论文阅读:Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
这项研究介绍了一种高效的方法,可将基于 Transformer 的大型语言模型(LLM)扩展到无限长的输入,同时限制内存和计算量。该方法的一个关键组成部分是一种新的注意力技术,被称为 Infini-attention。Infini-attention 在 vanilla 注意力机制中加入了压缩内存,并在单个 Transformer 块中建立了掩码局部注意和长期线性注意机制。
作者使用 1B 和 8B LLM,在长上下文语言建模基准、1M 序列长度的 passkey context block 检索和 500K 长度的书籍摘要任务中展示了该方法的有效性。该方法引入了最小的有界内存参数,实现了 LLM 的快速流推理。
方法
图 2 比较了提出的模型、Infini-Transformer 和 Transformer-XL。与 Transformer-XL 类似,Infini-Transformer 也是在一个片段序列上运行。作者在每个片段中计算标准的因果点积注意力上下文。因此,点积注意力计算是局部的,即它覆盖了当前片段中索引为 S 的 N 个 token(N 为片段长度)。然而,局部注意力(Dai 等人,2019 年)在处理下一个片段时会丢弃上一个片段的注意力状态。
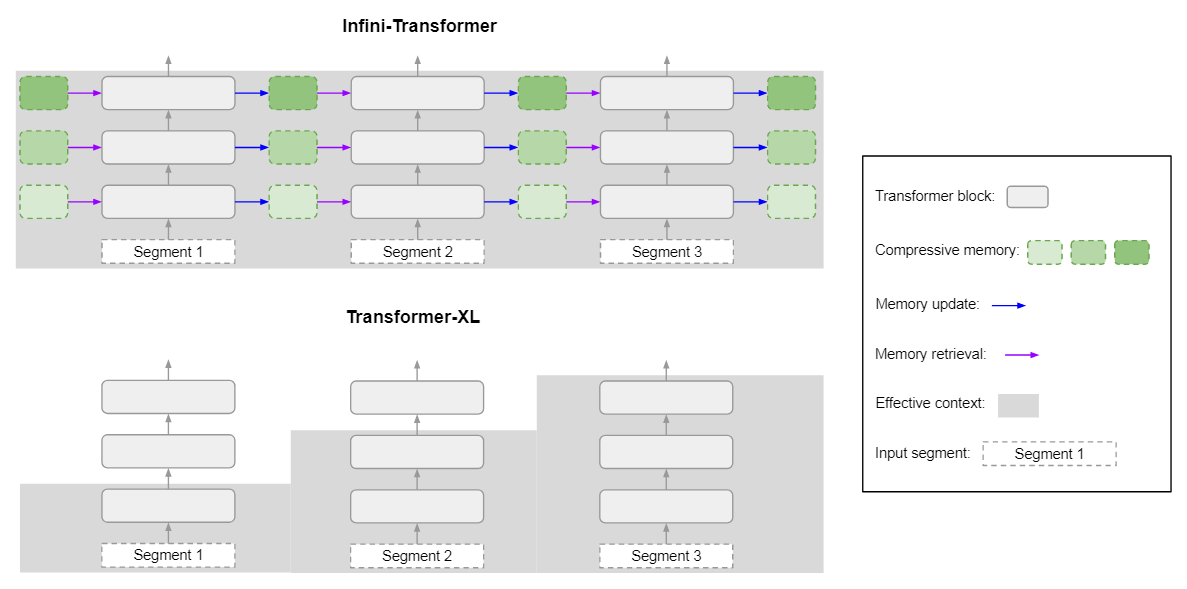
图 2:Infini-Transformer(上图)拥有完整的上下文历史记录,而 Transformer-XL(下图)则会丢弃旧的上下文,因为它只缓存最后一个片段的 KV 状态。
在 Infini-Transformers中,作者并没有丢弃旧的KV注意力状态,而是建议重新使用它们,用压缩记忆来保持整个上下文历史。因此,Infini-Transformers 的每个注意力层都具有全局压缩状态和局部细粒度状态。作者将这种高效的注意力机制称为 Infini-attention,图 1 是其示意图,下文将对其进行正式描述。
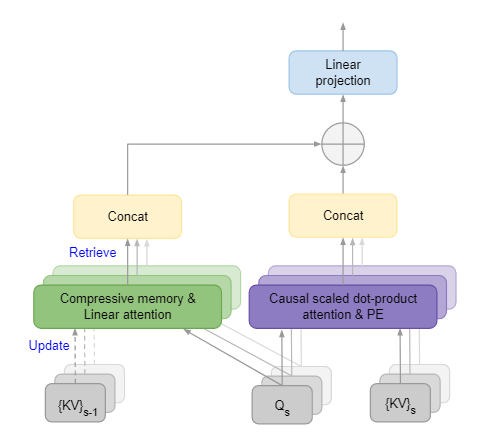
图 1:无限注意力有一个额外的线性注意压缩存储器,用于处理无限长的上下文。${KV}_{s-1}$ 和 ${KV}_s$ 分别是之前和当前输入片段的注意力键值,Q 是注意力查询。PE 表示位置嵌入。
Infini-attention
如图 1 所示,Infini-attention(无限注意力)计算本地和全局上下文状态,并将它们结合起来进行输出。与多头注意力(MHA)类似,除了点积注意力外,它还为每个注意力层保留 H 个并行压缩存储器(H 为注意力头数)。
Scaled Dot-product Attention
multi-head scaled 点积注意力,特别是其自我注意力变体,一直是 LLM 的主要构建模块。在自回归生成模型中,MHA 的强大建模能力和时间掩蔽的便利性得到了广泛使用。
Vanilla MHA 中的单个头根据输入片段序列 $X \in \R^{N \times d_{value}}$ 计算其注意力上下文 $A_{dot} \in \R^{N \times d_{value}}$。首先,计算注意力查询、键和值的状态:
$$
K = XW_K, \quad V = XW_v \quad and \quad Q = XW_Q. \tag{1}
$$
