论文阅读:Revealing the Dark Secrets of BERT
速读
Q1 论文试图解决什么问题?
基于 BERT 的架构在许多 NLP 任务上表现出最先进的性能,作者想探知促使其成功的底层机制。在本篇论文中,作者主要针对 self-attention 做了一系列的研究。
- 常见的注意力模式是什么,它们在微调过程中是如何变化的,以及这对特定任务的表现有何影响?
- 哪些语言知识被编码在经过微调的 self-attention 权重中,哪些部分来自预训练?
- 不同注意力头的 self-attention 模式有多大不同,它们对特定任务的重要性如何?
Q2 这是否是一个新的问题?
不是一个新的问题。
Q3 论文中提到的解决方案之关键是什么?
为每一层的每一个注意力头提取 self-attention 权重,这生成了一个形状为 L x L 的二维浮点数组,其中 L 是输入序列的长度。作者将这种二维数组称为 self-attention map。通过观察 self-attention map 来研究 self-attention 机制。
Q4 这篇论文到底有什么贡献?
- 提出了一套分析 BERT self-attention 的方法,并首次详细分析了 BERT 通过在 self-attention 权重中编码(比较 BERT 的预训练和微调版本的注意力模式)来捕捉不同种类的语言信息的能力。
- 总结了五种常见的注意力模式,比较微调和预训练前后 self-attention map 的余弦相似度,发现最后两层编码了用于提升最终分数的特定任务特征,而早期各层则捕获了用于微调模型的更基本和低层次信息。预训练的 BERT 确实含有语言知识,对解决这些 GLUE 任务有帮助。
- 某些类型的语言关系可能被专门的注意力头中的 self-attention 捕获。vertical 注意力图一般来自于 BERT 的预训练任务,而不是来自于特定任务的语言推理。
- 不同的注意力头所编码的信息存在冗余,无论目标任务如何,相同的模式都会不断地重复,表明整体模型过度参数化。
- 手动禁用某些注意力头的 attention 会提高 BERT 模型的性能。
Q5 下一步呢?有什么工作可以继续深入?
作者对输出层中的 [CLS] token 的注意力分布进行调查,其结果表明,对于大多数任务,除了 STS-B、RTE 和 QNLI 外,[SEP] token 得到的 attention 最多。
那么是否可以拿 [SEP] 来分类呢?
摘要
基于 BERT 的架构目前在许多 NLP 任务上表现出最先进的性能,但人们对促成其成功的确切机制知之甚少。在目前的工作中,作者专注于对 self-attention 的解释,这是 BERT 的一个基本组成部分。利用 GLUE 任务的一个子集和一组手工制作的特征,作者对 BERT 个别注意力头编码的信息进行了定性和定量的分析。
作者的研究结果表明,有一组有限的注意力模式在不同的注意力头中重复出现,表明整体模型的过度参数化。虽然不同的注意力头始终使用相同的注意力模式,但它们对不同任务的性能有不同的影响。实验表明,手动禁用某些注意力头的 attention 会提高 BERT 模型的性能。
介绍
促成 BERT 杰出表现的确切机制仍不清楚,作者通过选择一组感兴趣的语言特征,并进行一系列的实验来解决这个问题。这些实验旨在提供关于 BERT 对这些特征的信息捕捉能力。
本篇论文的主要贡献如下所示:
