论文阅读:Self-Rewarding Language Models
作者认为,要实现超人 agents,未来的模型需要超人反馈,以提供足够的训练信号。目前的方法通常是根据人类的偏好来训练奖励模型,但这可能会受到人类水平的瓶颈制约。其次,这些单独冻结的奖励模型无法在 LLM 训练过程中学会改进。在这项工作中,作者研究的是自我奖励语言模型,即在训练过程中,语言模型本身通过 LLM 即 LLM-as-a-Judge 提示来提供自己的奖励。
研究表明,在迭代 DPO 训练过程中,不仅指令遵循能力得到了提高,而且为自身提供高质量奖励的能力也得到了提高。根据该方法对 Llama2-70B 进行三次迭代微调后,模型的性能超过了 AlpacaEval 2.0 排行榜上的许多现有系统,包括 Claude2、Gemini Pro 和 GPT-4 0613。虽然这只是一项初步研究,但这项工作为建立能在两个轴上不断改进的模型打开了一扇大门。
Self-Rewarding Language Models
该方法首先假定可以访问基础预训练语言模型和少量人类标注的种子数据。然后,建立一个旨在同时具备两种技能的模型:
- 指令遵循:给定一个描述用户请求的 prompt,能够生成高质量、有用无害的回复。
- 自我指令创建:能够根据示例生成和评估新指令,并将其添加到自己的训练集中。
利用这些技能,模型可以进行自我调整,即利用人工智能反馈(AIF)对自身进行迭代训练。
自我指令创建包括生成候选回复,然后由模型本身对其质量进行评判,也就是说,它充当了自己的奖励模型,取代了对外部模型的需求。这是通过 LLM-as-a-Judge 机制来实现的,即把对回答的评估制定为指令遵循任务。这种自创的 AIF 偏好数据被用作训练集。
整个自我调整程序是一个迭代程序,通过建立一系列这样的模型来进行,目的是每个模型都比上一个模型有所改进。重要的是,由于模型既能提高其生成能力,又能通过相同的生成机制充当自己的奖励模型,这意味着奖励模型本身也能通过这些迭代得到改进,这与奖励模型固定不变的标准做法不同。作者相信,这可以提高这些学习模型自我改进的潜力上限,消除制约瓶颈。
下面将详细介绍这些步骤,图 1 是该方法的概览。
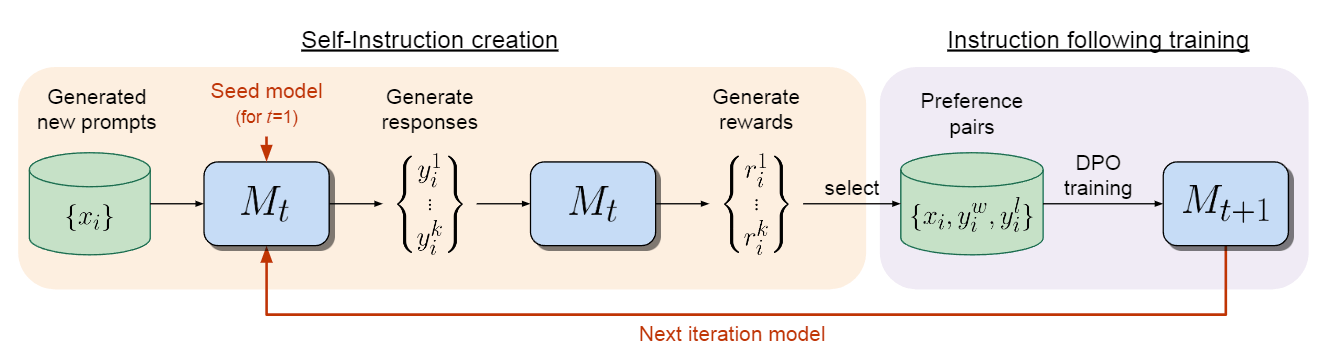
图 1:自我奖励语言模型。作者的自我对齐方法包括两个步骤:(i) 创建自我指导:新创建的 prompt 用于生成模型$M_t$的候选回答,模型$M_t$也会通过 LLM-as-a-Judge 提示预测自己的奖励。(ii) 训练后的指导:从生成的数据中选取偏好对,通过 DPO 进行训练,最终生成模型$M_{t+1}$。整个过程可以反复进行,从而提高指令遵循和奖励建模能力。
初始化
种子指令数据
我们会得到一组由人类撰写的(指令 prompt、回应)一般指令遵循示例的种子数据,我们将从预训练的基础语言模型开始,使用这些数据以监督微调(SFT)的方式对其进行训练。随后,这将被称为指令微调(Instruction Fine-Tuning,IFT)数据。
种子 LLM-as-a-Judge 指令数据
作者还假设提供了一组(评价指令 prompt、评价结果回应)种子示例,这些示例也可用于训练。虽然这并不是严格意义上的必要条件,因为使用 IFT 数据的模型已经能够训练 LLM-as-a-Judge,但我们证明这种这种训练数据可以改进结果。在该数据中,输入 prompt 要求模型对特定指令的给定反应进行质量评估。所提供的评价结果回复包括一连串的思维链推理(理由),然后是最终得分(在实验中,满分为 5 分)。

