AWS SageMaker 推理方案
总体而言,LLM 的生成推理有三大挑战(根据 Pope 等人 2022 年的研究):
- 由于大模型参数和解码过程中的瞬态,需要占用大量内存。这些参数往往超过单个加速器芯片的内存。注意 kv cache 也需要大量内存。
- 低并行性会增加延迟,尤其是在内存占用较大的情况下,每一步都需要大量数据传输来将参数和缓存加载到计算核心中。这就导致需要很高的总内存带宽来满足延迟目标。
- 相对于序列长度,注意力机制计算的二次方加剧了延迟和计算挑战。
批处理是应对这些挑战的技术之一。批处理是指将多个输入序列一起发送到 LLM,从而优化 LLM 推理性能的过程。这种方法有助于提高吞吐量,因为不需要为每个输入序列加载模型参数。参数可以一次性加载,并用于处理多个输入序列。批处理有效利用了加速器的 HBM 带宽,从而提高了计算利用率,改善了吞吐量,并实现了经济高效的推理。
这篇文章探讨了如何利用批处理技术最大限度地提高 LLM 中并行化生成推理的吞吐量。作者讨论了不同的批处理方法,以减少内存占用,提高并行性,并缓解注意力的二次方,从而提高吞吐量。目标是充分利用 HBM 和加速器等硬件来克服内存、I/O 和计算方面的瓶颈。
LLMs 模型服务
LLM 的模型服务是指接收文本生成输入请求、进行推理并将结果返回给请求应用程序的过程。以下是模型服务涉及的关键概念:
- 客户端生成多个推理请求,每个请求由一系列 token 或输入 prompt 组成。
- 推理服务器(例如 DJLServing、TorchServer、Triton 或 HuggingFace TGI)接收请求。
- 推理服务器对推理请求进行批处理,并将批处理调度到包含模型分区库(如 Transformers-NeuronX、DeepSpeed、Accelerate 或 FasterTransformer)的执行引擎,以便在生成式语言模型上运行前向传递(预测输出 token 序列)。
- 执行引擎生成响应 token 并将响应发回推理服务器。
- 推理服务器将生成的结果回复给客户端。

当推理服务器在请求级与执行引擎交互时,请求级调度就会面临挑战,例如每个请求都使用一个 Python 进程,这就需要一个单独的模型副本,而这对内存是有限制的。例如,如下图所示,在加速器设备内存总量为 96GB 的机器学习实例上,只能加载大小为 80G 的模型的单个副本。如果要并发服务更多请求,则需要加载整个模型的额外副本。这样既不节省内存,也不节约成本。

既然已经了解了请求级调度所带来的挑战,那么让我们来看看有助于优化吞吐量的不同批处理技术。
批处理技术
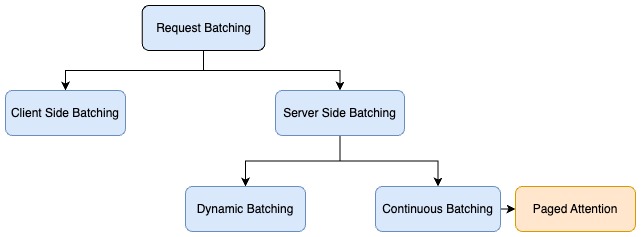
推理请求的批处理主要有两种类型:
- 客户端(静态):通常情况下,当客户端向服务器发送请求时,服务器会默认按顺序处理每个请求,这对吞吐量来说并不是最佳选择。为了优化吞吐量,客户端会在单个有效载荷中批量处理推理请求,服务器则会实施预处理逻辑,将批量请求分解为多个请求,并分别运行每个请求的推理。在此方案中,客户端需要修改代码进行批处理,而且解决方案与批处理规模紧密相关。
- 服务端(动态):当独立的推理请求到达服务器时,推理服务器可在服务器端动态地将它们分组为更大的批次。推理服务器可以管理批处理,以满足指定的延迟目标,最大限度地提高吞吐量,同时保持在所需的延迟范围内。推理服务器会自动处理,因此无需更改客户端代码。服务器端批处理包括不同的技术,以进一步优化基于自动回归解码的生成语言模型的吞吐量。这些批处理技术包括动态批处理、连续批处理和 PagedAttention (vLLM) 批处理。
动态批处理
动态批处理指的是将输入请求合并在一起,作为一个批处理发送给推理。动态批处理是一种通用的服务器端批处理技术,适用于所有任务。通常需要设定两个参数:
batch_size:批处理的大小。max_batch_delay:批次聚合的最大延迟时间。
如果满足上述任一阈值(达到最大批次或等待期结束),则会准备一个新的批次并推送给模型进行推理。下图显示了模型对不同输入序列长度的请求进行动态批处理的情况。
动态批处理的过程类似于缓冲区的做法,也类似于心辰服务框架的 Redis 消息队列的缓冲写入。