在这,$W_K \in \R^{d_{model} \times d_{key}}, W_V \in \R^{d_{model} \times d_{value}}, and \ W_Q \in \R^{d_{model} \times d_{key}}$ 是可训练的投影矩阵。然后,将注意力上下文计算为所有其他值的加权平均值,即:
$$
A_{dot} = softmax(\frac{QK^T}{\sqrt{d_{model}}})V. \tag{2}
$$
就 MHA 而言,为每个序列元素并行计算 H 个注意力上下文向量,然后将它们沿第二维度串联起来,最后将串联向量投射到模型空间,从而获得注意力输出。
压缩记忆
在 Infini-attention 中,不再为压缩内存计算新的内存条目,而是重复使用点积注意力计算中的查询、键和值状态(Q、K 和 V)。点积注意力和压缩内存之间的状态共享和重用不仅能实现高效的即插即用式长上下文适应,还能加快训练和推理速度。与之前的工作(Munkhdalai 等人,2019 年)类似,目标是在压缩存储器中存储键和值状态的绑定,并通过查询向量进行检索。
虽然文献中提出了不同形式的压缩记忆,但为了简化和提高计算效率,在本研究中,用关联矩阵对记忆进行参数化。通过这种方法,还可以将记忆更新和检索过程视为线性注意力机制,并利用相关方法中的稳定训练技术。特别值得一提的是,作者采用了 Katharopoulos 等人(2020 年)的更新规则和检索机制,这主要是由于其简单性和具有竞争力的性能。
记忆检索:在 Infini-attention 中,通过查询 $Q \in \R^{N \times d_{key}}$ 从存储器 $M_{s-1} \in \R^{d_{key} \times d_{value}}$ 中检索出新的内容 $A_{mem} \in \R^{N \times d_{value}}$:
$$
A_{mem} = \frac{\sigma(Q)M_{s-1}}{\sigma(Q)Z_{s-1}}. \tag{3}
$$
这里,$\sigma$ 和 $Z_{s-1} \in \R^{d_{key}}$ 分别是一个非线性激活函数和一个归一化项。由于非线性和规范方法的选择对训练的稳定性至关重要,因此按照 Katharopoulos 等人的做法,记录所有 keys 的总和作为归一化项 $Z_{s-1}$,并使用 element-wise ELU + 1 作为激活函数。
记忆更新:检索完成后,用新的 KV 实体更新记忆和归一化项,得到下一个状态,即:
$$
M_s \leftarrow M_{s - 1} + \sigma(K)^TV \quad and \quad Z_s \leftarrow Z_{s - 1} + \sum_{t=1}^N \sigma(K_t). \tag{4}
$$
然后,新的记忆状态 $M_s$ 和 $Z_s$ 被传递到下一个片段 S+1,在每个注意力层中新城递归。式(4)中的右侧项 $\sigma(K)^TV$ 被称为关联绑定算子(associative bindling operator)。
受 delta 规则成功的启发,作者也将其纳入了 Infini-attention。delta 规则首先检索现有的 value 实体并将其从新 values 中减去,然后再应用用关联绑定作为新的更新,从而尝试略微改进的记忆更新。
$$
M_s \leftarrow M_{s - 1} + \sigma(K)^T(V - \frac{\sigma(K)M_{s-1}}{\sigma(K)Z_{s-1}}). \tag{5}
$$