图 2:LLM-as-a-Judge 提示 LLM 充当奖励模型,并为自己的模型生成提供自我奖励。该模型最初使用种子训练数据进行训练,以了解如何在这项任务中表现出色,然后通过自我奖励训练程序进一步改进这项任务。
作者为这些 prompt 所选择的格式如图 2 所示。因此,这可以作为 LLM 的训练数据,让它扮演奖励模型的角色。随后,这些数据将被称为评估微调(EFT)数据。
在训练过程中同时使用这些种子设置。
自我指令创建
利用已经训练好的模型,可以让它自我修改训练集。具体来说,为下一次迭代训练生成额外的训练数据。这包括以下步骤:
- 生成新 prompt:按照 Wang 等人[2022] 和 Honovich 等人[2023] 的方法,从原始种子 IFT 数据中抽样生成新的 prompt$x_i$。
- 生成候选回复:使用抽样方法针对给定的 prompt$x_i$生成 N 个不同的候选回复 ${y_i^1, \ldots, y_i^N}$。
- 评估候选回答:利用同一模型的 LLM-as-a-Judge 能力来评估自己的候选回答,得分 $r_i^n \in [0, 5]$(见图 2)。
指令遵循训练
如前所述,训练最初使用种子 IFT 和 EFT 数据进行(第 2.1 节)。然后再通过人工智能(自我)反馈增加额外的数据。
AI 反馈训练
在完成自我指导创建程序后,就可以用额外的训练示例来增强种子数据,作者称之为人工智能反馈训练(AIFT)数据。作者尝试了这种反馈的两种变体:
- 偏好对:作者构建的训练数据格式为(指令 prompt $x_i$、获胜回复 $y_i^w$、失败回复 $y_i^l$)。为了形成胜负对,按照 Xu 等人[2023] 的方法,从 N 个已评估的候选回答(见第 2.2 节)中选取得分最高和最低的回答,如果得分相同,则舍弃这对回答。这些配对可用于偏好调整算法的训练。作者使用的是 DPO 算法。
- 仅正面示例:在这一变体中,将模型策划的(指令 prompt、响应)额外示例添加到种子集中,以进行监督微调,遵循其他方法而不是构建偏好数据。在此设置中,只添加候选回答被评估为满分 $r_i^n = 5$ 的示例。
虽然在实验中报告了两种方法的结果,但发现从偏好对中学习的效果更好,因此推荐使用这种方法。
整体自我对齐算法
迭代训练
整体程序会训练一系列模型 $M_1, \ldots, M_T$,其中每个连续的模型 t 都使用第 t - 1 个模型创建的增强训练数据。因此,作者将 AIFT($M_t$) 定义为使用模型$M_t$创建的人工智能反馈训练数据。
模型序列
因此,将这些模型及其使用的训练数据定义如下:
- $M_0$:基础预训练 LLM,不进行微调。
- $M_1$:使用$M_0$初始化,然后使用 SFT 在 IFT + EFT 种子数据上进行微调。
- $M_2$:使用$M_1$初始化,然后使用 DPO 在 AIFT($M_1$) 数据上进行训练。
- $M_3$:使用$M_2$初始化,然后使用 DPO 在 AIFT($M_2$) 数据上进行训练。
这种迭代训练类似于 Xu 等人[2023] 在成对边缘优化和迭代 DPO 中使用的程序;不过,该工作中使用的是外部固定奖励模型。
实验相关
评估指标
作者从两个方面来评估自我奖励模型的性能:它们遵循指令的能力和作为奖励模型的能力(评估回复的能力)。
指令遵循:使用 GPT-4 作为评估器,对来自不同来源的 256 个测试 prompt 进行各种模型之间的正面交锋性能评估,这与 Li 等人使用 AlpacaEval 评价 prompt 的做法一致。作者以两种顺序尝试该 prompt,并进行配对比较,如果 GPT-4 评估结果不一致,就将结果算作平局。还以 AlpacaEval 2.0 排行榜的形式报告结果,该排行榜对 805 个 prompt 进行评估,并根据 GPT-4 判断计算了与基线 GPT-4 Turbo 模型相比的胜率。