- 提出了一种方法,并首次详细分析了 BERT 通过在 self-attention 权重中编码来捕捉不同种类的语言信息的能力。
- 提出了 BERT 过度参数化的证据,并提出了一种反直觉的简单方法来提高性能。
方法
作者提出了以下研究问题:
- 常见的注意力模式是什么,它们在微调过程中是如何变化的,以及这对特定任务的表现有何影响?($3.1,$3.3)
- 哪些语言知识被编码在经过微调的 self-attention 权重中,哪些部分来自预训练?($3.2,$3.4,$3.5)
- 不同注意力头的 self-attention 模式有多大不同,它们对特定任务的重要性如何?($3.6)
这些问题的答案来自于用基本的预训练模型或微调的 BERT 模型进行的一系列实验,这一点将在下面讨论。
所有关于预训练的 BERT 实验都是使用 PyTorch 实现,模型选用 Bert-base-uncased,12 层 Transformer Block,768 隐藏层大小,12 个注意力头,共计 110M 参数。作者选择这个较小的 BERT 版本,是因为它性能良好,且具有较少的层和注意力头,更容易解释。
作者使用部分 GLUE 任务来作为微调任务:MRPC、STS-B、SST-2、QQP、RTE、QNLI 和 MNLI。
所有的微调实验都遵循原始 BERT 中的参数,batch_size = 32、epochs = 3。
在所有的这些实验中,对于一个给定的输入,作者为每一层的每一个注意力头提取 self-attention 权重。这生成了一个形状为 L x L 的二维浮点数组,其中 L 是输入序列的长度。作者将这种二维数组称为 self-attention map。对独立的 self-attention map 的分析使我们能后确定在对输入的 token 逐个进行处理时,哪些 token 获得的注意力最多。作者利用这些实验来分析 BERT 是如何处理不同种类语言信息,包括不同的词性(名词、代词和动词)、句法角色(宾语、主语)、语义关系和否定 token。
实验
在本届中,将介绍为解决上述研究问题而进行的实验。
BERT self-attention 模式
人工检查 vanilla 预训练和微调的 BERT 模型的 self-attention 图,发现有一组有限的 self-attention 图,在不同的注意力头中重复编码。与先前的观察一致,作者确定了五种经常出现的模式,其示例见图 1。

- Vertical:主要对应于关注 BERT 的特殊 token [CLS] 和 [SEP],作为 BERT 输入的分隔符。
- Diagonal:由前一个/后一个 token 的 attention 形成。
- Vertical + Diagonal:Vertical 和 Diagonal 的混合。
- Block:对于有两个不同句子任务(例如 RTE 或 MRPC)的句子内注意力。
- Heterogeneous:取决于具体的输入,变化很大,不能用一个独特的结构来描述。
请注意,由于“Heterogeneous”类别包含了其他四个类别中没有的模式,构建的类别列表是详尽的。
对特殊 token 的关注对跨句子推理很重要,对前/后 token 的关注来自于语言模型的预训练,作者假设所列举的最后一种类型更有可能捕捉到可解释的语言特征,这是语言理解所必需的。
为了粗略估计可能捕捉到语言上可解释信息的注意力头的百分比,作者手动标注了大约 400 个self-attention 图的样本,使其属于五种类别之一。self-attention 图是通过将选定任务的随机输入实例输入相应的微调 BERT 模型而获得的。这产生了一个有点不平衡的数据集,其中 Vertical 类占了所有样本的 30%。
