论文阅读:Lost in the Middle: How Language Models Use Long Contexts
论文地址:https://arxiv.org/abs/2307.03172
虽然最近的语言模型能够将较长的上下文作为输入,但人们对它们使用较长上下文的效果却知之甚少。作者分析了语言模型在两项任务中的表现,这两项任务都需要识别输入上下文中的相关信息:多文档问题解答和 key-value 检索。作者发现,当改变相关信息的位置时,性能会明显下降,这表明当前的语言模型不能稳健地利用长输入上下文中的信息。特别是,作者观察到,当相关信息出现在输入上下文的开头或结尾时,性能往往最高,而当模型必须在长上下文中间获取相关信息时,性能会明显下降,即使是明确的长上下文模型也是如此。作者的分析使人们更好地了解语言模型如何使用输入上下文,并为未来的长上下文语言模型提供了新的评估协议。
实验研究
多文档 QA 实验
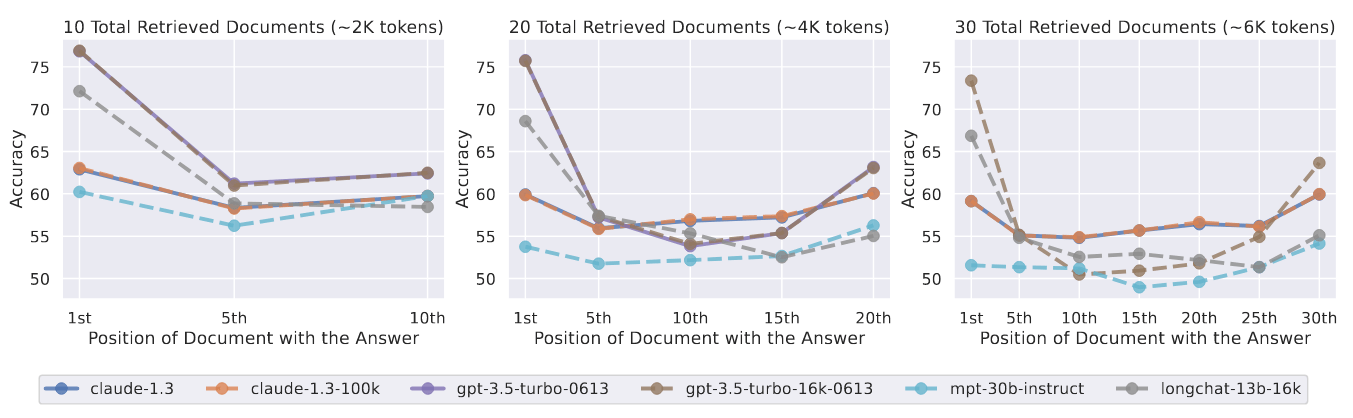
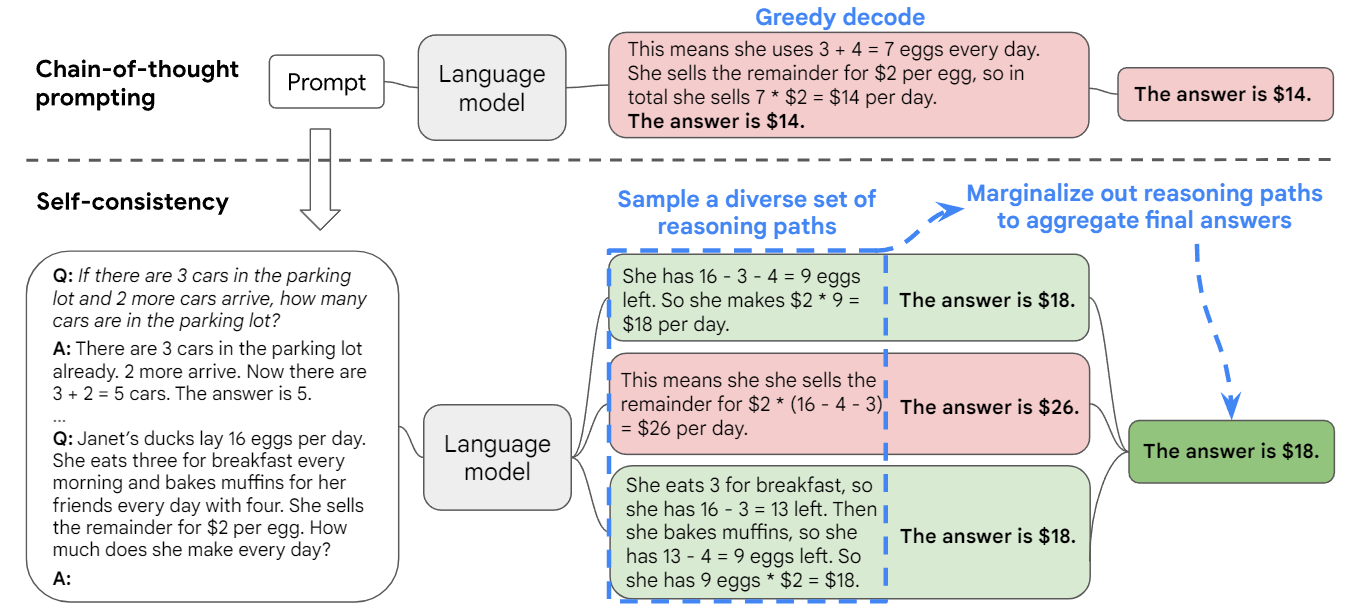
图 5:改变相关信息(包含答案的文档)的位置对多文档 QA 性能的影响。较低的位置更接近输入上下文的起点。当相关信息出现在上下文的最开始或末尾时,性能最高;而当模型必须对输入上下文中间的信息进行推理时,性能会迅速下降。
作者对包含 10、20 和 30 个文档的输入上下文进行了实验。图 5 显示了在输入上下文中改变相关信息位置时的多文档 QA 性能。为了说明模型性能的具体情况,作者还对闭卷和 oracle 设置进行了评估(表 1)。
