt i}$ 是 $[s_{z_1}, \ldots, s_{z_{i-1}}]$,定义预训练目标为:
$$
\max \theta \mathbb{E}{\boldsymbol{z} \sim Z_m}\left[\sum_{i=1}^m \log p_\theta\left(\boldsymbol{s}{z_i} \mid \boldsymbol{x}{\mathrm{corrupt}}, \boldsymbol{s}{\boldsymbol{z}{<i}}\right)\right] \tag{1}
$$
我们总是按照从左到右的顺序生成每个空白处的 token,也就是说,生成 span $s_i$ 的概率被分解为:
$$
\begin{aligned}
& p_\theta\left(s_i \mid x_{\text {corrupt }}, s_{z_{<i}}\right) \
= & \prod_{j=1}^{l_i} p\left(s_{i, j} \mid x_{\text {corrupt }}, s_{z_{<i}}, s_{i,<j}\right)
\end{aligned} \tag{2}
$$
作者通过以下技术实现自回归填空目标。输入 x 被分为两部分。A 部分是被破坏的文本 $x_{corrupt}$,B 部分由被 mask 的 span 组成。A 部分的 token 可以相互关注,但不能关注 B 部分的任何 token。B 部分的 token 可以关注 A 部分和 B 部分的先行词,但不能关注 B 部分的任何后续 token。为了使自回归生成,每个 span 都有特殊的 token [START] 和 [END],分别用于输入和输出。通过这种方式,该模型在一个统一的模型中自动学习双向编码器(针对 A 部分)和单向编码器(针对 B 部分)。图 2 说明了 GLM 的实施情况。
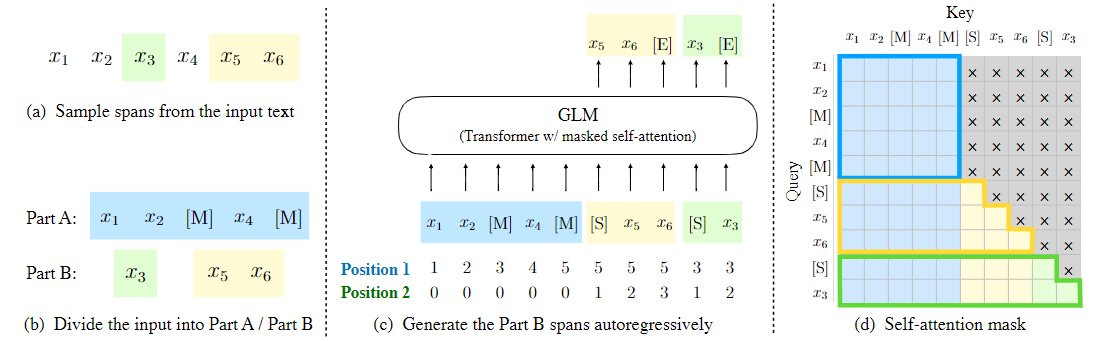
图 2:GLM 预训练。(a)原始文本是 $[x_1, x_2, x_3, x_4, x_5, x_6]$。两个 span $[x_3]$ 和 $[x_5, x_6]$ 被抽样。(b)在 A 部分中用 [M] 替换取样的 span,在 B 部分中对 span 进行洗牌。(c)GLM 自动生成 B 部分,每个 span 都以 [S] 作为输入,并以 [E] 作为输出。2D 位置编码表示 span 和 span 内的位置。(d)自注意力的 mask。灰色区域被 mask。A 部分 token 可以关注自己(蓝筐),但不能关注 B。B 部分的 token 可以关注 A 和它们在 B 中的先行词(黄色和绿色框对应于两个 span)。[M] := [MASK],[S] := [START],[E] := [END]。
作者随机抽取长度为 $\lambda = 3$ 的泊松分布中的 span。反复地对新的 span 进行抽样,直到至少 15% 的原始 token 被 mask。根据经验,15% 的比例对于下游 NLU 任务的良好表现至关重要。
多任务预训练
GLM mask 短 span,适用于 NLU 任务。然而,对预训练一个能同时处理 NLU 和文本生成的单一模型感兴趣。然后,研究了一个多任务预训练设置,其中生成较长文本的第二个目标与填空目标共同优化。作者考虑以下两个目标:
- 文档级别:对单个 span 进行采样,其长度从原始长度的 50%-100% 的均匀分布中抽出。该目标旨在生成长文本。
