资料搜集:emerging architectures for llm applications
这篇文章翻译自 https://a16z.com/emerging-architectures-for-llm-applications/,学习如何搭建一套完整的 LLM App,将其应用至当前负责的 RAG 项目中。
大型语言模型是构建软件的强大新工具。但由于它们是如此之新,而且行为方式与普通计算资源大相径庭,因此如何使用它们并不总是显而易见的。
在这篇文章中,我们将分享新兴 LLM 应用程序栈的参考架构。它展示了我们所见过的人工智能初创公司和尖端科技公司所使用的最常见的系统、工具和设计模式。这个堆栈仍处于早期阶段,可能会随着底层技术的发展而发生重大变化,但我们希望它能为现在使用 LLM 的开发人员提供有用的参考。
这项工作基于与人工智能初创公司创始人和工程师的对话。我们特别依赖以下人士提供的意见:Ted Benson、Harrison Chase、Ben Firshman、Ali Ghodsi、Raza Habib、Andrej Karpathy、Greg Kogan、Jerry Liu、Moin Nadeem、Diego Oppenheimer、Shreya Rajpal、Ion Stoica、Dennis Xu、Matei Zaharia 和 Jared Zoneraich。感谢您的帮助!

设计模式:上下文学习
上下文学习的核心理念是使用现成的 LLM(即无需任何微调),然后通过巧妙的提示和私人“上下文”数据条件来控制它们的行为。例如,假设您正在构建一个聊天机器人,以回答有关一组法律文件的问题。如果采用天真的方法,您可以将所有文件粘贴到 ChatGPT 或 GPT-4 提示符中,然后在最后提出一个关于这些文件的问题。这可能适用于很小的数据集,但无法扩展。最大的 GPT-4 模型只能处理约 50 页的输入文本,当接近这个极限(即上下文窗口)时,性能(以推理时间和准确性衡量)会严重下降。
上下文学习通过一个巧妙的技巧解决了这一问题:它不是在每次 LLM 提示时发送所有文档,而是只发送少量最相关的文档。而最相关的文档是在 LLM 的帮助下确定的。
工作流程大致可分为三个阶段:
- 数据预处理/嵌入:这一阶段涉及存储私人数据(在我们的例子中是法律文件),以便日后检索。通常情况下,文件会被分割成块,通过嵌入模型,然后存储在一个名为向量数据库的专门数据库中。
- 提示构建/检索:当用户提交查询(本例中为法律问题)时,应用程序会构建一系列提示,并提交给语言模型。编译后的提示通常包含开发人员硬编码的提示模板、被称为“few-shot”的有效输出示例、从外部应用程序接口获取的任何必要信息,以及从向量数据库获取的相关文档集。
- 提示执行/推理:提示编译完成后,将提交给预先训练好的 LLM 进行推理——包括专有模型 API 和开源或自我训练的模型。有些开发人员还会在此阶段添加日志、缓存和验证等操作系统。