虽然动态批处理与无批处理相比,吞吐量最多可提高 4 倍,但作者发现在这种情况下 GPU 的利用率并不理想,因为在所有请求处理完毕之前,系统无法接受另一个批处理。
连续批处理
连续批处理是针对文本生成的一种优化。它提高了吞吐量,而且不会牺牲到第一个字节的延迟时间。连续批处理(也称为迭代批处理或滚动批处理)解决了 GPU 空闲时间的难题,并在动态批处理方法的基础上,进一步通过在批处理中不断推送新的请求来实现。下图显示了请求的连续批处理。当请求 2 和请求 3 处理完毕后,会调度另一组请求。

下面的交互式图表深入介绍了连续批处理的工作原理。

可以使用一种强大的技术来提高 LLM 和文本生成的效率:缓存部分注意力矩阵。这意味着 prompt 的第一次传递不同于后续的前向传递。第一次 prompt 时,需要计算整个注意力矩阵,而后续 prompt 只需要计算新 token 的注意力。在整个代码库中,第一遍被称为预填充,而后续则被称为解码。由于预填充比解码昂贵得多,作者并不希望一直进行预填充,但当前运行的查询可能正在进行解码。如果想使用连续批处理,就需要在某个时刻运行预填充,以便创建所需的注意力矩阵,从而能够加入解码组。
通过有效利用闲置的 GPU,该技术可将吞吐量提高到无批处理时的 20 倍。
PagedAttention 批处理
在自回归解码过程中,LLM 的所有输入 token 都会产生其注意力 key 和 value 张量,这些张量被保存在 GPU 内存中,以生成下一个 token。这些缓存的 key 和 value 张量通常被称为 KV cache 或注意力缓存。根据论文《vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention》,在 Llama 13B 中,单个序列的 KV cache 最多需要 1.7 GB。它也是动态的,其大小取决于序列长度,而序列长度是高度可变和不可预测的。因此,有效管理 KV cache 是一项重大挑战。论文发现,由于碎片化和过度保留,现有系统浪费了 60-80% 的内存。
PagedAttention 是加州大学伯克利分校开发的一种新优化算法,它通过以固定大小的页或块分配内存,允许注意力缓存(KV cache)不连续,从而改进了连续批处理过程。其灵感来自操作系统使用的虚拟内存和分页概念。
根据 vLLM 论文,每个 token 序列的注意力缓存都被划分成块,并通过块表映射到物理块。在计算注意力期间,分页注意力内核可以使用块表从物理内存中高效获取块。这大大减少了内存浪费,允许更大的批次大小、更高的 GPU 利用率和更高的吞吐量。下图说明了如何将注意力缓存划分为非连续页面。