- 句子级别:限制被 mask span 必须是完整的句子。多个 span(句子)被取样,以覆盖 15% 的原始 token。这个目标是针对 seq2seq 任务,其预测往往是完整的句子或段落。
这两个新目标的定义与原目标相同,即公式 1。唯一的区别是 span 的数量和长度。
模型架构
GLM 使用单个 Transformer,并对架构进行了一些修改:1)重新安排了层归一化和残差连接的顺序,这对于大规模语言模型避免数字错误已被证明至关重要;2)使用单个的线性层进行输出 token 预测;3)用 GeLU 代替 ReLU 激活函数。
2D 位置编码
自回归填空任务的挑战之一是如何对位置信息进行编码。Transformer 依靠位置编码来注入 token 的绝对和相对位置。作者提出了 2D 位置编码来解决这一难题。具体来说,每个 token 都有两个位置标识来编码。
- 第一个位置标识代表了被破坏文本$x_{corrupt}$中的位置。对于被 mask 的 span,它是相应的 [MASK] token 的位置。
- 第二个位置标识代表 span 内的位置。对于 A 部分的 token,它们的第二个位置标识是 0。对于 B 部分的 token,它们的范围从 1 到 span 的长度。这两个位置标识通过可学习的嵌入表被投射到两个向量中,这两个向量都被添加到输入的 token 嵌入中。
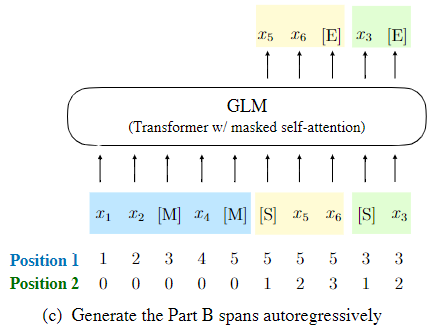
该编码方法确保了模型在重建时不知道被 mask span 的长度。与其他模型相比,这是一个重要的区别。例如,XLNet 对原始位置进行编码,从而可以感知缺失的 token 数量,SpanBERT 用多个 [MASK] token 替换 span,并保持长度不变。作者的设计适合下游任务,因为通常生成文本的长度事先是未知的。
微调 GLM
通常,对于下游的 NLU 任务,线性分类器将由预训练模型产生的序列或 token 的表征作为输入,并预测正确的标签。这些做法与生成式预训练任务不同,导致预训练和微调之间的不一致。
相反,按照 PET,将 NLU 分类任务重新表述为填空的生成任务。具体来说,给定一个有标签的数据(x, y),通过一个包含单个 mask token 的模式将输入文本 x 转换为一个 cloze 问题 c(x)。模式是用自然语言写的额,以表示任务的语义。例如,一个情感分类任务可以被表述为“{SENTENCE}. It’s really [MASK]”。候选标签$y \in Y$也被映射到 cloze 的答案上,称为 verbalizer v(y)。在情感分类中能够,positive 和 negative 的标签被映射到 good 和 bad 的词语。
给定 x 预测 y 的条件概率是:
$$
p(y \mid \boldsymbol{x})=\frac{p(v(y) \mid c(\boldsymbol{x}))}{\sum_{y^{\prime} \in \mathcal{Y}} p\left(v\left(y^{\prime}\right) \mid c(\boldsymbol{x})\right)} \tag{3}
$$
其中 Y 是标签集。因此,该句子是 position 或 negative 的概率与预测空白处的 good 或 bad 成正比。然后,用交叉熵损失对 GLM 进行微调(见图 3)。
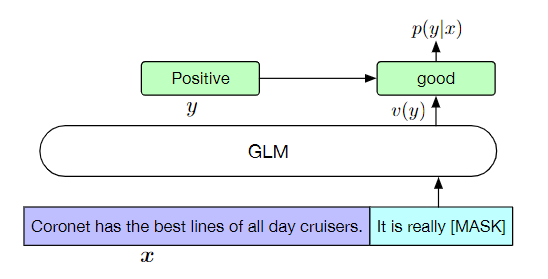
图 3:将情感分类任务定义为 GLM 填空。
对于文本生成任务,给定的上下文构成输入的 A 部分,并在最后附加一个 [MASK] token。该模型自回归生成 B 部分的文本。我们可以直接将预训练的 GLM 应用于无条件生成,或者在下游的条件生成任务上进行微调。