这看起来工作量很大,但通常比训练或微调 LLM 本身要容易得多,不需要一个专门的 ML 工程师团队来进行上下文学习,也不需要托管自己的基础设施或从 OpenAI 购买昂贵的专用实例。这种模式有效地将人工智能问题简化为数据工程问题,而大多数初创企业和大公司都已经知道如何解决这个问题。对于相对较小的数据集来说,它的效果也往往优于微调——因为在 LLM 通过微调记住某个特定信息之前,该信息至少需要在训练集中出现 10 次以上,而且它可以近乎实时地纳入新数据。
围绕上下文学习的最大问题之一是:如果我们改变底层模型,增加上下文窗口,会发生什么?这确实是可能的,而且是一个活跃的研究领域(例如,参见 Hyena 论文或最近的 post)。但是,这需要权衡一些因素——主要是推理的成本和时间与 prompt 的长度成二次方关系。如今,即使是线性扩展(理论上的最佳结果)对于许多应用来说也是成本高昂的。
如果你想更深入地了解上下文学习,人工智能大典中有很多不错的资源(尤其是 “使用 LLM 构建的实用指南 “部分)。在本篇文章的剩余部分,我们将以上述工作流程为指导,介绍参考堆栈。
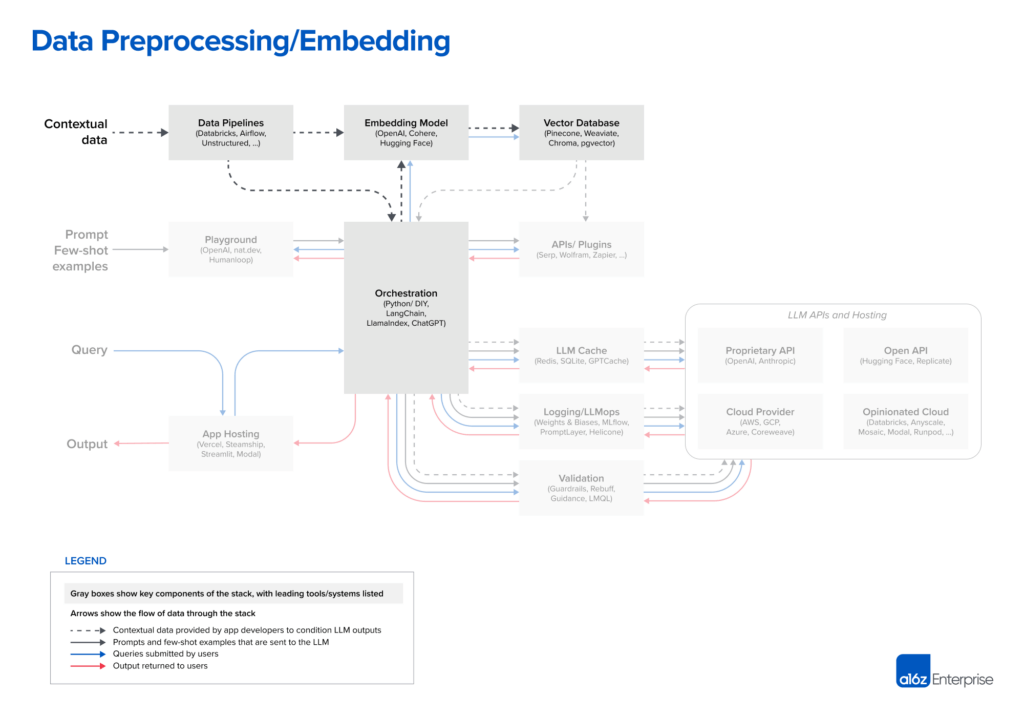
上下文数据:LLM 应用程序的上下文数据包括文本文档、PDF 甚至 CSV 或 SQL 表格等结构化格式。与我们交谈过的开发人员中,针对这些数据的数据加载和转换解决方案大相径庭。大多数人使用传统的 ETL 工具,如 Databricks 或 Airflow。有些人还使用 LangChain(由 Unstructured 提供支持)和 LlamaIndex(由 Llama Hub 提供支持)等协调框架中内置的文档加载器。不过,我们认为这部分堆栈的开发还相对不足,专门为 LLM 应用程序设计的数据复制解决方案大有可为。
嵌入:大多数开发者都使用 OpenAI API,特别是 text-embedding-ada-002 模型。它易于使用(尤其是如果您已经在使用其他 OpenAI API),结果相当不错,而且价格越来越便宜。一些大型企业也在探索 Cohere,该公司的产品更专注于嵌入,在某些场景下性能更好。对于喜欢开源的开发者来说,来自 Hugging Face 的 Sentence Transformers 库是一个标准库。此外,还可以针对不同的用例创建不同类型的嵌入式;这在今天还只是一种小众做法,但却是一个前景广阔的研究领域。
从系统角度来看,预处理管道中最重要的部分是向量数据库。它负责高效地存储、比较和检索多达数十亿的嵌入(即向量)。我们在市场上最常见的选择是 Pinecone。之所以选择 Pinecone,是因为它是完全云托管的,因此很容易上手,而且具有许多大型企业在生产中需要的功能(例如,良好的规模性能、SSO 和正常运行时间 SLA)。
另一个悬而未决的问题是,随着大多数模型可用上下文窗口的增加,嵌入和向量数据库将如何发展。我们很容易说嵌入将变得不那么重要,因为上下文数据可以直接投放到提示中。然而,专家们对这一问题的反馈恰恰相反,随着时间的推移,嵌入管道可能会变得更加重要。大型上下文窗口是一种功能强大的工具,但同时也需要大量的计算成本。因此,有效利用它们成为当务之急。我们可能会开始看到不同类型的嵌入模型开始流行起来,这些模型可以直接针对模型相关性进行训练,而向量数据库的设计则是为了实现并利用这一点。
