论文阅读:RoBERTa: A Robustly Optimized BERT Pretraining Approach
本篇论文研究 BERT 预训练过程,仔细测量许多关键超参数和训练数据大小对模型性能的影响,作者发现 vanilla BERT 的训练不够充分,并提出了一个改进的训练 BERT 模型的配方,称之为 RoBERTa。
作者的修改很简单,它们包括:
- 在更多的数据上用更大的 batch_size 对模型进行更长时间的训练。
- 删除 NSP 任务。
- 在更长的序列上进行训练。
- 动态地改变应用于训练数据的 mask 方式。
训练过程分析
本节探讨并量化哪些选择对预训练 BERT 模型有着较高的重要程度。作者保持模型架构的固定。具体来说,首先训练 BERT 模型,其配置有 $BERT_{BASE}$ 相同(L = 12,H = 768,A = 12,110M 参数)。
静态 mask VS 动态 mask
Vanilla BERT 在数据预处理过程中进行了一次 mask,结果是一个单一的静态 mask。为了避免在每个 epoch 中对每个训练数据使用相同的 mask,训练数据被重复了 10 次,因此在 40 个 epoch 中,每个序列被以 10 种不同的方式进行 mask。因此,在训练期间,每个训练序列都被用相同的 mask 看过四次。
作者将上述策略与动态 mask 进行比较,在动态 mask 中,每次向模型输入序列时都会生成 mask 模式。在对更多的步骤或更大的数据集进行预训练时,这一点变得至关重要。

结果:表 1 比较了 vanilla $BERT_{BASE}$ 和作者用静态或动态 mask 重新实现的结果。作者发现,对静态 mask 的重新实现与 vanilla BERT 模型的表现相似,而动态 mask 与静态 mask 相当或稍好。
鉴于这些结果和动态 mask 的额外效率优势,作者在其余实验中均使用动态 mask。
模型输入格式和 NSP
在最初的 BERT 预训练过程中,模型观察到两个串联的文档片段,它们要么是从同一文档中连续取样(p = 0.5),要么是从不同的文档中取样。除了 MLM 目标外,还通过 NSP 来预测观察到的文档片段是来自相同还是不同的文档。Devlin 等人观察到,去除 NSP 会降低模型的性能,在 QNLI、MNLI 和 SQuAD 1.1 上性能明显下降。然而,最近的一些工作对 NSP loss 的必要性提出了质疑。
为了更好地理解这种差异,作者比较了几种可供选择的训练形式:
- SEGMENT-PAIR + NSP:这遵循了 BERT 中使用的原始输入格式,其中包含 NSP loss。每个输入都有一对 segment,每个 segment 可以包含多个自然句子,但总的长度必须小于 512 token。