讨论和分析
在这一节中,我们讨论 GLM 和其他预训练模型之间的区别。主要关注的是如何将它们适应于下游的填空任务。
- 与 BERT 的比较:正如 Yang 等人所指出的,由于 MLM 的独立性假设,BERT 未能捕捉到被 mask token 之间的相互依赖关系。BERT 的另一个缺点是,它不能正确地填补多个 token 的空白。为了推断长度为 l 的答案的概率,BERT 需要连续进行 l 次预测。如果长度未知,我们可能需要列举所有可能的长度,因为 BERT 需要根据长度来改变 [MASK] token 的数量。
- 与 XLNet 的比较:GLM 和 XLNet 都是用自回归目标进行预训练的,但它们之间有两个区别。首先,XLNet 使用破坏前的原始位置编码。在预测过程中,需要知道或列举出答案的长度,这与 BERT 的问题相同。其次,XLNet 使用了双流自注意力机制,而不是右移,以避免 Transformer 内部的信息泄露。它使预训练的时间成本增加了一倍。
- 与 T5 的比较:T5 提出了一个类似的填空目标来预训练一个编码器-解码器 Transformer。T5 对编码器和解码器使用独立的位置编码,并依靠多个哨兵 token 来区分被 mask 的 span。在下游任务中,只有一个哨兵 token 被使用,导致了模型容量的浪费和预训练与微调之间的不一致。此外,T5 总是以固定的从左到右的顺序预测 span。因此,正如第 3.2 和 3.3 节所述,在参数和数据较少的情况下,GLM 在 NLU 和 seq2seq 任务上的表现可以明显优于 T5。
- 与 UniLM 的比较:UniLM 在自编码框架下,通过在双向、单向和交叉注意力中改变注意力掩码,结合了不同的预训练目标。然而,UniLM 总是用 [MASK] token 来替换被 mask 的 span,这限制了它对被 mask span 及其上下文之间的依赖关系进行建模的能力。GLM 送入前一个 token,并自动生成下一个 token。在下游生成任务上对 UniLM 进行微调,也依赖于 MLM,其效率较低。UniLMv2 对生成任务采用部分自回归建模,同时对 NLU 任务采用自编码目标。相反,GLM 将 NLU 和生成任务与自回归预训练统一起来。
实验
为了与 BERT 进行公平的比较,使用 BooksCorpus 和英语维基百科作为预训练数据。使用 BERT 的 uncased wordpiece tokenizer,词汇量为 30k。作者用与 BERT-Base 和 BERT-Large 相同的架构来训练 GLM-Base 和 GLM-Large,分别包含 110M 和 340M 的参数。
对于多任务预训练,作者用填空目标和文档级或句子级目标的混合物训练两个 Large-sized 模型,表示为 GLM-Doc 和 GLM-Sent。此外,通过文档级的多任务预训练,训练两个较大的 GLM 模型,分别为 410M(30 层,隐藏层大小 1024,16 个注意力头)和 515M(30 层,隐藏层大小 1152,18 个注意力头)参数,分别表示为 GLM 410M 和 GLM 515M。
为了与 SOTA 模型进行比较,还用与 RoBERTa 相同的数据、tokenizer 和超参数来训练一个大尺寸模型,表示为 GLM-RoBERTa。由于资源的限制,只对模型进行 250000 步的预训练,这是 RoBERTa 和 BART 训练步数的一半,在训练 tokens 的数量上接近于 T5。更多的实验细节可以在附录 A 中找到。
SuperGLUE