然后,作者训练了一个具有 8 个卷积层和 ReLU 激活函数的卷积神经网络,将输入数据分类到这些类别中。这个模型在有标注的数据集上达到了 0.86 的 F1-score。作者用这个分类器来估计 GLUE 任务的不同 self-attention 模式的比例,每个验证集最多有 1000 条数据(如果有的话)。

结果:图 2 显示,上述的 self-attention 图类型在不同的注意力头和任务中不断重复。虽然很大一部分编码信息对应于对前一个/后一个 token、特殊 token 或两者混合的注意力,但对“Heterogeneous”类别中所有注意力头的估计上限(即可能有信息的注意力头)根据任务的不同,从 32%(MRPC)到 61%(QQP)不等。作者想强调的是,这只是给出了注意力头的百分比上限,这些注意力头有可能捕捉邻接和分隔符以外的有意义的结构信息。
BERT 中的特定关系注意力头
在这个实验中,作者的目标是了解不同的句法和语义关系是否被 self-attention 模式所捕获。虽然可以研究大量的这种关系,但作者选择研究框架语义学中定义的语义角色关系,因为它们可以被视为处于句法和语义的交叉点。具体来说,作者关注的是 BERT 能否捕捉到 FrameNet 框架引起(frame-evoking)词汇单元(谓语)和核心框架元素之间的关系,以及它们之间的联系是否在某些特定的注意力头部产生较高的注意力权重。作者在这些实验中使用了预先训练好的 BERT。
本实验的数据来自于 FrameNet,这是一个包含了不同词汇单元的
作者为数据库中的每个词法单元提取了样本句子,并确定了相应的核心框架元素。FrameNet 中的注释元素可能相当长,所以只考虑框架元素为 3 或以下的句子。由于每个句子只对一个框架进行注释,因此在未标记的元素之间可能存在来自其他框架的语义链接。因此,作者过滤掉所有超过 12 个 token 的句子,因为较短的句子不太可能引起多个框架。
为了确定 BERT 的注意力是否能捕捉到不只是对应于前一个/后一个 token 的语义关系,作者排除了链接对象相距不到 2 个 token 的句子。这样,就有了 473 个注释的句子。
对于这些句子中的每一个,作者都获得了预训练 BERT 对 144 个注意力头中每一个头的注意力权重。对于每个注意力头,返回那些对应于特定句子中包含的注释语义链接的 token pair 中最大的绝对注意力权重。然后,对所有收集到的数据的得分进行平均。这种策略能够确定优先考虑与一个句子中的框架-语义关系相关特征的注意力头。
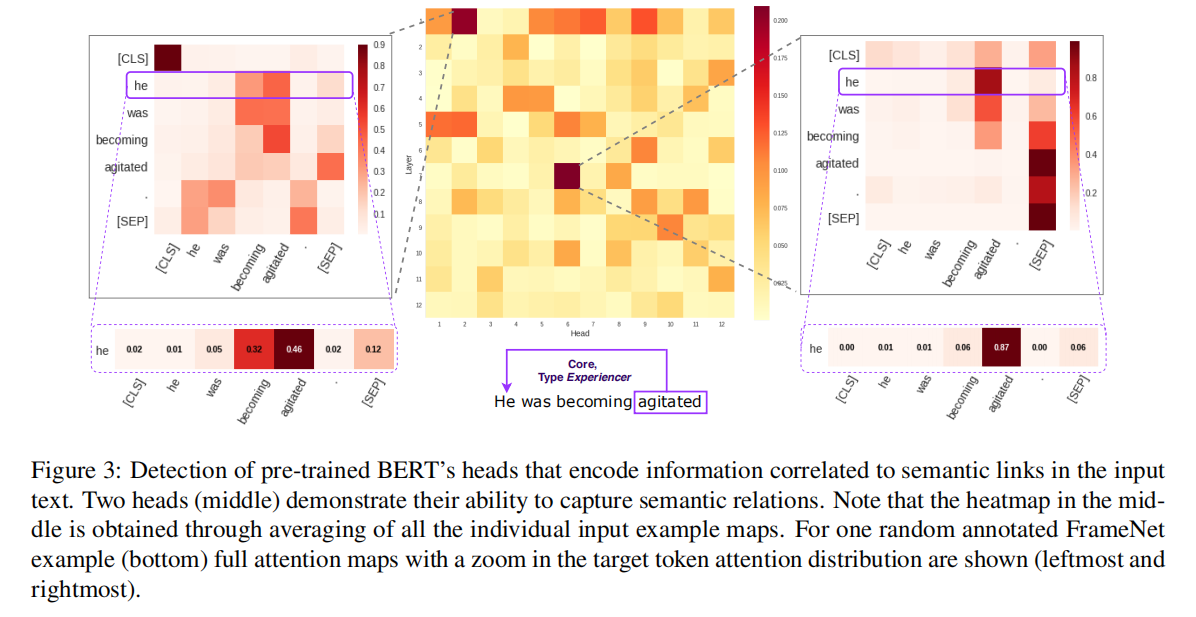
结果:所有收集到的数据的平均注意力分数热图(图 3)表明,144 个注意力头中有 2 个倾向于关注 FrameNet 标注者认定为同一框架的核心元素的句子部分。这些被识别的注意力头在所有数据中的最大注意力权重平均占 0.201 和 0.209,大于所有注意力头的数值分布的第 99 个百分点。图 3 显示了这两个注意力头关于这种注意力模式的例子。在处理“He was becoming agitated”这个句子中的“agitated”时,两个注意力头都对“He”表现出很高的注意力权重(“Emotion directed”框架)。作者将这些结果解释为有限的证据——即某些类型的语言关系可能被专门的注意力头中的 self-attention 捕获。更大范围的关系还有待研究。
