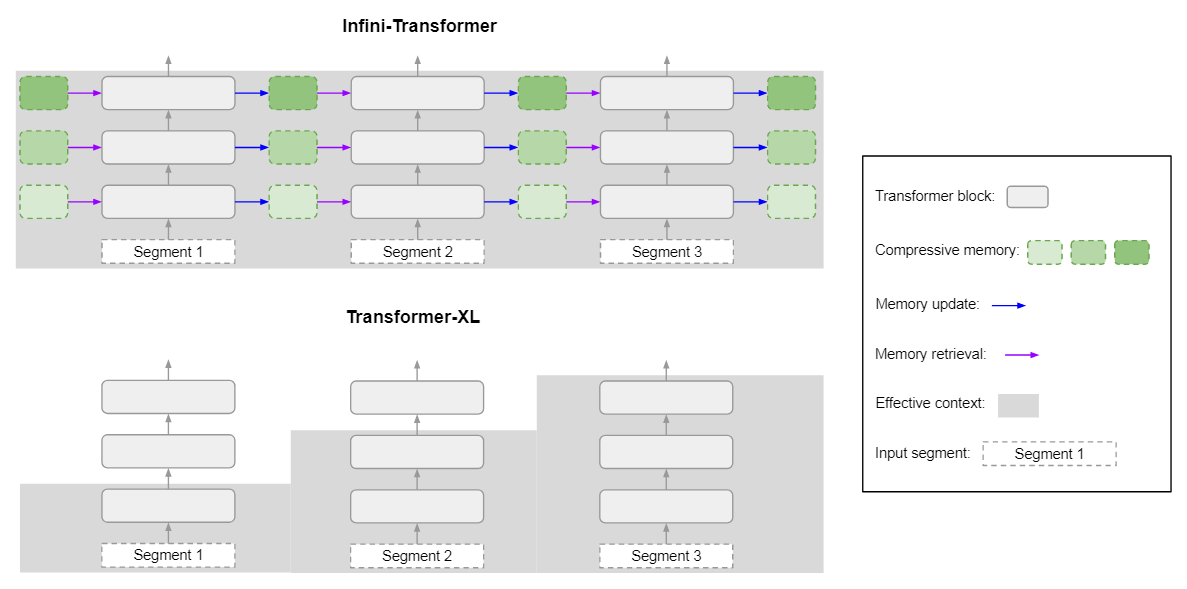
论文阅读:Scaling Transformer to 1M tokens and beyond with RMT
AI 速读
Basic Information:
- Title: Scaling Transformer to 1M tokens and beyond with RMT (使用RMT将Transformer扩展到100万个令牌及以上)
- Authors: Aydar Bulatov, Yuri Kuratov, and Mikhail S. Burtsev
- Affiliation: DeepPavlov (Aydar Bulatov), Artificial Intelligence Research Institute (AIRI) (Yuri Kuratov), London Institute for Mathematical Sciences (Mikhail S. Burtsev)
- Keywords: Transformer, BERT, Recurrent Memory Transformer, long sequences, memory augmentation
- URLs: https://arxiv.org/abs/2304.11062, GitHub: None
摘要:
文章研究背景:本文介绍了一种新的技术来扩展自然语言处理中流行的基于Transformer的模型BERT的上下文长度,该技术将循环内存与基于标记的内存机制相结合。该方法允许存储和处理本地和全局信息,并在输入序列的不同部分之间启用信息流。通过扩展带有循环内存的BERT模型,作者能够存储跨越多达7个长度为512个单词的片段的任务特定信息,利用带有2,048,000个单词总长度的4,096个片段的存储。这比变形金刚模型报告的最大输入尺寸要大得多,其中CoLT5的最大输入尺寸为64K个单词,而GPT-4的最大输入尺寸为32K个单词。作者的实验表明,所提出的方法保持了基本模型的存储器大小为3.6GB。该方法显示了提高自然语言理解和生成任务中的长期依赖处理能力的潜力,以及为内存密集型应用程序提供大规模上下文处理的能力。
背景:
- a. 主题和特征:
- 本文介绍了Recurren Memory Transformer(RMT),它是一种神经架构,它将内存合并在一起来解决转换器中长输入的问题。