如果 KV 绑定已经存在于记忆中,这种更新规则(线性 + delta)将不对关联矩阵进行修改,同时仍会跟踪与前一种更新规则(线性)相同的归一化项,以确保数值稳定性。
长期上下文注入:通过一个学习到的门控标量 $\beta$ 来聚合 local 注意力状态 $A_{dot}$ 和记忆检索内容 $A_{mem}$:
$$
A = sigmoid(\beta) \odot A_{mem} + (1 - sigmoid(\beta)) \odot A_{dot}. \tag{6}
$$
这样,每个头只需增加一个标量值作为训练参数,同时还能在模型中的长期信息流和局部信息流之间进行可学习的权衡。
与标准 MHA 类似,对于多头 Infini-attention,并行计算 H 个上下文状态,并将其串联和投影,得到最终的注意力输出 $O \in \R^{N \times d_{model}}$:
$$
O = [A^1; \ldots A^H]W_O \tag{7}
$$
其中,$W_O \in \R^{H \times d_{value} \times d_{model}}$ 是可训练权重。
内存和有效上下文窗口
Infini-Transformer 可以实现无限制的上下文窗口和有限制的内存占用。为了说明这一点,表 1 列出了以前的 segment-level 内存模型,以及根据模型参数和输入段长度定义的上下文内存占用空间和有效上下文长度。Infini-Transformer 在单层中将压缩上下文存储在 $M_s$ 和每个头的 $Z_s$ 中时,内存复杂度为 $d_{key} \times d_{value} + d_{key}$,而对于其他模型,复杂度随着序列维度的增加而增加——对于 Transformer-XL、Compressive Transformer 和 Memorizing Transformers 来说,内存复杂度取决于缓存大小,而对于 RTM 和 AutoCompressors 来说,内存复杂度取决于软提示大小。
除当前状态外,Transformer-XL 还会对上一片段缓存的 KV 状态计算注意力。Compressive Transformer 为 Transformer-XL 增加了第二个缓存,并存储过去片段激活的压缩表征。因此,它将 Transformer-XL 的上下文窗口扩展了 c × r × l,但上下文内存复杂度仍然很大。
在此基础上,Memorizing Transformers 选择存储整个 KV 状态作为输入序列的上下文。由于在这种情况下存储成本过高,他们将上下文计算限制在单层。通过利用快速 kNN 检索器,Memorizing Transformers 可以建立一个覆盖整个序列历史的上下文窗口(长度为 N × S),但存储成本会增加。实验表明,在 Memorizing Transformers 的基础上,Infini-Transformer LM 可以达到 100 倍以上的压缩率,同时还能进一步提高困惑度得分。
RMT 和 AutoCompressors 允许潜在的无限上下文长度,因为它们会将输入压缩成摘要向量,然后将其作为额外的软提示输入传递给后续片段。但实际上,这些技术的成功与否在很大程度上取决于软提示向量的大小。也就是说,有必要增加软提示(摘要)向量的数量,以提高自动压缩器的性能(Chevalier et al. 在 AutoCompressors 中还观察到(Chevalier 等人,2023 年),训练此类提示压缩技术需要一个高效的压缩目标(Ge 等人,2023 年)。
实验