self-attention 在微调后的变化
微调对模型的性能有巨大的影响,本节试图找出原因。
为了研究 GLUE 任务中每个注意力头的注意力平均变化情况,作者计算了预训练和经过微调后 BERT 的注意力权重扁平化数组(flattened arrays)之间的余弦相似度。作者在所有 dev 数据集中计算平均相似度。为了评估预训练 BERT 对任务整体性能的贡献,作者考虑了两种权重初始化的配置,即预训练的 BERT 权重和从正常分布中随机抽取的权重。

(Figure 5:对于每个 GLUE 任务,预训练的 BERT 和微调的 BERT 的 self-attention 图之间的每个注意力头余弦相似度,在 dev 数据集中的平均值。颜色越深,差异越大)
结果:图 5 显示,对于除 QQP 任务之外的其他所有任务,与预训练的 BERT 模型相比,最后两层的变化最大。同时,表 1 显示,微调的 BERT 在所有任务上都比预训练的 BERT 要好很多(平均 35.9 分的绝对差异)。这可以得出结论,最后两层编码了用于提升最终分数的特定任务特征,而早期各层则捕获了用于微调模型的更基本和低层次信息。BERT 的权重从正态分布中初始化,并针对特定任务进一步微调,所产生的分数始终低于预训练 BERT 所产生的分数。事实上,对于某些任务(STS-B 和 QNLI),用随机权重进行初始化产生的性能比没有经过微调的预训练 BERT 更差。这表明,预训练的 BERT 确实含有语言知识,对解决这些 GLUE 任务有帮助。
所以,在微调预训练模型时,可以将最后两层的权重初始化,仅利用前面几层的权重。或者冻结前几层的权重,仅微调最后两层的权重。
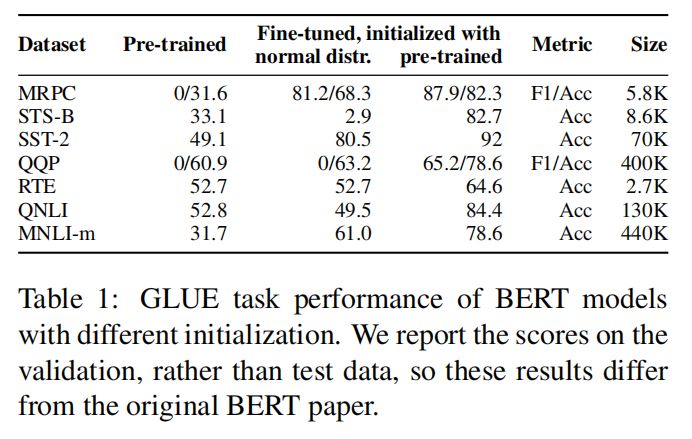
(Table 1:不同初始化的 BERT 模型的 GLUE 任务表现。报告的是验证分数,而不是测试数据,所以这些结果与原 BERT 论文不同)
attention to linguistic features
作者研究为了一个特定任务而对 BERT 进行微调,是否会产生强调特定语言特征的 self-attention 模式。在这种情况下,某些种类的 token 可能从句子中的所有其他 token 中获得较高的注意力权重,在相应的注意力图上产生垂直条纹(见图 1 Vertical)。
为了验证这一假设,作者检查了是否存在与某些语言上可解释的特征相对应的垂直条纹模式,以及这些特征在多大程度上与解决特定任务有关。尤其是对名词、动词、代词、主语、宾语和否定词的 attention,以及整个任务中的特殊 BERT token([CLS] token 和 [SEP] token)。对于每个注意力头,作者计算分配给每个输入 token 感兴趣的 token 的 self-attention 权重之和。由于权重取决于输入序列中的 token 数量,这个总和被序列长度规范化。这使我们能够在不同的数据中汇总该特征的权重。如果有多个相同类型的 token(如几个名词或否定词),我们取最大值。不考虑不包含某一特征的输入句子。
对于每一个被调查的特征,作者为每一层的每个注意力头计算这个汇总的注意力分数,并建立一个映射图,以检查可能对这个特征负责的注意力头。然后,作者将获得的映射图与使用预训练好的 BERT 模型得出的映射图进行比较。这种比较使我们能够确定一个特定的特征对一个具体的任务是否重要,以及它对某些任务的贡献是否比其他任务大。