奖励建模:在 Open Assistant 数据集的评估集上评估了与人类排名的相关性。每条指令平均有 2.85 个具有给定排名的回复。因此,可以测量配对准确率,即模型评估与人类排名之间任何给定配对的排名顺序一致的次数。作者还测量了精确匹配计数,即指令总排序完全相同的频率。作者还报告了斯皮尔曼相关性和 Kendall’s τ。最后,报告了模型打出满分 5 分的回复被人类评为最高等级的频率。
训练细节
指令遵循训练
使用的训练超参数如下。
- SFT:使用学习率 5.5e-6(线性衰减至 1.1e-6)、batch size 为 16、dropout 为 0.1。只计算目标 token 的损失,而不是整个序列的损失。
- DPO:使用学习率 1e-6(线性衰减至 1e-7)、batch size 为 16、dropout 为 0.1、β 值为 0.1。
作者每 200 步保存一个检查点,使用 Claude 2 对来自不同来源的 253 个验证示例进行生成评估,按照 Li 等人的方法执行早停。使用 AlpacaEval 评估 prompt 格式对上一步的生成进行成对评估。
自我指令创建
为了生成新的 prompt,使用了一个固定的模型,即带有 8-shot prompt 的 Llama2-Chat-70B,而创建管道的其他部分(生成响应和评估响应)则使用了正在训练的模型。在生成候选回答时,抽取了 N = 4 个候选回答,温度 T = 0.7,top_p = 0.9。
在评估候选响应时,由于这些分数存在差异,作者在实验中还使用了采样解码(参数相同),并多次(3 次)生成这些评估,然后取平均值。通过 DPO 增加了 3964 对这样的偏好,形成 AIFT(M1) 数据集,用于训练 M2;增加了 6942 对这样的偏好,形成 AIFT(M2),用于训练 M3。
结果
指令遵循能力
图 3 显示了成绩对比结果。

图 3:通过自训练,指令遵循能力得到提升:使用 GPT-4 对多样化 prompt 进行逐对胜率评估。SFT 基线与自奖励第一迭代(M1)表现相当。然而,第二迭代(M2)优于第一迭代(M1)和 SFT 基线。第三迭代(M3)进一步超越第二迭代(M2),并且大幅度领先于 M1、M2 和 SFT 基线。
EFT + IFT 种子训练的表现与单独使用 IFT 相似
作者发现,与单独使用指令微调(IFT)数据相比,在训练中添加评估微调(EFT)任务并不会影响指令遵循性能,两者几乎不相上下(30.5% 的胜率 vs. 30.9% 的胜率)。这是一个积极的结果,因为这意味着模型自我奖励能力的提高不会影响其他技能。因此,可以将 IFT + EFT 训练作为自我奖励模型的迭代 1(M1),然后进行进一步的迭代。
第二次迭代(M2)相对于第一次迭代(M1)和 SFT 基线有了提升
自奖励训练的第二次迭代(M2)在指令跟随能力上优于第一次迭代(M1),在逐对评估中,M2 的胜率为 55.5%,而 M1 仅为 11.7%。相对于 SFT 基线,M2 也有类似的提升(49.2% 的胜率对比 14.5% 的胜率)。显然,通过使用第一次迭代的奖励模型提供的偏好数据 AIFT(M1),从 M1 到 M2 的性能有了显著提升。
第三次迭代(M3)相对于第二次迭代(M2)有所提升