在涉及超长输入序列的基准测试中对 Infini-Transformer 模型进行了评估:长上下文语言建模、100 万长度的 passkey 上下文块检索和 50 万长度的图书摘要任务。对于语言建模基准,从头开始训练模型,而对于 passkey 和书籍摘要任务,不断预训练现有的 LLM,以突出该方法的即插即用长上下文适应能力。
长上下文语言建模
作者在 PG19(Rae 等人,2019 年)和 Arxiv-math(Wu 等人,2022 年)基准上训练和评估了小型 Infini-Transformer 模型。设置与 Memorizing Transformers(Wu 等人,2022 年)的设置非常相似。也就是说,所有模型都有 12 层、8 个注意头,每个注意头的维度为 128,FFN 的隐藏层为 4096。
作者将所有注意力层的 Infini-attention 段长度 N 设为 2048,将输入序列长度设为 32768,以进行训练。这样,Infini-attention 就能在压缩内存状态下展开 16 个 steps。对于 RMT 基线,在摘要提示长度为 50、100 和 150,序列长度为 4096、8196 和 32768 的情况下进行了多次运行。在 8196 长度的序列上训练时,使用 100 个摘要向量的 RMT 得到了最佳结果。
表 2 总结了语言建模实验的主要结果。Infini-Transformer 性能优于 Transformer-XL 和 Memorizing Transformers 基线,同时与 Memorizing Transformer 模型相比,其第 9 层基于向量检索的 KV 内存长度为 65K,内存参数减少了 114 倍。

表 2:长上下文语言建模结果与平均 token 级别 PPL 的比较。Comp. 表示压缩率。Infini-Transformer 优于内存长度为 65K 的 memorizing transformers,压缩率达到 114 倍。
100K 长度训练:仅有一步将训练序列长度从 32K 增加到 100K,并在 Arxiv-math 数据集上训练模型。100K 训练进一步降低了 Linear 模型和 Linear + Delta 模型的 PPL 分数,分别为 2.21 和 2.20。
门控得分可视化:图 3 展示了各层所有注意力头压缩记忆的门控得分$sigmoid(\beta)$。经过训练后,Infini-attention 中出现了两类注意力头:门控得分接近 0 或 1 的专门注意力头和得分接近 0.5 的混合注意力头。专用头要么通过局部注意力计算处理上下文信息,要么从压缩记忆中检索信息,而混合头则将当前上下文信息和长期记忆内容汇总为单一输出。有趣的是,每一层都至少有一个 short-range 头,允许输入信号向前传播,直到输出层。作者还观察到,在整个前向计算过程中,长短期内容检索交错进行。
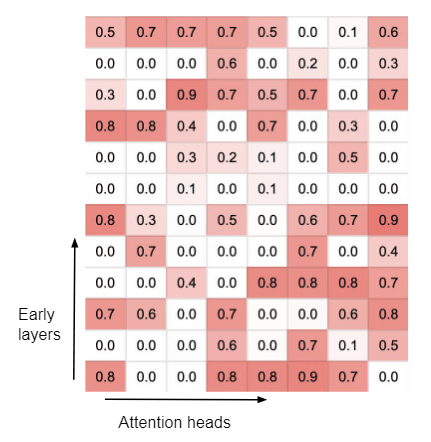
图 3:经过训练后,Infini-attention 中出现了两类头:门控得分接近 0 或 1 的专门头和得分接近 0.5 的混合头。专门头要么通过局部注意机制处理上下文信息,要么从压缩记忆中检索,而混合头则将当前上下文信息和长期记忆内容聚合在一起,形成单一输出。
LLM 持续预训练
作者为现有 LLM 的长上下文适应进行了轻量级持续预训练。预训练数据包括 PG19 和 Arxiv-math 语料库以及长度超过 4K 的 C4 文本(Raffel 等人,2020 年)。在整个实验过程中,语段长度 N 设置为 2K。