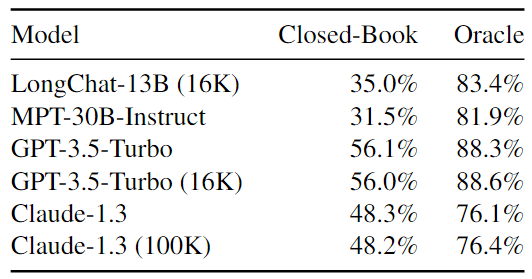
表 1:语言模型在多文档 QA 任务中的闭卷准确率和 oracle 准确率。
- 在“闭卷”设置中,模型的输入上下文中没有任何文档,必须依靠参数记忆来生成正确答案。
- 在 oracle 设置中,语言模型得到的是包含答案的单个文档,必须用它来回答问题。
当相关信息出现在输入上下文的开头或结尾时,模型性能最高
如图 5 所示,改变相关信息在输入上下文中的位置会导致模型性能大幅下降。特别是,看到了一条独特的 U 型性能曲线——模型通常更善于使用出现在上下文开头(首要偏差)和结尾(回顾偏差)的相关信息,而当被迫使用输入上下文中间的信息时,性能就会下降。例如,GPT-3.5-Turbo 的多文档 QA 性能会下降 20% 以上——在最糟糕的情况下,20 和 30 文档设置下的性能会低于无任何输入文档的性能(即闭卷性能;56.1%)。这些结果表明,在提示下游任务时,当前的模型无法有效地对整个上下文窗口进行推理。
扩展上下文模型并不一定更善于使用输入上下文
当输入上下文符合模型及其扩展上下文对应模型的上下文窗口时,发现它们之间的性能几乎相同。例如,10 篇和 20 篇文档的设置都符合 GPT-3.5-Turbo 和 GPT-3.5-Turbo (16K) 的上下文窗口,观察到它们的性能与相对信息位置的函数几乎是叠加的(图 5 中紫色实线和棕色虚线序列)。这些结果表明,在使用输入上下文方面,扩展上下文模型并不一定比非扩展上下文模型更好。
语言模型从输入上下文中获取信息的能力有多强?