为了评估预训练的 GLM 模型,作者在 SuperGLUE 基准上进行了实验,并报告了标准指标。SuperGLUE 由 8 个具有挑战性的 NLU 任务组成。作者将分类任务重新表述为用人类精心设计的 cloze 问题来填空,遵循 PET。然后,如第 2.3 节所述,对每个任务的预训练的 GLM 模型进行微调。cloze 问题和其他细节可在附录 B.1 中找到。
为了与 GLM-Base 和 GLM-Large 进行公平的比较,选择 BERT-Base 和 BERT-Large 作为基线,它们在相同的语料库上进行预训练,并且时间相近。作者报告了标准微调的性能(即对 [CLS] token 表征的分类)。第 3.4 节中报告了 BERT 的性能与 cloze 问题。为了与 GLM-RoBERTa 进行比较,作者选择 T5、BART-Large 和 RoBERTa-Large 作为基线。T5 在参数数量上与 BERT-Large 没有直接的匹配,所以同时展示了 T5-Base(2.2 亿参数)和 T5-Large(7.7 亿参数)的结果。所有其他基线的规模都与 BERT-Large 类似。
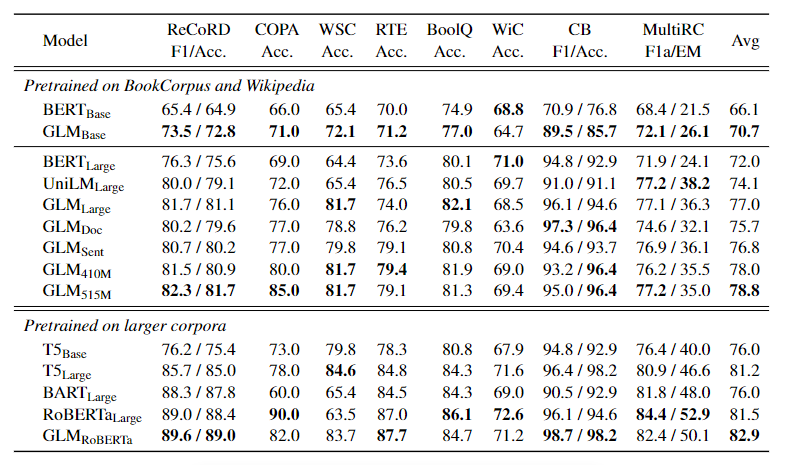
表 1:在 SuperGLUE 验证集上的结果。
表 1 显示了结果。在相同的训练数据量下,GLM 在大多数任务中的基础或大型架构上始终优于 BERT。唯一的例外是 WiC(词义歧义)。平均而言,GLM-Base 的得分比 BERT-Base 高 4.6%,GLM-Large 的得分比 BERT-Large 高 5.0%。这清楚地表明了该方法在 NLU 任务中的优势。在 RoBERTa-Large 的设置中,GLM-RoBERTa 仍然可以实现对基线的改进,但幅度较小。
具体来说,GLM-RoBERTa 的表现优于 T5-Large,但规模只有其一半。作者还发现,BART 在具有挑战性的 SuperGLUE 基准测试中表现不佳。作者猜测这可以归因于编码器-解码器架构的低参数效率和去噪的序列对序列目标。
多任务预训练
评估 GLM 在多任务设置中的表现。在一个训练 batch 中,以相同的机会对短 span 和长 span(文档级和句子级)进行采样。对多任务模型进行评估,包括 NLU、seq2seq、填空和零样本语言建模。
SuperGLUE
对于 NLU 任务,在 SuperGLUE 基准上评估模型。结果也显示在表 1 中。
作者观察到,在多任务预训练中,GLM-Doc 和 GLM-Sent 的表现比 GLM-Large 略差,但仍优于 BERT-Large 和 UniLM-Large。在多任务模型中,GLM-Sent 平均比 GLM-Doc 好 1.1%。将 GLM-Doc 的参数增加到 410M(1.25 x BERT-Large)会导致比 GLM-Large 更好的性能。具有 515M 参数(1.5 x BERT-Large)的 GLM 可以表现得更好。
Sequence-to-Sequence
考虑到现有的基线结果,作者使用 Gigaword 数据集进行摘要概括,以及 SQuAD 1.1 数据集进行问题生成,作为在 BookCorpus 和 Wikipedia 上预训练模型的基准。此外,使用 CNN/DailyMail 和 XSum 数据集进行摘要概括,作为在更大语料库上预训练模型的基准。
在 BookCorpus 和 Wikipedia 上训练的模型的结果显示在表 3 和表 4 中。
表 3:Gigaword 摘要概括结果。
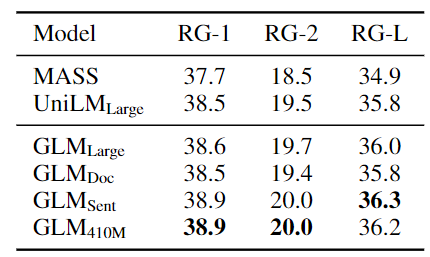
