论文阅读:Self-Alignment with Instruction Backtranslation
作者提出了一种可扩展的方法,通过自动为人类撰写的文本标注相应的指令来建立高质量的指令语言模型。该方法被命名为“指令反向翻译”,首先在少量种子数据和给定网络语料库的基础上对语言模型进行微调。种子模型通过生成网络文档的指令 prompt(自我增强)来构建训练示例,然后从这些候选示例中选择高质量的示例(自我强化)。随后利用这些数据对更强大的模型进行微调。在该方法的两次迭代中对 LLaMA 进行微调,得到的模型优于 Alpaca 排行榜上不依赖蒸馏数据的所有其他基于 LLaMA 的模型,证明了高度有效的自我对齐。
方法
作者的自训练方法假定可以访问基础语言模型、少量种子数据和无标签示例集合,例如网络语料库。未标注数据是人类撰写的大量不同文档,其中包括人类感兴趣的各种主题,但最重要的是没有与指令配对。
- 第一个关键假设:在这个庞大的人类撰写的文本中,存在一些适合作为某些用户指令黄金生成的子集。
- 第二个关键假设:可以预测这些候选黄金答案的指令,并将其作为高质量的示例对来训练指令遵循模型。
因此,作者称之为指令反向翻译的整个过程有两个核心步骤:
- 自我评估:为无标签数据(即网络语料库)生成指令,为指令调整生成(指令、输出)对的候选训练数据。
- 自我修正:自我选择高质量的演示示例作为训练数据,以微调基本模型,从而遵循指令。这种方法以迭代的方式进行,在下一次迭代中,更好的中间指令遵循模型可以改进数据的选择,从而进行微调。
下面将详细介绍这些步骤,图 1 是该方法的概览。

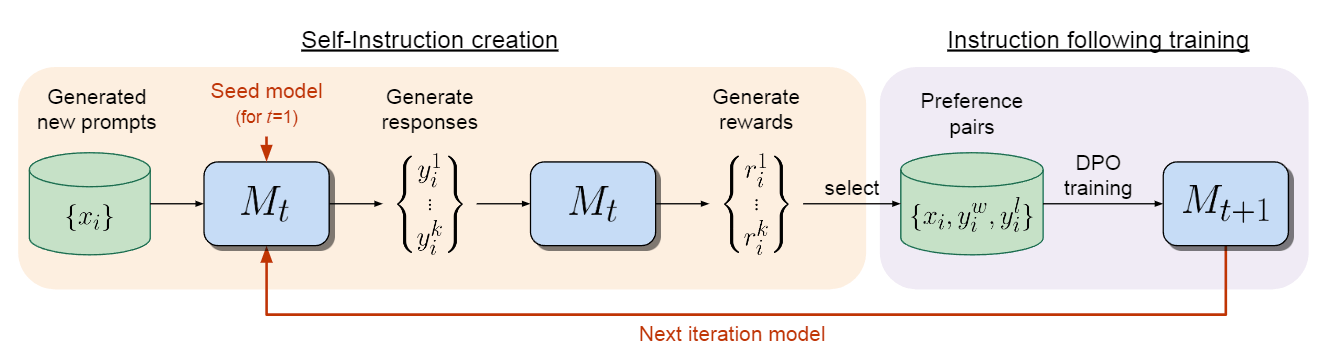
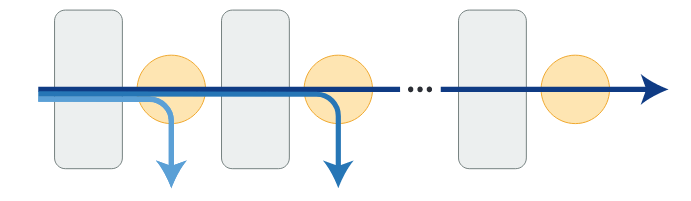
图 1:指令反向翻译方法概述。从一个基础语言模型(如 LLaMa)、少量(指令、输出)对的种子示例和未标记的文档集合开始,这些文档被认为是未知指令的候选输出。自我增强:使用来自种子示例的(输出、指令)对作为指令预测模型 $M_{yx}$,对基础模型进行微调,用于从未标注的数据中为输出生成候选指令。自我校准:从仅根据种子示例微调的中间指令遵循模型 $M_0$ 开始,它从上一步的候选模型中选择高质量的(指令、输出)对$ A^{(1)}_k$,并将其作为下一个中间模型 $M_1$ 的微调数据,而 $M_1$ 又用于选择获得 $M_2$ 的训练数据。
初始化
种子数据:从人类标注的(指令、输出)示例的种子集开始,这些示例将用于微调语言模型,以提供双向的初始预测:预测给定指令的输出和给定输出的指令。
未标注数据:使用网络语料库作为未标注数据源。作者对每篇文档进行预处理,以提取自含片段 ${y_i}$,即 HTML 标题之后的部分文本。进一步进行重复数据删除、长度过滤,并利用几种启发式方法(如标题中大写字母的比例)去除潜在的低质量片段。
自我增强(生成指令)
用种子数据中的(输出、指令)配对 ${(y_i, x_i)}$ 对基础语言模型进行微调,得到一个反向模型 $M_{yx} := p(x|y)$。对于每个未标注的示例 $y_i$,在反向模型上运行推理,以生成候选指令 $\hat{x_i}$,并从中得出候选增强配对数据 $A:={(\hat{x_i}, y_i)}$。并非所有候选配对都是高质量的,在这种情况下,将它们全部用于自训练可能并无益处。因此,要整理出高质量的子集。
自我校准(挑选高质量示例)
使用语言模型本身来选择高质量的示例。首先,建立一个种子指令模型 $M_0$,该模型只对(指令、输出)种子示例进行微调。然后,使用 $M_0$ 对每个增强示例 ${(\hat{x_i}, y_i)}$ 进行评分,得出质量分数 $a_i$。为此,使用了 prompt 方法,指示训练有素的模型以 5 分制对候选配对的质量进行评分。