- b. 历史发展:
- 之前的模型存在输入长度限制的问题,限制了模型的应用范围。
- c. 过去的方法:
- 过去的方法通常通过截断输入文本以适应基于Transformer的模型的输入长度限制来缓解模型性能问题。
- d. 过去研究的缺点:
- 由于输入文本截断的限制,过去的模型可能无法处理长文本或提供准确的输出。
- e. 当前需要处理的问题:
- 基于Transformer的模型需要更长的上下文长度和更好的内存处理能力来解决越来越复杂的自然语言处理任务。
方法:
- a. 研究的理论基础:
- RMT架构由m个可训练的真实值向量组成的内存组成,将输入分为多个段,将存储向量前置到第一个段的嵌入中,并与片段标记一起进行处理。对于仅编码器模型(如BERT),在片段开头仅添加一次存储器。在训练过程中,梯度从当前片段通过内存流到前一个片段。前向传递后,更新的片段内存标记存储在输出中。通过将来自当前段的内存标记的输出传递到下一段的输入来实现循环。RMT中的内存和循环都基于全局内存标记,使RMT内存增量兼容Transformer家族中的任何模型。
- b. 研究的技术路线1:
- 首先,将每个段的数据进行对齐和嵌入,并将内存向量添加到第一个段的嵌入中,进行处理。
- c. 研究的技术路线2:
- 然后,在训练过程中使用梯度,将存储和当前段一起传递到下一段,并将更新的内存标记存储在输出中。
结论:
- a. 工作的意义:
- 在自然语言处理任务中,超长文本、深层网络和模型复杂度是常见的限制。本文提出了一种新的方法,可以提高处理过程中的严密性、可靠性和效率。
- b. 创新、性能和工作量:
- 提出的方法具有优雅的架构和实现,并且在长期记忆任务上实现了极高的性能。
- c. 研究结论(列出要点):
- 循环内存变换器(RMT)是一种内存-augmented transformer架构。
- 其中,内存和循环都基于全局记忆标记,从而使其兼容Transformer家族中的任何模型。
- 应用于记忆密集的合成任务时,RMT表现出非常高的效率。
- 该方法显示了提高Transformer模型的能力的潜力,使其能够处理更大的输入序列,并提供更准确、具有上下文相关性的输出。在未来,作者计划将RMT方法应用于常用Transformers,以改善它们的有效上下文尺寸。