表 4:SQuAD 问题生成结果
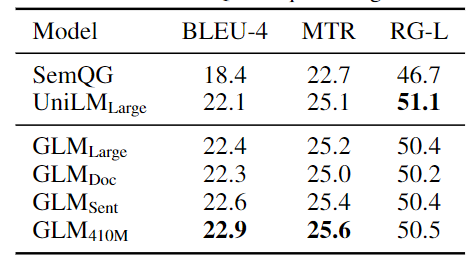
观察到,GLM-Large 可以在两个生成任务上实现与其他预训练模型相匹配的性能。GLM-Sent 可以比 GLM-Large 表现得更好,而 GLM-Doc 的表现比 GLM-Large 略差。这表明文档级别的目标,即教导模型扩展给定的上下文,对条件生成的帮助较小,而条件生成的目的是从上下文中提取有用的信息。
将 GLM-Doc 的参数增加到 410M,在这两项任务中都能获得最佳性能。在更大的语料库上训练的模型的结果显示在表 2 中。GLM-RoBERTa 可以达到与 seq2seq BART 模型相匹配的性能,并且超过了 T5 和 UniLMv2。
Text Infilling
文本填充是预测与周围上下文一致的缺失文本的任务。GLM 是用自回归填空目标训练的,因此可以直接解决这个任务。作者在 Yahoo 答案数据集上评估了 GLM,并与空白语言模型(BLM)进行了比较,后者是专门为文本填充设计的模型。

表 5:Yahoo 文本填充的 BLUE 分数。† 表示(Shen 等人,2020)论文中的结果。
从表 5 的结果来看,GLM 以较大的幅度超过了以前的方法(1.3 到 3.9 BLUE),在这个数据集上达到了最先进的结果。我们注意到,GLM-Doc 的表现略逊于 GLM-Large,这与在 seq2seq 实验中的观察结果一致。
语言建模
大多数语言建模数据集,如 WikiText103,是由维基百科文档构建的,而作者的预训练数据集已经包含了这些文档。因此,在预训练数据集的一个测试集上评估语言建模的困惑度,该测试集包含大约 2000 万个 token,表示为 BookWiki。作者还在 LAMBADA 数据集上评估了 GLM,该数据集测试了系统对文本中长距离依赖关系的建模能力。其任务是预测一段话的最后一个字。作为基线,作者用与 GLM-Large 相同的数据和 tokenization 来训练一个 GPT-Large 模型。结果显示在图 4 中。

图 4:零样本语言建模结果。
所有的模型都是在零样本的情况下进行评估的。由于 GLM 学习的是双向注意,所以作者也在上下文被双向注意编码的情况下评估 GLM。在预训练期间,如果没有生成目标,GLM-Large 无法完成语言建模任务,其困惑度大于 100。在参数数量相同的情况下,GLM-Doc 的表现比 GPT-Large 差。这是预期的,因为 GLM-Doc 也优化了填空目标。将模型的参数增加到 410M(GPT-Large 的 1.25 倍),导致性能接近于 GPT-Large。
GLM-515M(GPT-Large 的 1.5 倍)可以进一步优于 GPT-Large。在参数数量相同的情况下,用双向注意力对上下文进行编码可以提高语言建模的性能。在这种设置下,GLM-410M 的性能超过了 GPT-Large。这就是 GLM 比单向 GPT 的优势。作者还研究了 2D 位置编码对长文本生成的贡献。发现去除 2D 位置编码会导致语言建模的准确率降低和困惑度提高。
总结
作者得出结论,GLM 在自然语言理解和生成任务中有效地共享模型参数,比独立的 BERT、编码器-解码器或 GPT 模型取得更好的性能。
消融分析
表 6 显示了对 GLM 的消融分析。
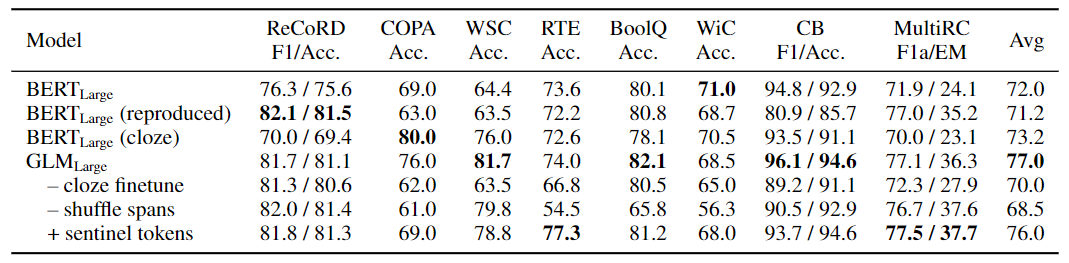
表 6:在 SuperGLUE 验证集上的消融分析(T5 约等于 GLM - shuffle spans + 哨兵 tokens)。