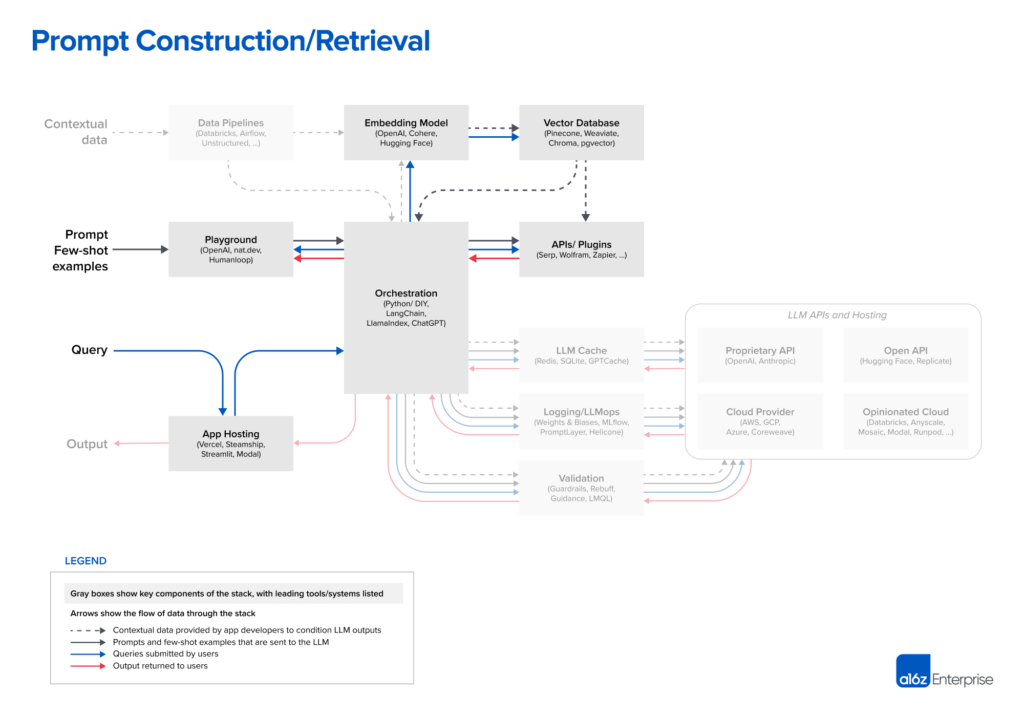
prompt LLM 和整合上下文数据的策略正变得越来越复杂,而且作为产品差异化的一个来源也越来越重要。大多数开发人员在开始新项目时都会尝试使用简单的 prompt,包括直接指令(zero-shot prompt)或一些示例输出(few-shot prompt)。这些 prompt 通常会带来不错的效果,但却达不到生产部署所需的准确度水平。
下一阶段的 prompt 柔术旨在将模型响应建立在某些真实来源的基础上,并提供模型未经过训练的外部上下文。《Prompt Engineering Guide》收录了不少于 12 种更高级的 prompt 策略,包括思维链、自我一致性、生成知识、思维树、定向刺激等。这些策略还可以结合使用,以支持不同的 LLM 用例,如文档问题解答、聊天机器人等。
这正是 LangChain 和 LlamaIndex 等协调框架的优势所在。它们抽象掉了提示链、与外部 API 的接口(包括确定何时需要调用 API)、从向量数据库检索上下文数据以及在多个 LLM 调用中维护内存的许多细节。它们还为上述许多常见应用提供了模板。它们的输出是提交给语言模型的提示或一系列 prompt。这些框架在业余爱好者和初创公司中被广泛使用,它们都希望能将应用落地,而 LangChain 就是其中的佼佼者。

当项目投入生产并开始扩展时,一系列更广泛的选择就会发挥作用。我们听到的一些常见选择包括:
- 改进 gpt-3.5-turbo:它比 GPT-4 便宜约 50 倍,速度也快得多。许多应用程序并不需要 GPT-4 级别的精确度,但需要低延迟推断和对免费用户的高性价比支持。
- 尝试使用其他专有供应商(尤其是 Anthropic 的 Claude 模型):Claude 可提供快速推理、GPT-3.5 级精度、针对大型客户的更多定制选项以及高达 100k 的上下文窗口(不过我们发现精度会随着输入长度的增加而降低)。
- 将一些请求分流到开源模型:这在搜索或聊天等大流量 B2C 用例中尤为有效,因为在这些用例中,查询复杂度差异很大,而且需要以低廉的价格为免费用户提供服务。
- 这通常与微调开源基础模型结合使用最有意义。在本文中,我们不会深入讨论工具堆栈,但越来越多的工程团队都在使用 Databricks、Anyscale、Mosaic、Modal 和 RunPod 等平台。
- 开源模型有多种推理选择,包括来自 Hugging Face 和 Replicate 的简单 API 接口;来自主要云提供商的原始计算资源;以及像上面列出的那些更有主见的云产品。
与我们交谈过的大多数开发人员还没有深入研究过 LLM 的操作工具。缓存相对常见,通常基于 Redis,因为它能提高应用响应时间和成本。Weights & Biases 和 MLflow(从传统机器学习移植而来)或 PromptLayer 和 Helicone(专为 LLM 设计)等工具的使用也相当广泛。它们可以记录、跟踪和评估 LLM 输出,通常用于改进提示构建、调整管道或选择模型。此外,还有一些新工具正在开发中,用于验证 LLM 输出(如 Guardrails)或检测 prompt 注入攻击(如 Rebuff)。这些操作工具大多鼓励使用自己的 Python 客户端来调用 LLM,因此,随着时间的推移,这些解决方案如何共存将是一个有趣的话题。