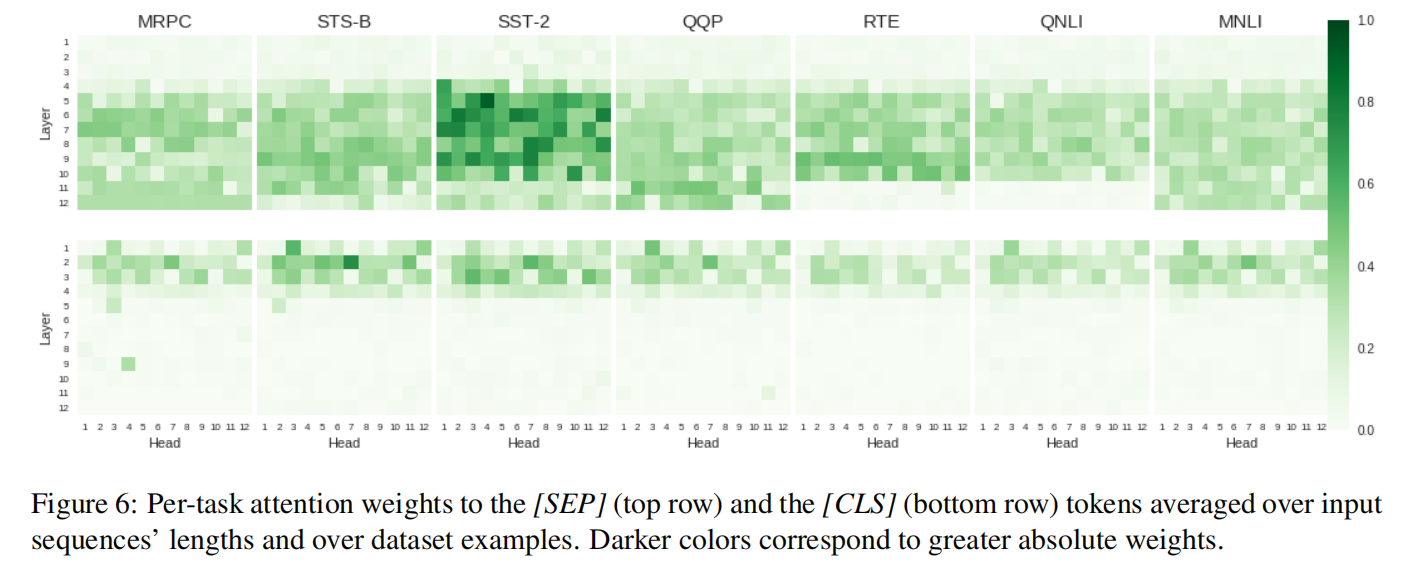
(Figure 6:每个任务对 [SEP] token(上行)和 [CLS] token(下行)的注意力权重,按输入序列的长度和数据集示例进行平均。较深的颜色对应较大的绝对权重)
结果:与作者最初的假设相反,即 vertical 注意模式可能是由语言上有意义的特征引起的。作者发现它主要但不完全与 [CLS] token 和 [SEP] token 的 attention 有关(见图 6)。请注意,SST-2 情感分析任务的 [SEP] token 绝对权重大于其他任务,这是由于模型输入中只有一个句子,即只有一个 [SEP] token 而不是两个。还有一个明显的趋势,早期层注意 [CLS] token,后期层注意 [SEP] token,这个趋势在所有任务中都是一致的。作者确实检测到注意力头对名词和主要谓语的直接宾语(在 MRPC、RTE 和 QQP 任务上)以及否定词 token(在 QNLI 任务上)付出了更多的注意力(与预训练的 BERT 相比),但是与 [CLS] token 和 [SEP] token 相比,这些 token 的注意力权重可以忽略不计。因此,作者认为,vertical 注意力图一般来自于 BERT 的预训练任务,而不是来自于特定任务的语言推理。
所以这也是为什么可以直接拿 [CLS] token 做分类的原因?因为 [CLS] token 汇聚了整个输入句子的大多数注意力,拥有句子丰富的信息。
token-token attention
在本节中,作者研究了同一句子中各 token 之间的注意力模式——在处理某一 token 时,是否有任何 token 特别重要。作者对动词-主语关系和名词-代词关系特别感兴趣。
此外,由于 BERT 在最后一层使用 [CLS] token 来进行预测,作者使用上一节中的实验特征,来检查这些特征是否在模型处理 [cls] token 时获得更高的注意力权重。
结果:
- 作者为检测考虑动词-主语和名词-名词关系的注意力头而进行的 token-token attention 实验,得出了一组潜在的注意力头候选者,它们与 diagonal 结构的注意力图相吻合。作者认为,这是因为英语语法的固有特性——从属元素经常出现在彼此之间,所以很难将这种关系从语言模型预训练所产生的前一个/后一个 token attention 中区分出来。
- 作者对输出层中的 [CLS] token 的注意力分布进行调查,其结果表明,对于大多数任务,除了 STS-B、RTE 和 QNLI 外,[SEP] token 得到的 attention 最多,如图 7 所示。

(Figure 7:与 [CLS] token 相对应的每个任务的注意力权重分布,根据输入序列的长度和数据集的数据进行了平均,并从第五层提取。较深的颜色对应于较大的绝对权重)
禁用 self-attention 头
由于不同的注意力似乎确实有一定程度的专门化,作者调查了在 BERT 中禁用不同注意力头的效果,以及由此对任务性能的影响。由于 BERT 在很大程度上依赖于学习到的注意力权重,作者将禁用一个注意力头定义为将一个注意力头的注意力值修改为输入句子中每一个 token 的常数 $a = \frac{1}{L}$,其中 L 是句子的长度。因此,每个 token 都得到了同样的 attention,有效地禁用了学到的注意力模式,同时保留了原始模型的信息。注意,通过使用这个框架,我们可以禁用任意数量的注意力头,从每个模型的一个或整个注意力层乃至多个注意力层。