- SENTENCE-PAIR + NSP:每个输入包含一对自然句子,可以从一文档的连续部分取样,也可以从不同的文档中取样。由于这些输入明显短于 512 token,作者增加了 batch_size,使 token 的总数与 SEGMENT-PAIR + NSP 保持一致。并且保留了 NSP loss。
- FULL-SENTENCES:每个输入都是由一个或多个文档中连续取样的完整句子组成,因此总长度最多为 512 token。输入的内容可能会跨越文档的边界。当我们抵达一个文档的末尾时,开始从下一个文档中抽取句子,并在文档之间增加一个额外的分隔符。去除 NSP loss。
- DOC-SENTENCES:输入的构造与 FULL-SENTENCES 类似,只是它们不能跨越文档的边界。在文档末尾附近取样的输入可能短于 512 token,因此在这些情况下动态地增加 batch_size,以达到与 FULL-SENTENCES 相似的总 token 数。去除 NSP loss。
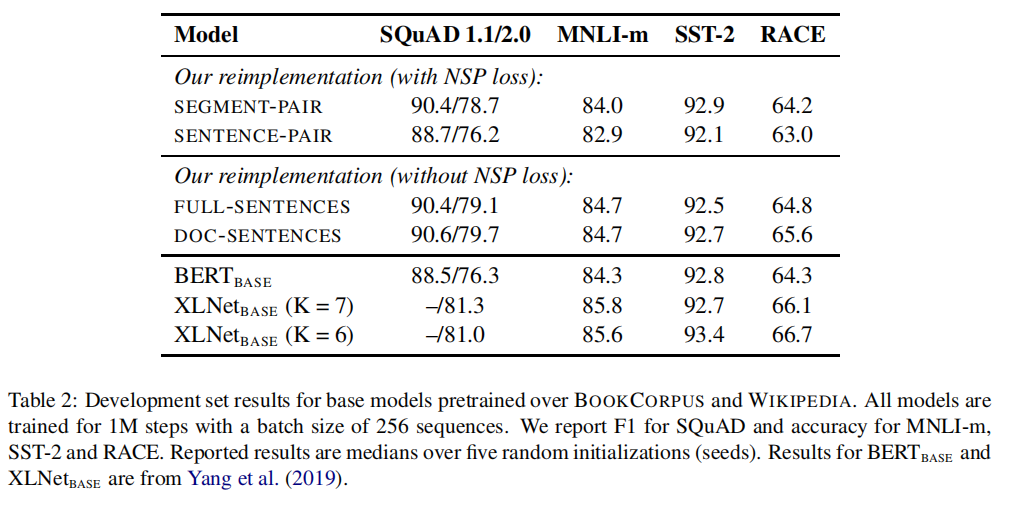
结果:表 2 显示了四个不同设置的结果。
- 首先比较 SEGMENT-PAIR 格式和 SENTENCE-PAIR 格式,两者都保留 NSP loss,但 SENTENCE-PAIR 使用单句。作者发现,使用单个句子会损害下游任务的性能,作者假设这是因为模型无法学习长距离的依赖关系。
- 接着比较没有 NSP loss 和 DOC-SENTENCES 中的文本块训练。作者发现,这种设置优于 vanilla $BERT_{BASE}$ 的结果,并且去除 NSP loss 后,与 vanilla BERT 的下游任务性能相匹配或略有改善。有可能 vanilla BERT 只是删除了 loss 项,而仍然保留了 SEGMENT-PAIR格式。
- 最后,作者发现,限制序列来自单一文档(DOC-SENTENCEs)的表现略好于包含多个文档的序列(FULL-SENTENCES)。然而,由于 DOC-SENTENCES 格式会导致 batch_size 的变化,作者在其余的实验中使用 FULL-SENTENCES,以便于与相关工作进行比较。
使用更大的 batch 训练
过去在神经机器翻译方面的工作表明,在适当提高学习率的情况下,用非常大的 batch_size 训练,既可以提高优化速度,也可以提高最终任务的性能。最近的工作表明,BERT 也适用于较大的 batch_size。
Devlin 等人最初对 $BERT_{BASE}$ 进行了 1M 步的训练,batch_size = 256。通过梯度积累,这在计算成本上相当于训练 125k 步,batch_size = 2k,或 31k 步,batch_size = 8k。