鉴于语言模型在多文档问题解答任务中很难检索和使用输入上下文中间的信息,那么它们能在多大程度上简单地检索输入上下文呢?作者通过一个合成 key-value 检索任务来研究这个问题,该任务旨在为从输入上下文中检索匹配 token 的基本能力提供一个最基本的测试平台。
作者使用包含 75、140 和 300 个键值对(各 500 个示例)的输入上下文进行实验。作者使用了与多文档 QA 实验相同的模型集。
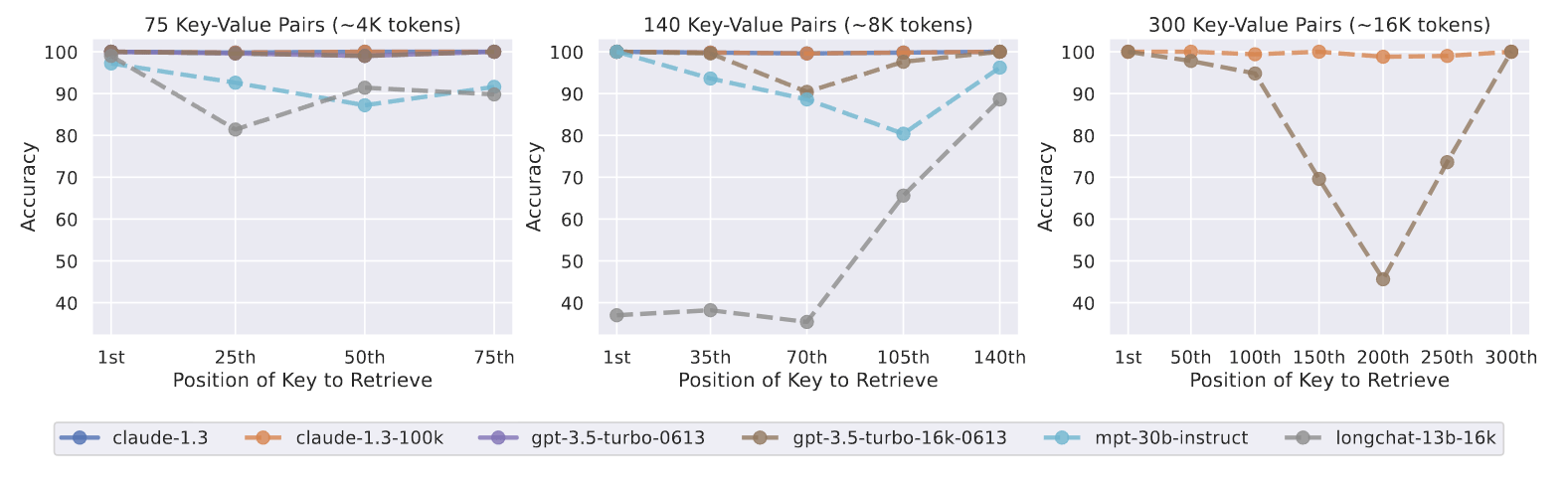
图 7:改变输入上下文长度和相关信息位置对键值检索性能的影响。较低的位置更接近输入上下文的起始位置。虽然有些模型在这项合成任务中表现出了完美的准确性(例如 Claude-1.3 和 Claude-1.3 (100K)),但我们再次看到,当相关信息出现在上下文的最开始或末尾时,性能往往最高,而当模型必须从输入上下文的中间进行检索时,性能就会迅速下降。
图 7 显示了 key-value 检索性能。
- Claude-1.3 和 Claude-1.3 (100K) 在所有评估的输入上下文长度上都表现得近乎完美,但其他模型却很吃力,尤其是当上下文有 140 或 300 个键值对时——虽然合成 key-value 检索任务只要求识别输入上下文内的精确匹配,但并非所有模型都能实现高性能。
- 与多文档问题解答任务结果类似,当 GPT-3.5-Turbo、GPT-3.5-Turbo(16K)和 MPT-30B-Instruct 必须在输入上下文中间访问键值对时,它们的性能最低。
- LongChat-13B(16K)在 140 个键值设置中表现出不同的趋势:定性地观察到,当相关信息放在输入上下文的开头时,LongChat-13B(16K)倾向于生成代码来检索 key,而不是直接输出 value。
语言模型如何无法适应相关信息位置的变化?