本技术报告介绍了应用递归记忆(recurraent memory)来扩展 BERT 的上下文长度,BERT 是自然语言处理中最有效的基于 Transformer 的模型之一。通过利用递归记忆 Transformer 架构,成功地将该模型的有效上下文长度增加到了前所未有的 200 万条,同时保持了较高的记忆检索精度。
该方法允许存储和处理局部和全局信息,并通过使用递归实现输入序列中各段之间的信息流动。实验证明该方法的有效性,它在加强自然语言理解和生成任务中的长期依赖性处理以及为内存密集型应用实现大规模的上下文处理方面具有重大潜力。
循环内存 Transformer(RMT)
从最初的 Recurrent Memory Transformer(Bulatov 等人,2022)(RMT)开始,将其改编为即插即用的方法,作为一系列流行 Transformer 的包装器。这种改编用 memory 增强主干,由 m 个实值可训练向量组成(图 2)。
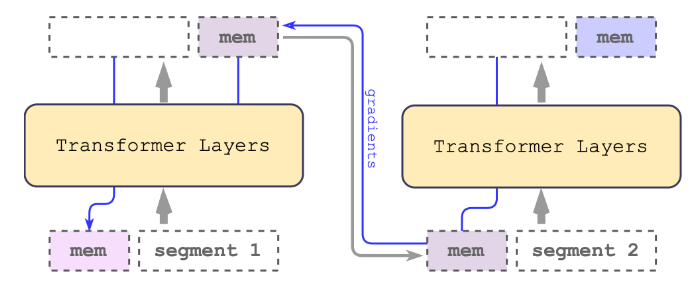
图 2:循环记忆机制。记忆沿着输入序列嵌入传递给 Transformer,而记忆的输出则传递给下一个片段。在训练过程中,梯度从当前段通过 memory 流向前段。
冗长的输入被划分为不同的片段,memory 向量被预置到第一个片段嵌入中,并与片段 token 一起处理。对于像 BERT 这样的纯编码器模型,memory 只在段的开始处添加一次,这与(Bulatov 等人,2022)不同,他们的解码模型将 memory 分为读和写两部分。对于时间步长 $\mathcal{T}$ 和片段 $H_{T}^0$,递归步骤按以下方式进行:
$$
\tilde{H}_\tau^0=\left[H_\tau^{m e m} \circ H_\tau^0\right], \bar{H}_\tau^N=\text { Transformer }\left(\tilde{H}_\tau^0\right),\left[\bar{H}_\tau^{m e m} \circ H_\tau^N\right]:=\bar{H}_\tau^N,
$$
这里 N 是 Transformer 层的数量。在前向传递之后,$\bar{H}_\tau^{mem}$ 包含段 T 的最新 memory token。输入序列的片段被依次处理。为了实现递归连接,将当前段的 memory token 的输出传递给下一个段的输入:
$$
H_{\tau + 1}^{mem} := \bar{H}\tau^{mem}, \tilde{H}{\tau + 1}^0 = \left[H_{\tau + 1}^{mem} \circ H_{\tau + 1}^0\right].
$$
RMT 中的内存和递归都只基于全局 memory token。这允许主干 Transformer 保持不变,使 RMT memory 增强与 Transformer 家族的任何模型兼容。
计算效率
可以估计不同大小和序列长度的 RMT 和 Transformer 模型所需的 FLOPs,采取 OPT 模型家族的配置(词汇量大小、层数、隐藏大小、中间隐藏大小和注意头数),并计算了前向传递后的 FLOP 数量。还修改了 FLOP 估计值,以考虑到 RMT 复现的影响。
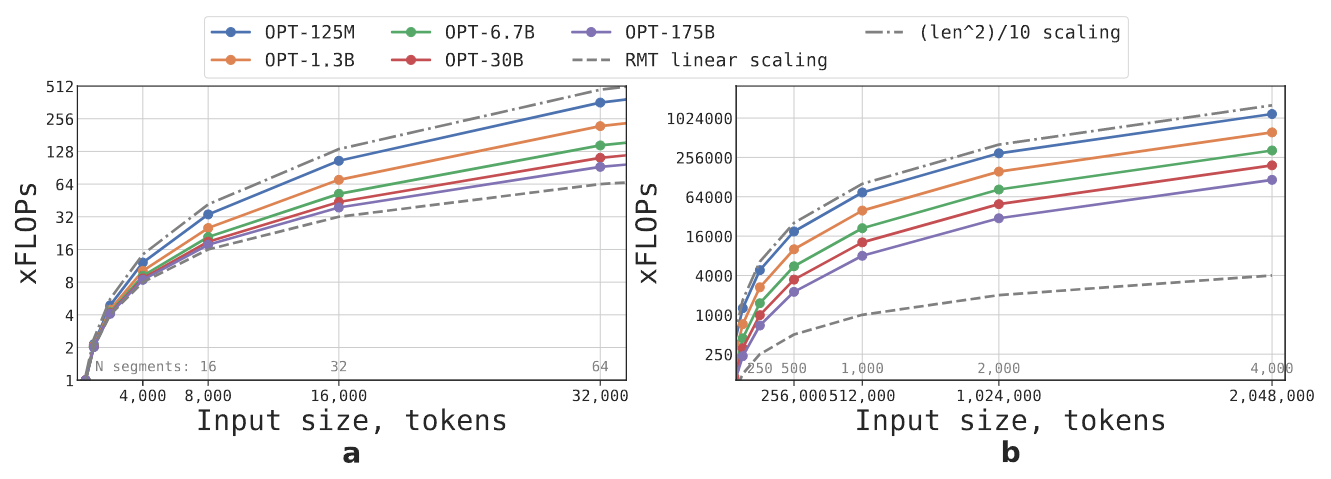
图 3:RMT 推断与输入序列长度呈线性关系。作者估计,与在 512 个 token 的序列上运行模型相比,前向传递所需的 FLOP 增加。a: 长度从 512 到 32000 tokens。b: 长度从 32000 到 2048000 tokens。RMT 段的长度固定为 512 个 token。虽然较大的模型(OPT-30B、OPT-175B)在相对较短的序列上往往表现出接近线性的缩放,但在较长的序列上达到二次缩放。较小的模型(OPT-125M,OPT-1.3B)甚至在较短的序列上也表现出二次缩放。在具有 2048000 个 token 的序列上,RMT 可以用比 OPT-135M 少 x 29 的 FLOPs 和 x295 的 FLOPs 来运行 OPT-175B。
图 3 显示,如果片段长度固定,RMT 对任何模型大小都是线性扩展的。作者通过将一个输入序列划分为若干段,只在段的边界内计算全部注意力矩阵来实现线性扩展。较大的 Transformer 模型倾向于表现出相对于序列长度较慢的二次扩展,因为计算量大的 FFN 层(相对于隐藏大小的二次扩展)。然而,在超过 32,000 的极长序列上,它们又回到了二次扩展的状态。对于有一个以上片段的序列(在本研究中 > 512),RMT 需要的 FLOPs 比非递归模型少,可以减少 FLOPs 的数量达 x 295 倍。RMT 为较小的模型提供更大的 FLOPs 相对减少,但在绝对数字上,OPT-175B 模型的减少量为 29 倍,非常显著。