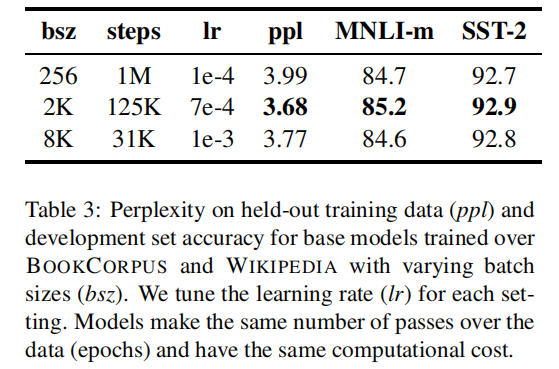
在表 3 中,作者比较了 $BERT_{BASE}$ 的 PPL 和 end-task 性能,因为增加了 batch_size,控制了训练数据的通过次数。作者观察到,较大 batch_size 的训练提高了 MLM 目标的复杂度,以及 end-task 的准确性。较大 batch_size 的训练也更容易通过分布式数据并行训练。在后续的实验中,作者使用 8k 大小的batch_size 进行训练。
文本编码
字节对编码(Byte-Pair Encoding,BPE)是字符和词级表征的混合体,可以处理自然语言语料库中常见的大词汇。BPE 依赖于子词单元,而不是全词。子词单元是通过对训练语料库进行统计分析而提取的。BPE 的词汇量通常在 10k-100k 个子词单元之间。然而,在对大型和多样化的语料库进行建模时,如本工作中所考虑的语料库,unicode 字符可以占到该词汇相当大的一部分。
Radford 等人介绍了 BPE 的一个巧妙实现,使用字节而不是 unicode 字符作为基本的子词单元。使用字节使得学习一个规模不大的子词词汇表(50k)成为可能,该词汇表仍然可以对任何输入文本进行编码,而不会引入任何“unknown”token。
原始 BERT 实现使用大小为 30k 的字符级 BPE 词汇表,该词汇表是在用启发式 tokenization 规则对输入进行预处理后学习的。跟随 Radford 等人的工作,作者转而考虑用包含 50k 个子词单元的更大的字节级 BPE 词汇表来训练 BERT,而不对输入进行任何额外的预处理或 tokenization。这为 $BERT_{BASE}$ 和 $BERT_{LARGE}$ 分别增加了大约 15M 和 20M 的额外参数。
早期的实验显示,这些编码之间只有轻微的差异,Radford 等人的 BPE 在一些任务上取得的最终任务表现略差。然而,作者认为通用编码方案的优势超过了性能上的轻微下降,并在剩余的实验中使用了这种编码方式。
RoBERTa
在上一节中,作者提出了对 BERT 预训练过程的修改,以提高最终任务的性能。本节汇总这些改进并评估其综合影响。作者称这种配置为 Robustly optimized BERT approach = RoBERTa。具体来说,RoBERTa 是采用动态 mask、去除 NSP loss 的 FULL-SENTENCES、更大 batch_size 和字节级 BPE 训练所得的模型。