多文档问题解答和键值检索结果表明,语言模型很难稳健地访问和使用长输入上下文中的信息,因为当改变相关信息的位置时,性能会显著下降。为了更好地了解原因,对模型架构(纯解码器与编码器解码器)、查询感知上下文化和指令微调的作用进行了初步研究。
模型架构的影响
评估的开放模型都是纯解码器模型——在每个时间步,它们只能关注先前的 token。为了更好地理解模型结构对语言模型如何使用上下文的潜在影响,比较了纯解码器语言模型和编码器-解码器语言模型。
作者使用 Flan-T5-XXL 和 Flan-UL2 进行实验。Flan-T5-XXL 使用 512 个 token 序列(编码器和解码器)进行训练。Flan-UL2 最初使用 512 个 token 序列(编码器和解码器)进行训练,然后使用 1024 个 token 的序列(编码器和解码器)进行额外的 10 万步预训练,然后再对编码器中的 2048 个 token 和解码器中的 512 个 token 的序列进行指令微调。然而,由于这些模型使用的是相对位置嵌入,因此它们(原则上)可以超出这些最大上下文长度;Shaham 等人(2023 年)发现,这两种模型在处理多达 8K 个 token 序列时都能表现出色。

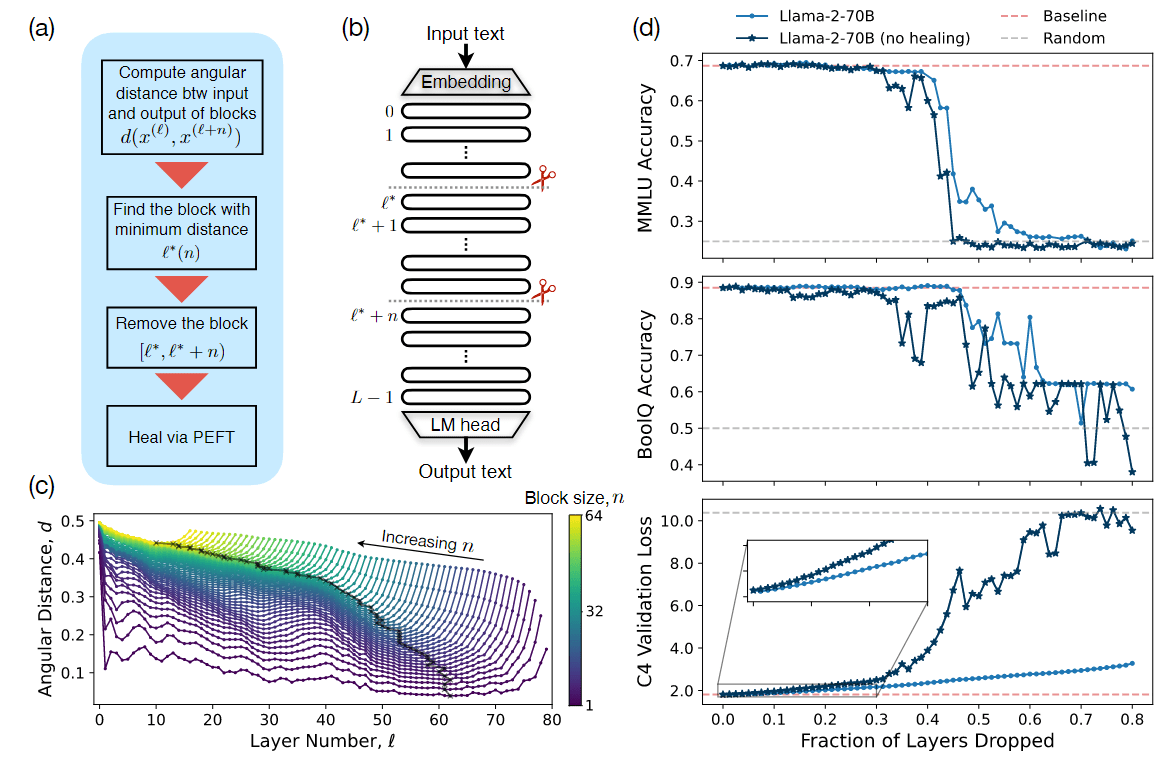
图 8:当编码器-解码器模型(Flan-UL2 和 Flan-T5-XXL)在短于其编码器训练时最大序列长度(分别为 2048 和 512 个标记)的序列上进行评估时,它们对输入上下文中相关信息位置的变化具有相对的鲁棒性(左副图)。与此相反,当这些模型在比训练时更长的序列上进行评估时(中间和右侧子图),观察到一条 U 型性能曲线——当相关信息出现在输入上下文的开头或结尾时,性能要高于输入上下文的中间位置。
图 8 比较了解码器模型和编码器-解码器模型的性能。当对 Flan-UL2 在其 2048 token 训练时间上下文窗口内的序列进行评估时(图 8;左侧副图),其性能对输入上下文中相关信息位置的变化具有相对的鲁棒性(最佳和最差性能之间的绝对差异为 1.9%)。在对长度超过 2048 个 token 的序列进行评估时(图 8;中间和右边),当相关信息被放在中间时,Flan-UL2 的性能开始下降。Flan-T5-XXL 也呈现出类似的趋势,当相关信息位于输入上下文中间时,较长的输入上下文会导致性能下降更多。作者假设,编码器-解码器模型可以更好地利用其上下文窗口,因为其双向编码器允许在未来文档的上下文中处理每个文档,从而有可能改进文档之间的相对重要性估计。