- 首先,为了提供与 BERT 的 apple-to-apple 比较,用作者自己的实现、数据和超参数训练一个 BERT-large 模型(第 2 行)。其性能比官方的 BERT-large 略差,比 GLM-large 明显差。这证实了 GLM 在 NLU 任务上比 Masked LM 预训练的优越性。
- 其次,展示了 GLM 微调为序列分类器(第 5 行)和 BERT 与 cloze-style 微调(第 3 行)的 SuperGLUE 性能。与采用 cloze-style 微调的 BERT 相比,GLM 得益于自回归预训练。特别是在 ReCoRD 和 WSC 上,口头禅(verbalizer)由多个 token 组成,GLM 一直优于 BERT。这显示了 GLM 在处理可变长度空白方面的优势。
- 另一个观察结果是,cloze 表述对于 GLM 在 NLU 任务上的表现至关重要。对于大型模型来说,cloze-style 的微调可以将性能提高 7 分。
- 最后,比较了具有不同预训练设计的 GLM 变体,以了解其重要性。
- 第 6 行显示,去掉 span shuffle(总是从左到右预测被 mask 的 span)会导致 SuperGLUE 的性能严重下降。
- 第 7 行显示,使用不同的哨兵 token,而不是单一的 [MASK] token 来代表不同的 mask span。该模型的表现比标准 GLM 差。作者假设,学习不同的哨兵 token 会浪费一些建模能力,这些 token 在下游任务中没有使用,只有一个空白。
- 图 4 中显示,去除 2D 位置编码的第 2 个维度会损害长文本生成的性能。
我们注意到,T5 是以类似的填空目标进行预训练的。GLM 在三个方面有所不同:
- GLM 由一个编码器组成。
- GLM 对 mask 的 span 进行洗牌(shuffle)。
- GLM 使用一个 [MASK] 而不是多个哨兵 token。
虽然由于训练数据和参数数量的不同,我们不能直接比较 GLM 和 T5,但表 1 和表 6 的结果已经证明了 GLM 的优势。
相关工作
将 NLU 作为生成任务
以前,预训练语言模型通过对所学表征的线性分类器完成 NLU 的分类任务。GPT-2(Radford 等人,2018b)和 GPT-3(Brown 等人,2020)表明,生成式语言模型可以通过直接预测正确答案来完成 NLU 任务,如问题回答,不需要进行微调,给定任务指示或一些标注的数据即可。然而,由于单向注意力的限制,生成模型需要更多的参数来工作。最近,PET(Schick 和 Schütze,2020a,b)提出将输入的数据重新表述为 cloze 问题,其模式与预训练语料库中的少样本类似。研究表明,与基于梯度的微调相结合,PET 在少样本的设置中可以达到比 GPT-3 更好的性能,而只需要其 0.1% 的参数。同样,Athiwaratkun 等人(2020)和 Paolini 等人(2020)将结构化预测任务,如序列标注和关系提取,转换为序列生成任务。
填空语言模型
Donahue 等人(2020)和 Shen 等人(2020)也研究了填空模型。与他们的工作不同,作者用填空目标预先训练语言模型,并评估它们在下游 NLU 和生成任务中的表现。
总结
GLM 是一个用于自然语言理解和生成的通用预训练框架。作者表明,NLU 任务可以被表述为条件生成任务,因此可以通过自回归模型来解决。GLM 将不同任务的预训练目标统一为自回归填空、混合注意力掩码和新的2D 位置编码。经验表明,GLM 在 NLU 任务中的表现优于以前的方法,并且可以有效地共享不同任务的参数。