结果:实验结果表明,某些注意力头对 BERT 的整体性能有不利影响,这种趋势对所有任务都成立。出乎意料的是,禁用一些注意力头并没有像人们预期的那样导致精度下降,反而提高了模型的性能。这种效果在不同的任务和数据集中是不同的。虽然禁用某些注意力头会改善结果,但禁用另一些注意力头则会损害结果。对于不同的任务,禁用一个注意力头的收益是不同的,从 STS-B 的最小绝对收益 0.1% 到 MRPC 的最大绝对收益 1.2%(见图 8)。

(Figure 8:每次禁用一个注意力头时的模型性能。橙色线表示没有禁用注意力头时的基线性能。较深的颜色对应较大的性能分数)
事实上,对于一些任务,如 MRPC 和 RTE,禁用一个随机的注意力头,平均来说,可以提高模型的性能。此外,禁用一整个注意力层(某一层的所有 12 个注意力头)也能提高模型的性能。
图 9 显示了当不同注意力层被禁用时,GLUE 任务的模型性能。值得注意的是,禁用 RTE 任务中的第 5 层会有明显的提升,达到 3.2% 的绝对收益。然而,这种操作的效果在不同的任务中有所不同,对于 QNLI 和 MNLI,它反而会导致性能下降 0.2%。

(Figure 9:每次禁用一个注意力层时的模型性能。橙色线表示没有禁用该层时的基线性能。较深的颜色对应较大的性能分数)
讨论
总的来说,实验结果表明:即使是较小的 vanilla BERT 模型也是明显的过度参数化。在不同的注意力头中发现了重复的 self-attention 注意力模式,以及禁用单个注意力头和多个注意力头对模型性能无害,在某些情况下甚至可以提高模型性能。这两点都支持了这一观点。
作者没有发现任何证据表明,可映射到核心框架-语义关系上的注意力模式(attention patterns that are mappable onto core frame-semantic relations)实际上提高了 BERT 的性能。在 144 个注意力头中,有 2 个注意力头似乎“负责”这些关系(见第 4.2 节),但在任何 GLUE 任务中似乎都不重要:禁用任何一个注意力头都不会导致准确性的下降。这意味着微调的 BERT 不依赖这块语义信息,而是优先考虑其他特征。
例如,STS-B 和 RTE 的微调模型都依赖于同一对注意力头(第四层的 1 号和第二层的 12 号)的注意力,如图 8 所示。
(Figure 8:每次禁用一个注意力头时的模型性能。橙色线表示没有禁用注意力头时的基线性能。较深的颜色对应较大的性能分数)
作者用一组随机输入的数据手动检查了这些注意力头中的注意力图谱,并确定这两个注意力头对于在输入数据的两个句子中都出现的词有很高的权重。这很可能意味着,对两个句子的逐字比较为 STS-B 和 RTE 的分类预测提供了一个坚实的策略。作者没能找到概念上类似的,对其他任务重要的注意力头部解释。
总结
在这项工作中,作者提出了一套分析 BERT self-attention 机制的方法,比较了 BERT 的预训练和微调版本的注意力模式。
最令人惊讶的发现是:尽管注意力机制是 BERT 的关键基础机制,但该模型可以从注意力的“禁用”中受益。此外,作者证明了不同的注意力头所编码的信息是冗余的,无论目标任务如何,相同的模式都会不断地重复。作者认为,这两个发现展示了解释 BERT 的进一步研究方向——模型修剪和找到一个减少数据重复的最佳子架构。