1M passkey 检索基准
用 Infini-attention 替换 1B LLM 中的 Vanilla MHA,并继续对长度为 4K 的输入进行预训练。在对 passkey 检索任务进行微调之前,对模型进行了 30K 步的训练,batch size 为 64。
passkey 任务将一个随机数隐藏在长文本中,并在模型输出端进行回问。分心文本的长度可通过多次重复文本块来改变。之前的工作(Chen 等人,2023a)表明,8B LLaMA 模型在使用位置插值对 32K 长度的输入进行微调时,可以解决 32K 长度的任务。作者进一步挑战这一难题,仅对 5K 长度的输入进行微调,以测试 1M 长度的机制。
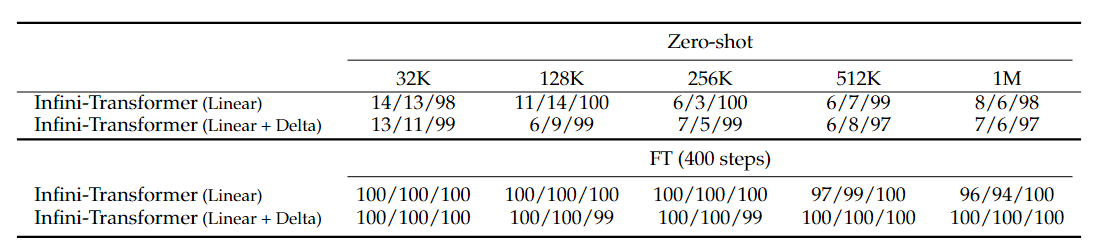
表 3:当对 5K 长度的输入进行微调时,Infini-Transformer 解决了高达 1M 上下文长度的密码任务。报告了隐藏在长度为 32K 到 1M 的长输入的不同部分(开始/中间/结束)中的 token 级检索准确率。
表 3 报告了输入长度从 32K 到 1M 不等的测试子集的 token 级准确率。对于每个测试子集,都控制了 passkey 的位置,使其位于输入序列的开头、中间或结尾。报告了 zero-shot 精度和微调精度。在对 5K 长度的输入进行 400 步微调后,Infini-Transformers 解决了高达 1M 上下文长度的任务。
500K 长度的书籍摘要(BookSum)
进一步扩展该方法,用 8K 输入长度的 8B LLM 模型持续预训练 30K 步。然后,对书籍摘要任务 BookSum 进行了微调,其目标是生成整本书的文本摘要。
将输入长度设置为 32K 以进行微调,并增加到 500K 以进行评估。使用 0.5 的生成温度和 top_p = 0.95,并将解码长度设为 1024,以生成每本书的摘要。
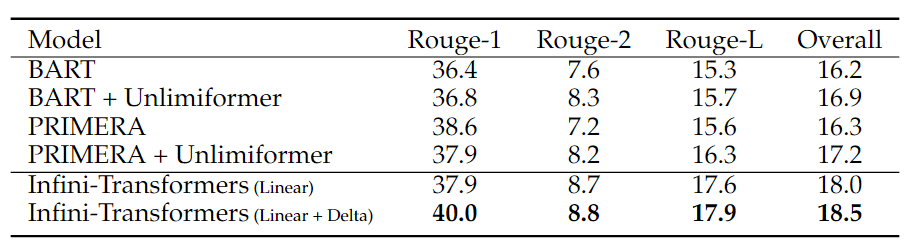
表 4:500K 长书籍摘要(BookSum)结果。BART、PRIMERA 和 Unlimiformer 结果来自 Bertsch 等人(2024 年)。
表 4 将作者的模型与专为摘要任务构建的编码器-解码器模型(Lewis 等人,2019 年;肖等人,2021 年)及其基于检索的长文本扩展(Bertsch 等人,2024 年)进行了比较。作者的模型超越了之前的最佳结果,并通过处理书中的全部文本在 BookSum 上实现了新的 SOTA。

图 4:输入的书籍文本越多,Infini-Transformer 获得的 Rouge 总分越高。
还在图 4 中绘制了对 BookSum 数据的验证拆分的 Rouge 总体得分。有一个明显的趋势表明,随着输入的书籍文本越来越多,Infini-Transformers 的摘要性能指标也在不断提高。
总结
一个有效的记忆系统不仅对理解长上下文中的 LLMs 至关重要,而且对推理、规划、不断适应新知识、甚至学习如何学习都至关重要。该工作将压缩记忆模块与 vanilla 点积注意力层紧密结合。对注意力层进行的这一微妙而又关键的修改,使 LLMs 能够在内存和计算资源受限的情况下处理无限长的上下文。
研究表明,该方法可以自然地扩展到百万长度的输入序列,同时在长上下文语言建模基准和书籍摘要任务中表现优于基线方法。作者还证明了该方法具有良好的长度泛化能力。在最多 5K 序列长度的 passkey 实例上进行微调的 1B 模型解决了 100 万长度的问题。