当(而不是如果)开源 LLM 达到与 GPT-3.5 相媲美的准确度水平时,我们有望看到一个类似于文本稳定扩散的时刻——包括大量实验、共享和生产微调模型。像 Replicate 这样的托管公司已经开始添加工具,使软件开发人员更容易使用这些模型。越来越多的开发人员相信,经过微调的小型模型可以在狭窄的使用案例中达到最先进的精确度。
与我们交谈过的大多数开发人员还没有深入研究过 LLM 的操作工具。缓存相对常见,通常基于 Redis,因为它能提高应用程序的响应时间和成本。Weights & Biases 和 MLflow(从传统机器学习移植而来)或 PromptLayer 和 Helicone(专为 LLM 设计)等工具的使用也相当广泛。它们可以记录、跟踪和评估 LLM 输出,通常用于改进提示构建、调整管道或选择模型。此外,还有一些新工具正在开发中,用于验证 LLM 输出(如 Guardrails)或检测 prompt 注入攻击(如 Rebuff)。这些操作工具大多鼓励使用自己的 Python 客户端来调用 LLM,因此,随着时间的推移,这些解决方案如何共存将是一个有趣的话题。
最后,LLM 应用程序的静态部分(即模型以外的所有内容)也需要托管在某个地方。迄今为止,我们看到的最常见的解决方案都是标准选项,如 Vercel 或主要的云提供商。不过,有两类新的解决方案正在出现。Steamship 等初创公司为 LLM 应用程序提供端到端的托管服务,包括协调(LangChain)、多租户数据上下文、异步任务、向量存储和密钥管理。Anyscale 和 Modal 等公司则允许开发人员在一个地方托管模型和 Python 代码。
What about agents?
这个参考架构中最重要的组成部分就是人工智能代理框架。AutoGPT 被描述为“让 GPT-4 完全自主的实验性开源尝试”,它是今年春季 Github 上增长最快的软件仓库,如今几乎所有的人工智能项目或初创公司都包含某种形式的代理。
与我们交谈过的大多数开发人员都对代理的潜力感到无比兴奋。为了更好地支持内容生成任务,我们在这篇文章中描述的上下文学习模式可以有效解决幻觉和数据新鲜度问题。另一方面,代理为人工智能应用提供了一系列全新的能力:解决复杂问题、对外界采取行动,以及在部署后从经验中学习。它们通过先进的推理/规划、工具使用和记忆/递归/自我反思等组合来实现这一点。
因此,代理有可能成为 LLM 应用程序架构的核心部分(如果你相信递归自我完善,甚至可以接管整个堆栈)。现有的框架(如 LangChain)已经融入了一些代理概念。只有一个问题:代理还不能真正发挥作用。目前,大多数代理框架都处于概念验证阶段,能够提供令人难以置信的演示,但还不能可靠、可重复地完成任务。我们将密切关注它们在不久的将来如何发展。