记忆任务
为了测试记忆能力,构建了合成数据集,要求记忆简单的事实和基本推理。任务输入包括一个或几个事实和一个只能用所有这些事实来回答的问题。为了增加任务难度,添加了与问题或答案无关的自然语言文本。这些文本就像噪音一样,所以模型的任务是将事实从无关的文本中分离出来,并利用它们来回答问题。该任务被制定为 6 类,每类代表一个单独的答案选项。
事实是使用 bAbI 数据集(Weston 等人,2016)生成的,而背景文本来自 QuALITY(Pang 等人,2022)长 QA 数据集的问题。
1 | Background text: ... He was a big man, broad-shouldered and still thin-waisted. Eddie found it easy to believe the stories he had heard about his father ... |
事实记忆
第一个任务是测试 RMT 在 memory 中长时间写入和存储信息的能力(图 4,顶部)。在最简单的情况下,事实总是位于输入的开头,而问题总是在最后。问题和答案之间的不相关文本的数量逐渐增加,因此,整个输入不适合于单一模型输入。
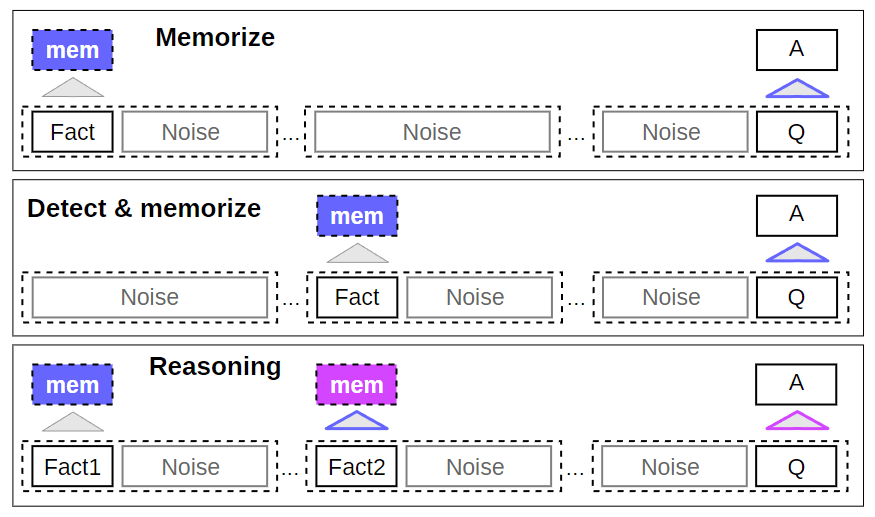
图 4:内存密集型的合成任务。介绍了合成任务和解决这些任务所需的 RMT 操作。在记忆任务中,一个事实声明被放在序列的开头。在检测和记忆任务中,一个事实被随机地放在文本序列中,使其检测更具挑战性。在推理任务中,提供答案所需的两个事实被随机地放在文本中。对于所有的任务,问题都在序列的最后。“mem”表示 memory tokens,“Q”代表问题,“A”标志着答案。
1 | Fact: Daniel went back to the hallway. |
事实检测 & 记忆
事实检测通过将事实输入中的一个随机位置来增加任务难度(图 4,中间)。这就要求模型首先将事实与不相关的文本区分开来,将其写入记忆,然后用它来回答位于最后的问题。
用记忆中的事实进行推理
记忆的另一个重要操作是利用记忆的事实和当前的上下文进行推理。为了评估这个功能,作者使用了一个更复杂的任务,在这个任务中,两个事实被生成,并被随机地放置在输入序列中(图 4,底部)。在序列末尾提出的问题是以任何一个事实都必须被用来正确回答问题的方式提出的(即两个论据关系 bAbI 任务)。