表 1:自我校正步骤中使用的提示,用于评估自我校正数据集中候选(指令、输出)配对的质量。
表 1 给出了作者使用的精确 prompt。然后,可以从得分 $a_i \geq k$ 的增强示例中选择一个子集,形成一个策划集 $A_k^{(1)}$。
作者进一步提出了一种迭代训练方法,以生成更高质量的预测结果。在第 t 次迭代中,使用上一次迭代中整理的增强数据 $A_k^{(t-1)}$ 和种子数据作为训练数据,对改进后的模型 $M_t$ 进行微调。该模型反过来可用于对增强示例的质量重新评分,从而得到增强集 $A_k^{(t)}$。对数据选择和微调进行两次迭代,最终得到模型 $M_2$。
在结合种子数据和增强数据进行微调时,使用 token 来区分这两种数据源。具体来说,会在示例中附加一个句子(称为“system prompt”)。对于种子数据,使用 $S_a :=$ “Answer in the style of an AI Assistant”。对于增强数据,使用 $S_w :=$”Answer with knowledge from web search.”。这种方法与机器翻译中用于标注合成数据以进行反向翻译的方法类似。
实验
缩放分析
数据质量与数据数量
为了了解数据质量与数据数量对学习指令的重要性,作者对不同质量的增强数据进行了微调比较。具体来说,比较了在没有基于质量选择(w/o curation)的增强数据、$A_4^{(2)}$(得分 ≥ 4)和 $A_5^{(2)}$(得分 ≥ 4.5)类的自选数据上的微调。
结果如图 3 所示。尽管增加了数据数量,但在不进行自我校准的增强数据上进行训练并不能提高指令遵循性能。但是,对增强数据中的高质量部分进行训练会提高指令遵循性能,而且随着增强数据数量的不断增加,性能也会稳步提高。
之前的研究提出了“浅层对齐假说”,即只有几千个高质量的指令遵循示例才足以使预训练好的基础模型与指令保持一致。作者的研究结果提供了一个相反的观察结果,即增加高质量数据的数量会带来进一步的收益(而增加低质量数据的数量则不会)。
消融实验
进行消融研究,以了解该方法的两个关键组成部分。
数据选择质量
为了了解迭代自我校准程序的行为,作者测量了中间模型在选择高质量数据$A_5$时的性能,该$A_5$是由包含 20% 正例(被认为是高质量示例)的 250 个示例组成的 dev 集合。如表 7 所示,在选择高质量数据(精确率/召回率)方面,第二次迭代(使用$M_1$vs.$M_0$)的自我校准性能有所提高。
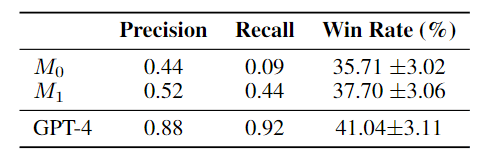
表 7:数据选择方法比较。选择高质量数据的精确度和召回率是在由人类专家(作者)标注为高质量或低质量的 250 个 dev 集上计算得出的。胜率是针对 text-davinci-003 的胜率,是由 7B LLaMa 在所选数据的 100 个示例上进行微调后得到。更好的模型可以选择更高质量的训练数据,这就是该迭代方法取得成功的原因。
此外,正如胜率所显示的那样,在对所选数据进行微调时,这也对应于更好的指令遵循。一个重要的观察结果是,虽然中间模型的精确度并不高,但在选定数据上进行训练仍能改善指令遵循。这有助于解释方法的有效性。
联合训练

图 7:将自校准的数据与种子数据相结合的效果明显优于单独使用种子数据的效果。在没有自校准的情况下使用增强数据表现不佳,这表明校准至关重要。
仅使用自增强数据进行训练
如图 7 所示,如果仅使用自增强数据(无种子数据)进行训练,且不进行自我校准,则指令遵循的质量不会提高,甚至会随着数据量的增加而下降。然而,随着训练集规模的增加,在更高质量的自校准数据上进行训练会带来改善。虽然这种自增强数据的表现并不优于单独缩放的种子训练数据,但在同时使用种子数据和自增强数据进行联合训练时,观察到了很大的改进。这表明种子数据和增强数据是相辅相成的,其中种子数据与目标领域(人工智能助手的响应)具有相同的分布,而来自网络语料库的数据可以扩大指令和输出的多样性。
System prompts
表 8:系统提示对训练和推理的影响。
在表 8 中,区分了系统提示在联合微调和推理过程中的效果。作者发现,添加系统提示以区分增强数据和种子数据很有帮助。有趣的是,在推理时使用组合系统提示 ${S_a, S_w}$(将种子数据提示和增强数据提示合并在一起)比不使用系统提示或使用种子数据提示的效果更好,尽管在训练过程中没有看到合并提示。
总结
作者提出了一种可扩展的方法来微调大语言模型,使其能够遵循指令。该方法通过开发一种迭代式自训练算法(作者称之为“指令反向翻译”)来利用大量未标注数据。该方法利用模型本身来增强和策划高质量的训练示例,从而提高自身的性能。在 Alpaca 排行榜上,作者的微调模型优于所有其他非蒸馏指令遵循模型,同时使用了较少的人类标注示例。未来的工作应通过考虑更大的无标注语料库来进一步扩展这种方法,作者的分析表明这将产生更多的收益。