查询感知上下文的影响
多文档 QA 和键值检索实验将查询(即要回答的问题或要检索的键)放在要处理的数据(即文档或键值对)之后。因此,在对文档或键值对进行上下文分析时,纯解码器模型无法关注查询 token,因为查询只出现在 prompt 的末尾,而纯解码器模型只能在每个时间步关注先前的 token。相比之下,编码器-解码器模型(似乎对相关信息位置的变化更稳健;第 4.1 节)使用双向编码器对输入上下文进行上下文化——能否利用这一观察结果,通过将查询置于数据之前和之后来改进纯解码器模型,从而实现对文档(或键值对)的查询感知上下文化?
作者发现,查询感知上下文化显著提高了键值检索任务的性能——在 75、140 和 300 个键值对设置下,所有模型都达到了接近完美的性能。例如,采用查询感知上下文化的 GPT-3.5-Turbo (16K) 在使用 300 个键值对进行评估时取得了完美的性能。
相比之下,如果不进行查询感知上下文化,最差性能为 45.6%(图 7)。尽管查询感知上下文化对键值检索性能有重大影响,但它对多文档问题解答任务的性能趋势影响甚微(图 9);当相关信息位于输入上下文的最开头时,查询感知上下文化会略微提高性能,但在其他情况下,查询感知上下文化会略微降低性能。
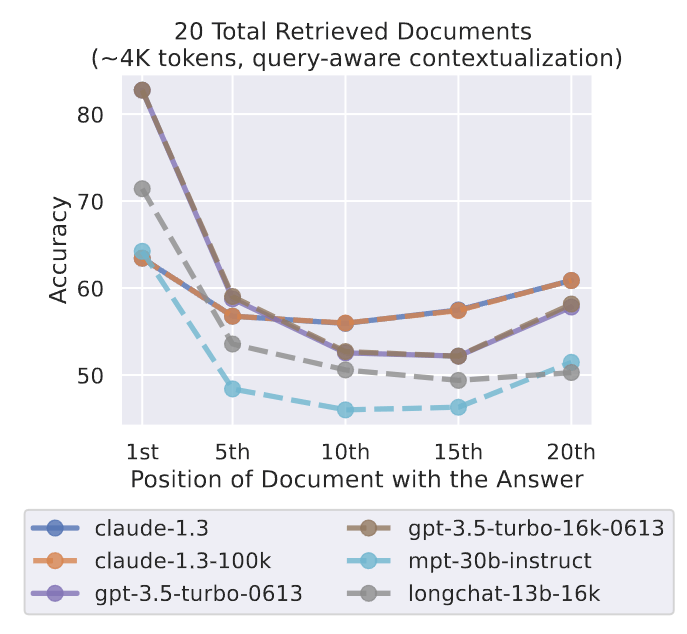
图 9:在多文档问题解答任务中,查询感知上下文化(将查询放在文档之前和之后)并不能大幅提高语言模型对相关信息位置变化的稳健性;当相关信息出现在文档开头时,性能会略有提高,但在其他情况下,性能会略有下降。
指令微调的影响
评估的模型都是经过指令微调的——在最初的预训练之后,它们会在指令和响应的数据集上进行有监督的微调。在有监督的指令微调数据中,任务说明和/或指令通常位于输入上下文的开头,这可能会导致经过指令微调的语言模型更加重视输入上下文的开头。为了更好地理解指令微调对语言模型如何使用长输入上下文的潜在影响,作者将 MPT-30B-Instruct 的多文档 QA 性能与其基础模型(即指令微调前)MPT-30B 进行了比较。使用与第 2 节相同的实验设置。
