论文阅读:Selective Text Augmentation with Word Roles for Low-Resource Text Classification
数据增强技术被广泛用于文本分类任务中,以提高分类器的性能,特别是在低资源的情况下。以前的大多数方法在进行文本扩增时没有考虑文本中不同功能的词,这可能会产生不满意的样本。不同的词在文本分类中可能扮演不同的角色,这就促使我们从战略上选择适当的角色来进行文本扩增。
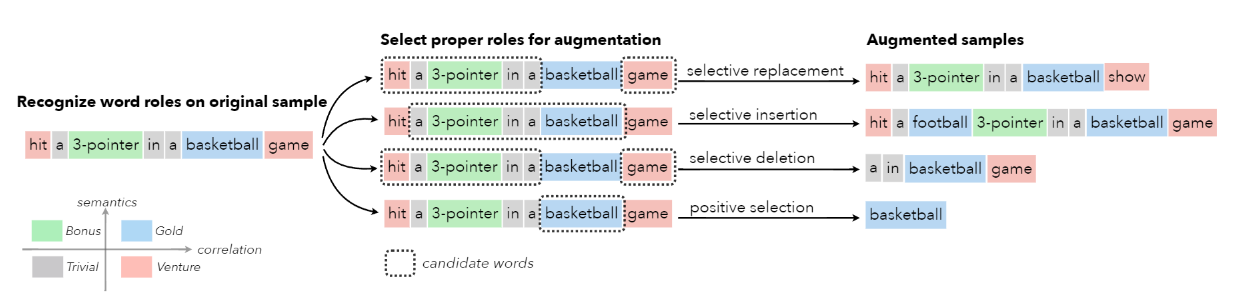
在这项工作中,首先从统计相关性和语义相似性的角度来识别文本中的词语和文本类别之间的关系,然后利用这些关系将词语分为四个角色–Gold、Venture、Bonus 和 Trivial,它们在文本分类中具有不同的功能。基于这些词的角色,作者提出了一种新的增强技术,称为STA(Selective Text Augmentation),其中不同的文本编辑操作被选择性地应用于具有特定角色的词。
STA 可以生成多样化和相对干净的样本,同时保留了原始的核心语义,而且实现起来也相当简单。在 5 个基准的低资源文本分类数据集上进行的大量实验表明,由 STA 产生的增强样本成功地提高了分类模型的性能,大大超过了以前的非选择性方法。跨数据集实验进一步表明,与以前的方法相比,STA 可以帮助分类器更好地推广到其他数据集上。
方法
词语角色识别
词语角色
假设有一个文本分类任务,要训练一个模型,从 $C = {c_1, c_2, \ldots, c_k}$ 中给一个句子或文档分配一个标签。训练集为 D,其词语表为 V。对于一个词语 $w_i \in V$ 和一个类别 $c_j \in C$,可以从两方面考察它们的关系。
- 统计相关性:衡量 $w_i$ 和 $c_j$ 类共同出现的频率,而不是与训练集中的其他类共同出现的频率。
- 语义相似性:衡量 $w_i$ 和 $c_j$ 类的语义相似程度。
通过这两个属性,训练数据集中的所有词可以被分为四个不同的橘色(见图 1)。

词语角色识别
为了识别数据集中不同角色的词语,应该决定适当的指标来衡量上述两个属性。