此外,作者还调查了其他两个重要的因素,这些因素在先前的工作中没有得到充分的重视:1)用于预训练的数据,以及2)数据的训练次数。例如,最近提出的 XLNet 架构的预训练使用了比原始 BERT 多近 10 倍的数据,还以 8 倍 batch_size 和 0.5 倍优化步骤,因此相比原始 BERT,XLNet 在预训练阶段中可以看到四倍的序列数量。
为了帮助将这些因素的重要性与其他建模选择(例如,预训练目标)区分开来,作者首先按照 $BERT_{LARGE}$ 架构训练 RoBERTa(L= 24,H = 1024,A = 16335M 参数量)。作者在 BOOK-CORPUS 和 wikipedia 数据集上预训练了 100K 步(正如 Devlin 等人所预训练的那样)。作者使用 1024 个 V100 GPU 对模型进行大约 1 天的预训练。
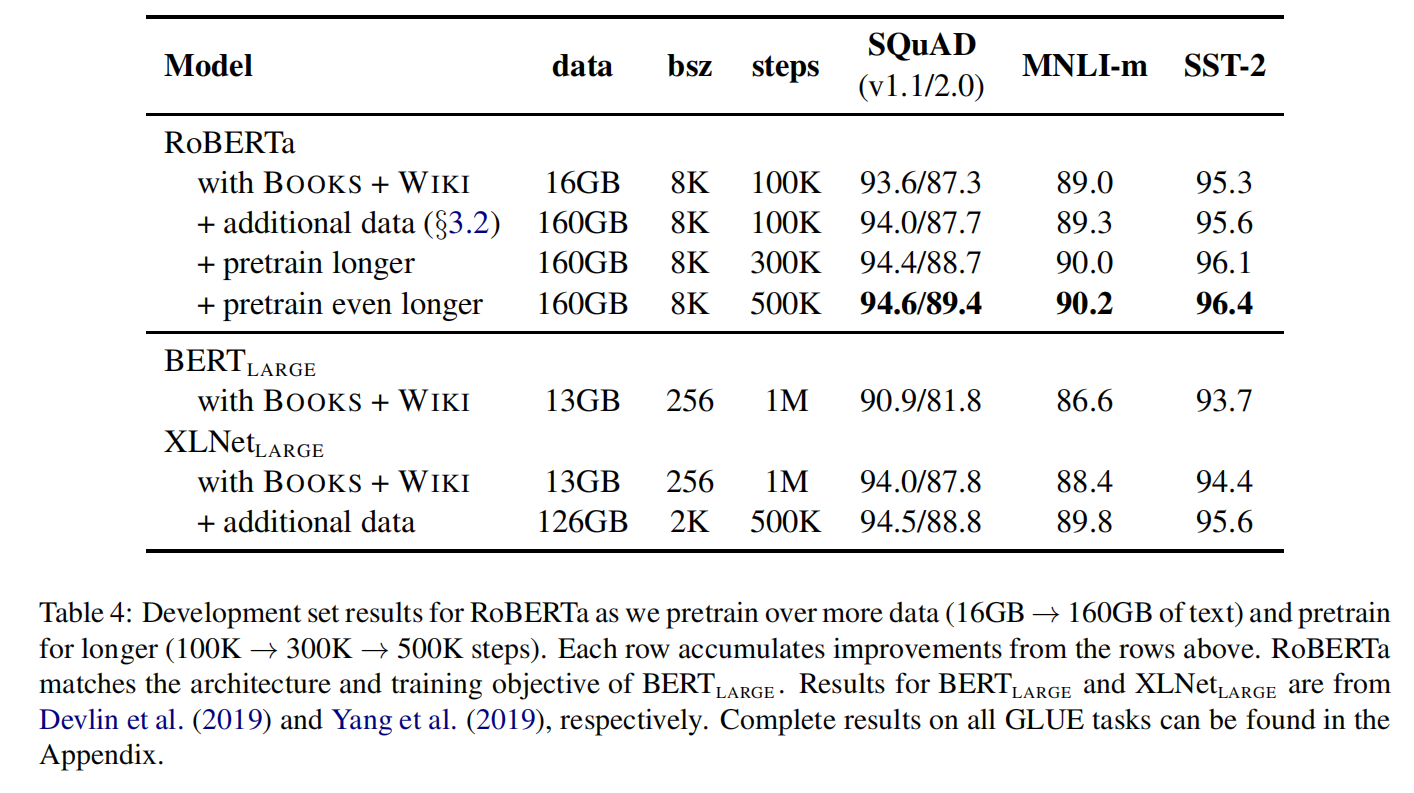
结果:在表 4 中介绍了结果。当控制训练数据时,作者观察到 RoBERTa 比最初报告的 $BERT_{LARGE}$ 有很大的改进,再次证实在上一节探讨的设计选择的重要性。接下来,作者将这些数据与额外的三个数据集相结合,在这些合并数据集上训练 RoBERTa,训练步骤为 100K。总的来说,对 160GB 的文本进行预训练。作者观察到所有下游任务的性能都有进一步的提高,验证了数据规模和多样性在预训练中的重要性。最后,作者延长对 RoBERTa 的预训练时长,将预训练的步数从 100K 增加到 300K,然后再增加到 500K。再次观察到下游任务性能的显著提高,300K 和 500K 模型在大多数任务中都优于 $XLNet_{LARGE}$。此外,即使训练时间最长的模型,似乎也没有过拟合,且可能会从额外的训练中受益。
相关工作
预训练方法的设计有不同的训练目标,包括语言建模、机器翻译和 MLM。最近的许多论文都采用了为每个 end-task 微调模型,并以某种变体的 MLM 目标进行预训练。然而,较新的方法通过多任务微调、纳入实体嵌入、span 预测和自回归预训练的多种变体来提高模型性能。通过在更多的数据上训练更大的模型,性能通常也会得到改善。
总结
在对 BERT 模型进行预训练时,作者仔细评估了一些操作。作者发现,通过对模型进行更长时间的训练,在更多数据上进行更大 batch_size 的训练,性能可以得到大幅提高;取消 NSP 任务;在更长的序列上进行训练;以及动态地改变应用于训练数据的 mask 方式。
作者改进的预训练过程被称之为 RoBERTa,在 GLUE、RACE 和 SQuAD 任务上取得了最佳的效果。对于 GLUE 来说,不需要进行多任务微调;对于 SQuAD 来说,不需要额外的数据。这些结果说明了这些在之前被忽视的操作的重要性,并表明 BERT 的预训练目标与最近提出的替代方案相比仍然具有竞争力。