图 10 比较了 MPT-30B 和 MPT-30B-Instruct 的多文档 QA 性能与输入上下文中相关信息位置的函数关系。令人惊讶的是:
- MPT-30B 和 MPT-30B-Instruct 都呈现出 U 型性能曲线,当相关信息出现在上下文的最开头或最结尾时,性能最高。虽然 MPT-30B-Instruct 的绝对性能均高于 MPT-30B,但它们的总体性能趋势相似。
- 指令微调略微缩小了最坏情况下的性能差距,从基础模型最佳和最坏情况下性能差距的近 10%,缩小到 4% 左右。
这些观察结果是对之前工作的补充,之前的工作发现非指令微调语言模型偏向于最近的 token(即输入上下文的末尾)。在过去的工作中,当评估连续文本的下一单词预测模型时,也观察到了这种最近性偏差,在这种情况下,语言模型从远距离信息中获益最小。与此相反,作者的结果表明,当 prompt 使用指令格式数据时,语言模型能够使用较长范围的信息(即输入上下文的开头)。作者假设,非指令微调语言模型可以从预训练期间看到的互联网文本(例如 StackOverflow 问答)中可能出现的类似格式数据中学习使用长上下文。
为了更好地了解额外微调和模型规模的影响,作者还对不同规模(7B、13B 和 70B)的 Llama-2 模型进行了实验,其中包括额外的监督微调和来自人类反馈的强化学习(附录 E)。发现 U 型性能曲线只出现在足够大的语言模型中(无论是否进行了额外的微调)——7B Llama-2 模型只偏重于回顾,而 13B 和 70B 模型则表现出 U 型性能曲线。此外,还看到 Llama-2 监督微调和从人类反馈中强化学习的程序稍微减轻了较小模型的位置偏差(13B,类似于比较 MPT-30B 和 MPT-30B-Instruct 时显示的趋势),但对较大模型的趋势影响很小(70B)。
上下文越多越好吗?开放域 QA 案例研究
研究结果表明,用较长的输入上下文提示语言模型是一种权衡——为语言模型提供更多信息可能有助于它完成下游任务,但同时也增加了模型必须推理的内容,可能会降低准确性。即使语言模型可以接收 16K token,提供 16K token 的上下文是否真的有益?这个问题的答案最终取决于下游任务的具体情况,因为它取决于所添加上下文的边际价值以及模型有效使用长输入上下文的能力,但作者在 NaturalQuestionOpen 上进行了一项开放域问题解答的案例研究,以更好地了解现有语言模型中的这种权衡。