1 | Fact1: The hallway is east of the bathroom. |
实验
使用 HuggingFace Transformers 中预训练的 Bert-base-cased 模型作为所有实验中 RMT 的主干。所有模型的内存大小为 10,并使用 AdamW 优化器进行训练,采用线性学习率调度和预热。完整的训练参数将在 GitHub 仓库的训练脚本中提供。
https://github.com/booydar/t5-experiments/tree/scaling-report
使用 4-8 个 Nvidia 1080ti GPU 训练和评估模型。对于较长的序列,通过切换到单个 40GB 的 Nvidia A100 来加速评估。
课程学习
作者观察到,使用训练 schedule 可以大大改善解决方案的准确性和稳定性。最初,RMT 在较短的任务版本上进行训练,在训练收敛后,通过增加一个片段来增加任务长度。这个课程学习过程一直持续到达到所需的输入长度。
在实验中,从适合单段的序列开始。实际段的大小为 499,因为从模型输入中保留了 3 个 BERT 的特殊 token 和 10 个内存占位符,大小为 512。作者注意到,在对较短的任务进行训练后,RMT 更容易解决较长的版本,因为它使用较少的训练步骤就能收敛到完美的解决方案。
实际段的大小为什么是 499?而不是 509?
外推能力
RMT 对不同序列长度的泛化能力如何?为了回答这个问题,作者评估了在不同数量的片段上训练的模型,以解决更大长度的任务(图 5)。作者观察到,模型在较短的任务上往往表现良好。唯一的例外是单段推理任务,一旦模型在较长的序列上进行训练,它就很难解决。一个可能的解释是,由于任务规模超过了一个片段,模型在第一个片段就停止了对问题的预期,导致质量下降。
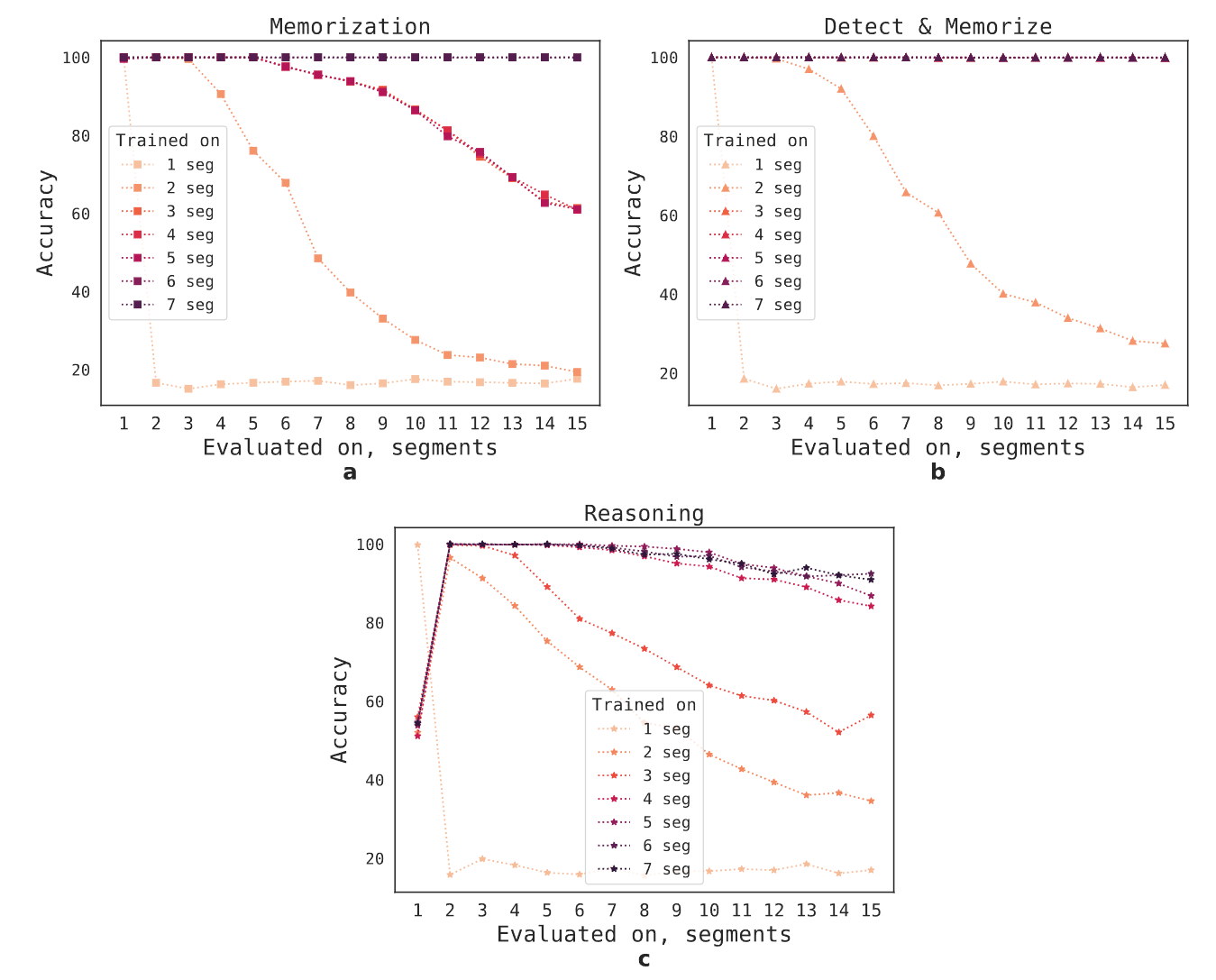
图 5:记忆检索的泛化。对在不同输入长度的 1-7 段任务上训练的检查点的评估。a:记忆任务。b:检测和记忆,c:推理。在 5 段以上的任务上训练的模型在更长的任务上有很好的泛化性。
有趣的是,随着训练片段数量的增加,RMT 对更长序列的泛化能力也出现了。在对 5 个或更多的片段进行训练后,RMT 可以对两倍长的任务进行几乎完美的泛化。