在第三次迭代(M3)中相对于第二次迭代(M2)看到了进一步的提升,在逐对评估中,M3 的胜率为 47.7%,而 M2 仅为 12.5%。类似地,M3 相对于 SFT 基线的胜率增加到了 62.5%,而 M2 为 9.8%,也就是说,M3 模型的胜率高于 M2 模型。总体而言,通过使用第二次迭代的奖励模型提供的偏好数据 AIFT(M2) 进行训练,从 M2 到 M3 取得了显著的提升。
奖励建模能力
奖励建模评价结果如表2所示。
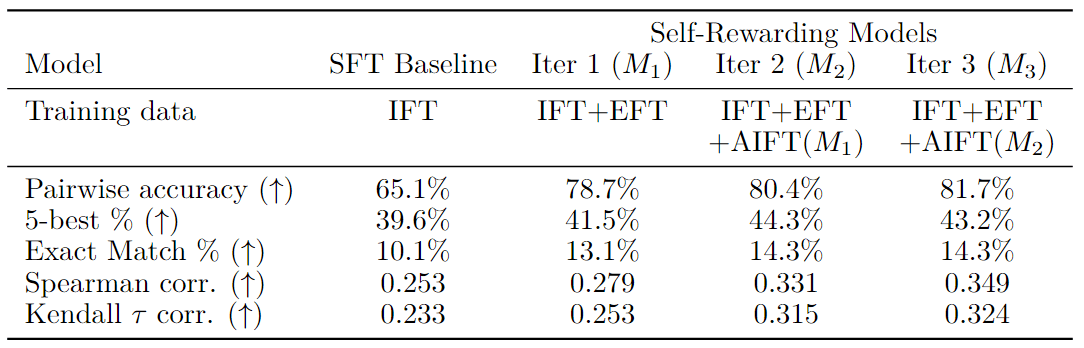
表 2:通过自训练,奖励建模能力得到提升:通过各种指标评估作为裁判的大语言模型(LLM-as-a-Judge),这些指标衡量模型与保留的人类偏好数据的一致性。使用从上一迭代M1中派生的自奖励模型训练的自奖励迭代2(模型M2)优于迭代1(M1),而M1本身则优于仅使用指令微调(IFT)数据训练的标准SFT基线模型。迭代3(模型M3)相较于迭代2进一步提升了性能。
EFT 增强提升 SFT 基线
首先,作者发现将评估微调(EFT)数据加入训练中,为模型提供了如何作为一个大语言模型裁判(LLM-as-a-Judge)进行操作的示例,这自然比仅使用指令微调(IFT)数据进行训练提升了性能。IFT 数据涵盖了广泛的通用指令任务,因此赋予了监督微调(SFT)基线评估响应的能力,但 EFT 数据提供了更多关于这一特定任务的示例。我们发现使用 IFT + EFT 数据与仅使用 IFT 数据相比,在所有五个测量指标上都有所提升,例如,与人类的成对准确性一致性从 65.1% 提高到了 78.7%。
奖励建模能力随着自训练而提高
进行一轮自奖励训练不仅提高了模型的指令遵循能力,还增强了模型在下一迭代中提供自奖励的能力。
- 模型M2(迭代2)使用来自M1(迭代1)的奖励模型进行训练,但在所有五个指标上都比M1表现得更好。例如,成对准确率从78.7%提高到80.4%。
- 迭代3(M3)在多个指标上相比M2进一步提升,例如成对准确率从80.4%提高到81.7%。尽管没有提供额外的EFT数据,而且在自指令创建循环中生成的示例通常不像LLM-as-a-Judge训练示例,但这一性能提升仍然得以实现。
作者假设,由于模型在总体指令遵循能力上变得更好,它在LLM-as-a-Judge任务上的表现也随之提升。
LLM-as-a-Judge 提示的重要性
在这些实验中,作者使用了图 2 中展示的 LLM-as-Judge 提示格式。在初步实验中,还尝试了各种其他提示,以决定最有效的提示。例如,尝试了Li等人 [2023a] 提出的提示,该提示也使用了 5 分制,但将选项描述为一系列质量等级的多项选择,如图 5 所示。

图 5:来自 Li 等人 [2023]a 中的 LLM-as-a-Judge 提示。
相较之下,作者的提示将评分描述为累加的,涵盖了质量的各个方面。在使用SFT基线时,这两种提示之间存在很大差异,例如,作者 prompt 的成对准确率为65.1%,而 Li 等人的成对准确率只有26.6%。
总结
作者引入了自我奖励语言模型(Self-Rewarding Language Models),这种模型能够通过判断和训练自己的版本进行自我调整。该方法采用迭代方式进行训练,在每次迭代中,模型都会创建自己的基于偏好的指令训练数据。具体做法是通过 LLM-as-a-Judge 提示为自己的后代分配奖励,并使用迭代 DPO 对偏好进行训练。
研究表明,这种训练既提高了模型的指令跟踪能力,也提高了它在整个迭代过程中的奖励建模能力。虽然这只是一项初步研究,但作者认为这是一个令人兴奋的研究方向,因为这意味着该模型能够在未来的迭代中更好地分配奖励,以改善指令遵循——这是一种良性循环。虽然这种改进在现实场景中可能会达到饱和,但仍有可能不断改进,超越目前通常用于建立奖励模型和指令跟踪模型的人类偏好。