为了测量与类的统计相关性,采用加权对数似然比(WLLR)来从文本样本中选择与类相关的词。WLLR 被用来找出情感分析的“支点词”。WLLR 分数的计算公式如下所示:
$$
wllr(w, y) = p(w|y) log \frac{p(w|y)}{p(w|\hat{y})}
$$
其中,w 是一个词,y 是某个类别,$\hat{y}$表示数据集中的所有其他类别。$p(w|y)$ 和 $p(w|\hat{y})$ 分别是在标有 y 和其他标签的样本中观察到 w 的概率。使用某个词在某类中出现的频率来估计概率。
为了测量与类的语义相似性,一个直接的方法是使用 skip-gram 或 Glove 预训练的词向量。由于推理成本较高,不适用类似 BERT 这样的基于 transformer 的模型进行相似性测量。一些人还发现,在相似性测量任务中,静态词向量可以达到与 BERT 类模型相当甚至更好的性能,特别是在词级别。
计算一个词和一个类别标签之间的余弦相似度,以查看它们的语义距离:
$$
similarity(w, l) = \frac{v_w \cdot v_l}{||v_w|| ||v_l||}
$$
其中,l 表示标签,$v_w, v_l$ 分别是词 w 和标签 l 的词向量。也可以使用标签的描述来获得 $v_l$,通过对描述中每个词的词向量进行平均来获得更好的标签表征。在作者的实验中,仅仅使用标签词语或短语本身就足以衡量一个词语和标签之间的相似性。
计算每个词的 WLLR 和相似度分数,并设置一个阈值来划分高分和低分,从而将词语划分为四个级别。
给定一个训练样本,有两种策略可以将角色分配给文本中的词:全局或局部。
- 全局策略:根据词汇中的所有词语来决定角色划分的阈值;
- 局部策略:根据当前样本中的词语来划分。换句话说,局部策略使用相对的观点来区分高分和低分,因此,当一个词出现在另一个样本中时,它的角色可能会改变。
选择性文本增强
基于识别的词语角色,提出了一种新的文本增强技术,称为STA(选择性文本增强),它包括四种操作:
- 选择性替换:选择 n 个词语,除了 Gold 词语,其他被选择的词语都会被同义词进行替换。
- 选择性插入:选择 n 个词语,除了 Venture 词语,其他被选择词语的同义词插入原文中的随机位置。
- 选择性删除:选择 n 个词语,除了 Gold 词语,其他被选择的词语都会被删除。
- 正例选择:只选择 Gold 词语,并将其串联成一个新的句子。通过这样做,只保留最重要的部分。为了使新句子更加自然,还随机插入一些 Trivial 词语和标点符号。
实验
主要结果
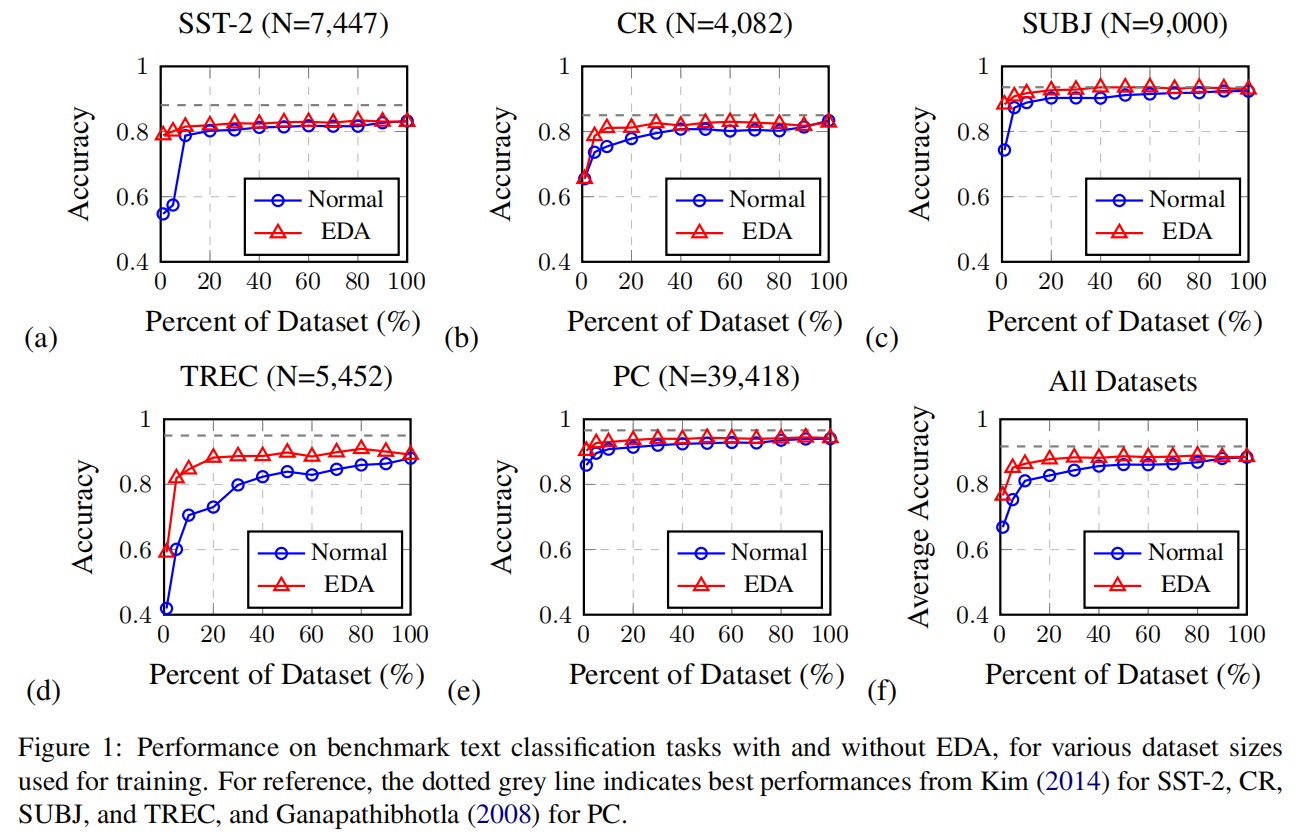
如表 2 所示,所有文本增强方法都有利于文本分类器在低资源环境下提高性能。在所有基线中,EDA-w2v 和 Back-Trans 是有竞争力的方法,它们明显优于 MLM-Aug。
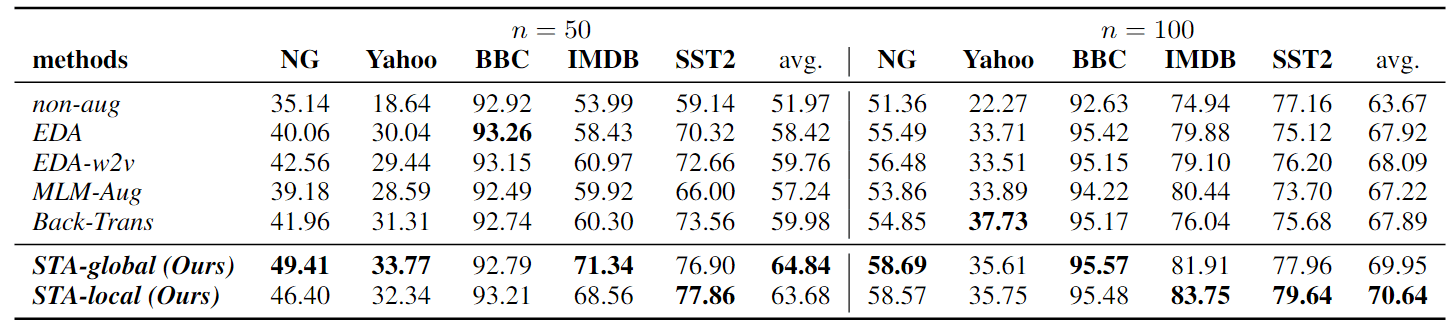
表 2:不同文本增强方法的分类准确率比较
STA 的两种策略都明显优于其他基线:
- 当 n = 50 时,STA-global 的平均准确率比最佳基线(Back-Trans)提高了近 5%;
- 当 n = 100 时,STA-local 的平均准确率比最佳基线(EDA-w2v)提高了 2.6%。
特别是对于 NG 数据集(包含 20 个类别和许多子类别的相当复杂的文本分类数据集),STA-global 在只有 50 个初始训练示例的情况下,比 EDA-w2v 提高了近 7% 的性能。对于长文本情感分类任务 IMDB,当 n = 50 时,STA-global 的性能比 EDA-w2v 提高了近 10%。
这些结果表明,与传统的非选择性数据增强方法相比,利用词角色知识并有选择地扩增文本,STA 可以帮助模型获得更好的泛化能力。
比较 STA-global 和 STA-local 的性能,我们可以发现,当样本较少时,全局策略的性能更好,而局部策略则相反。当数据量太小时,用全局策略分配词角色会更准确,这可能就是为什么当训练量只有 50 个时,STA-global 能取得相对更好的结果。