在标准的检索阅读器设置中使用语言模型。检索系统(Contriever,在 MS-MARCO 上进行了微调)接受来自 NaturalQuestions-Open 的输入查询,并从维基百科中返回相关性得分最高的 k 篇文档。要在这些检索到的文档上建立语言模型,只需在 prompt 中加入这些文档即可。作者将检索器的召回率和阅读器的准确率(是否有标注答案出现在预测输出中)作为检索文档数量 k 的函数进行评估。使用的是 NaturalQuestion-Open 的一个子集,其中的长答案是一个段落(而不是表格或列表)。
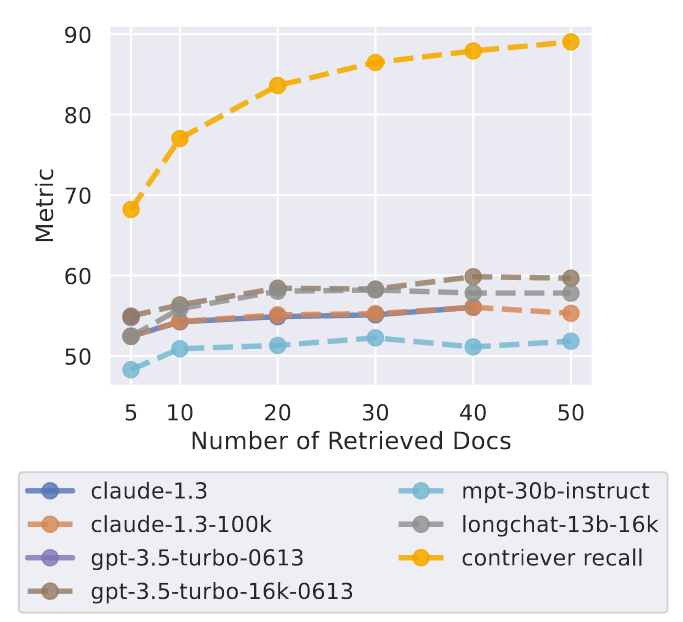
图 11:检索器召回率和模型性能与检索文档数量的函数关系。模型性能早在检索器召回率之前就达到了饱和,这表明模型很难利用额外的检索文档。
图 11 显示了检索器的召回率和开放域 QA 结果,可以看到,阅读器模型的性能早在检索器性能饱和之前就已经饱和,这表明阅读者并没有有效利用额外的上下文。使用超过 20 个检索文档只能略微提高阅读器的性能(GPT-3.5-Turbo 为 1.5%,Claude-1.3 为 1%),而输入上下文的长度(以及延迟和成本)却显著增加。这些结果,再加上模型通常更善于检索和使用输入上下文开头或结尾处的信息这一观察结果,表明对检索到的文档进行有效的重新排序(将相关信息推近输入上下文的开头)或对排序列表进行截断(在适当的时候检索较少的文档;Arampatzis 等人,2009 年),可能是改进基于语言模型的阅读器如何使用检索到的上下文的有希望的方向。
总结
作者通过一系列对照实验对语言模型如何使用长输入上下文进行了实证研究,发现当改变相关信息的位置时,语言模型的性能会明显下降,这表明模型在长输入上下文中很难稳健地获取和使用信息。特别是,当模型必须使用长输入上下文中间的信息时,性能往往最低。作者对(i)模型架构、(ii)查询感知上下文化和(iii)指令微调的作用进行了初步调查,以更好地了解它们如何影响语言模型如何使用上下文。
最后,以一个开放领域问题解答的实际案例研究作为总结,发现语言模型阅读器的性能远远早于检索器的召回能力达到饱和。研究结果和分析让我们更好地理解了语言模型是如何使用其输入上下文的,并为未来的长上下文模型提供了新的评估协议。