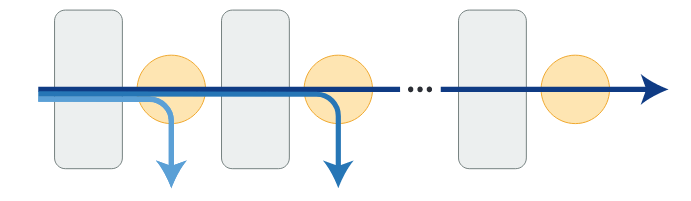
为了测试泛化的极限,作者将验证任务的规模增加到 4096 段或 2,043,904 个 token(图 1)。RMT 在如此长的序列上保持得出奇的好,其中 Detect & memorize 最简单,Reasoning 任务最复杂。
记忆操作的注意力模式
通过检查 RMT 在特定片段上的注意力,如图 6 所示,观察到记忆操作对应于注意力的特定模式。此外,如第 4.2 节所述,在极长的序列上的高外推性能表明了所学的记忆操作的有效性,即使是在使用了数千次之后。考虑到这些操作并没有明确地受到任务损失的激励,这一点尤其令人印象深刻。
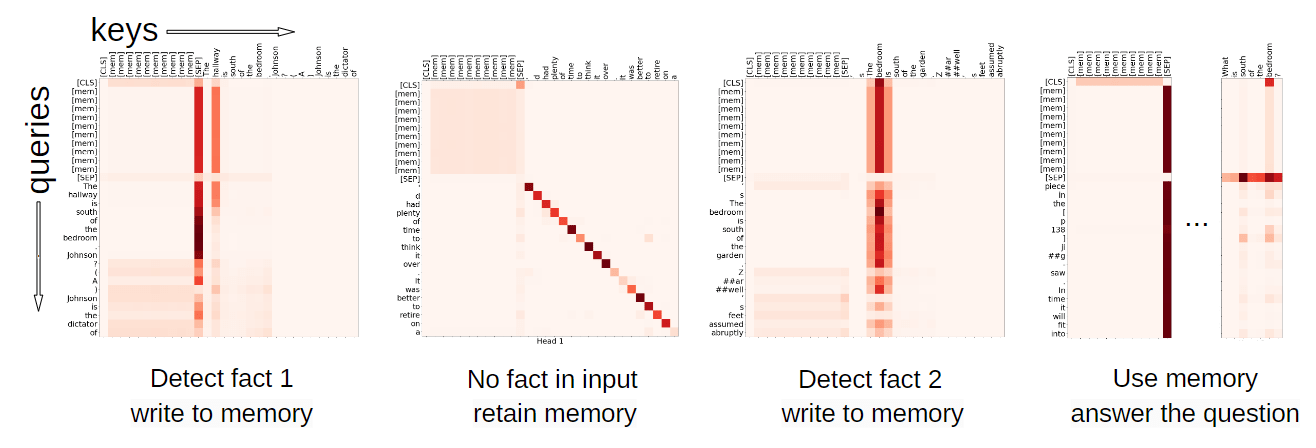
图 6:使用记忆操作的注意力图。这些热图显示了在 4 段推理任务的特定时刻进行的操作。每个像素的暗度取决于相应的 key 和 value 之间的注意力值。从左到右:RMT 检测第一个事实并将其内容写入内存([mem] token);第二段不包含任何信息,所以内存保持不变;RMT 检测推理任务中的第二个事实并将其附加到内存中;CLS 从内存中读取信息以回答问题。
相关工作
该工作围绕着神经结构中的记忆概念展开。记忆一直是神经网络研究中反复出现的主题,可以追溯到早期的工作,并在 20 世纪 90 年代随着 Backpropagation Through Time 学习算法和 LSTM 神经架构的引入而取得了重大进展。当代记忆增强的神经网络(MANNs)通常利用某种形式的、与模型参数分离的循环性外部记忆。神经图灵记(NTMs)和记忆网络配备了通过注意力机制访问的向量表征的存储。记忆网络被设计为通过对记忆内容的顺序注意来实现推理。
讨论
自动 Transformers 架构普及以来,对该架构中的长输入问题进行了广泛的研究。在这项工作中,作者证明将 Transformer 应用于长文本并不一定需要大量的内存。通过采用递归方法和记忆,二次方的复杂性可以减少到线性。此外,在足够大的输入上训练的模型可以将其能力外推到更多数量级的文本。
本研究中探索的合成任务是使 RMT 能够推广到具有未见属性的任务的第一个里程碑,包括语言建模。在未来的工作中,目标是为最常用的 Transformer 量身定制递归记忆方法,以提高其有效的上下文规模。