当 n = 50 时,STA 在 BBC 方面略逊于 EDA,这可能是由于过拟合问题造成的,因为 BBC 是一项相对简单的任务,只需 50 个训练样本就能在不增加任何数据的情况下获得 90% 以上的测试准确率。然而,随着训练规模增加到 100,STA 又超过了所有其他基线。当 n = 100 时,Back-Trans 在雅虎数据集上的表现最好,而 STA 在该任务上的表现次之,但 STA 在所有其他任务上都优于 Back-Trans。
请注意:STA 是一种基于文本编辑的轻量级增强方法,不使用任何大型模型。虽然在词角色识别过程中需要使用 word2vec 嵌入来计算语义相似性,但与使用大型预训练转换器模型进行扩增的 MLM-Aug 和 Back-Trans 相比,STA 的处理速度要快得多。
消融分析
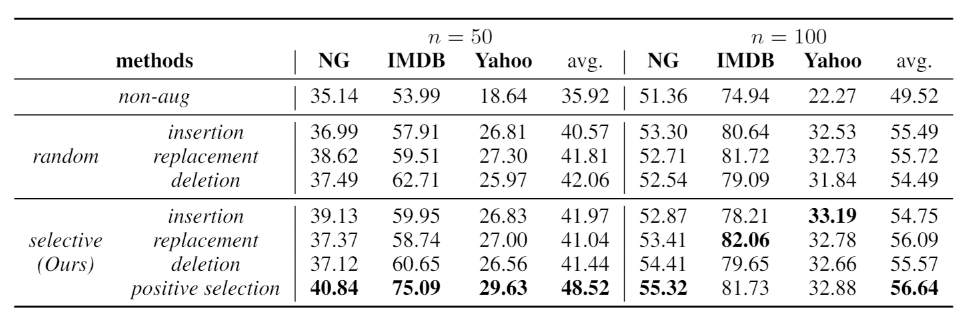
- STA 的正例选择作为低资源文本分类的增强操作特别强大,明显优于其他所有操作。通过正例选择生成的新文本主要是由文本中与标签有高度统计和语义关系的 Gold 词语组成。作者推测,将这些样本加入训练集可以帮助模型学习有关该类的最能说明问题的特征,即使只有少量的数据可用。
- 在数据很少的场景下(n = 50),选择性插入比随机插入更有效,但在提供更多的数据时(n = 100),选择性插入就不那么有用了。相反,选择性删除和选择性替换在较大的训练集中更为有效。这可能是由于当提供更多的标记数据时,词的角色识别会更准确。
总结
在这项工作中,作者首先从两个重要的角度提出了四种词角色,以衡量词与类别之间的关系。然后,提出了一种新的用于文本分类的数据增强技术 STA,该技术可根据词角色对文本进行选择性编辑,以保留原始语义,同时为训练集引入更多的多样性。在 5 个基准分类数据及和 3 组跨数据集泛化任务上进行的广泛实验表明,与其他非选择性增强基线相比,STA 可帮助分类器获得更强的泛化能力。
作者提出的 STA 主要基于基本的文本编辑操作,在 STA 的基础上还可以设计更高级的方法,例如利用预训练的语言模型使生成的文本更加流畅。此外,词角色的思想还可以应用于其他任务,如信息检索、文档表征,甚至图像分类。