下图显示了一个使用 PagedAttention 的推理示例。主要步骤如下
- 通过输入 prompt 接收推理请求。
- 在预填充阶段,计算注意力,将键值存储在非连续的物理内存中,并映射到逻辑键值块。这种映射存储在一个块表中。
- 输入 prompt 通过模型运行(前向传递),生成第一个响应 token。在生成响应 token 期间,会使用预填充阶段的注意力缓存。
- 在后续 token 生成过程中,如果当前物理块已满,则会以非连续方式分配额外内存,从而实现及时分配。
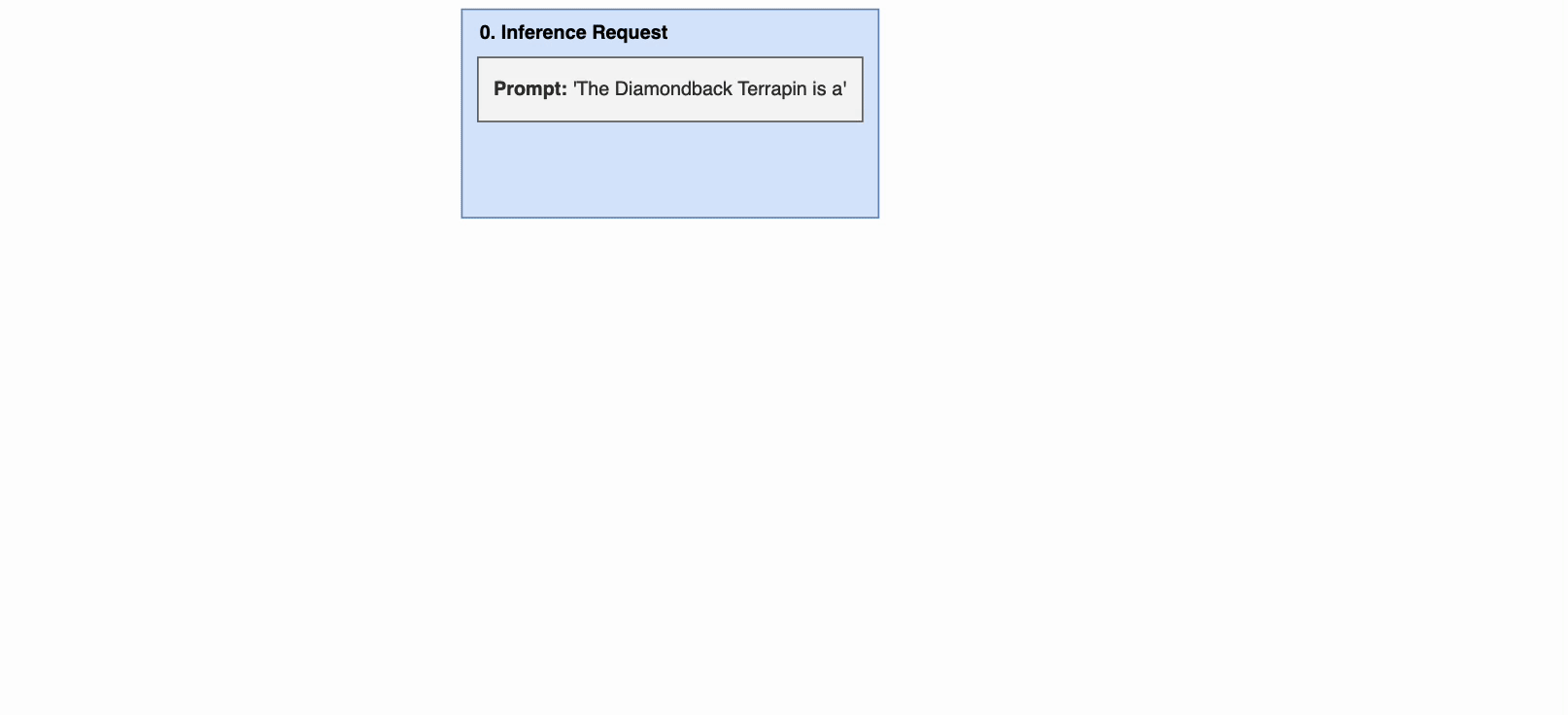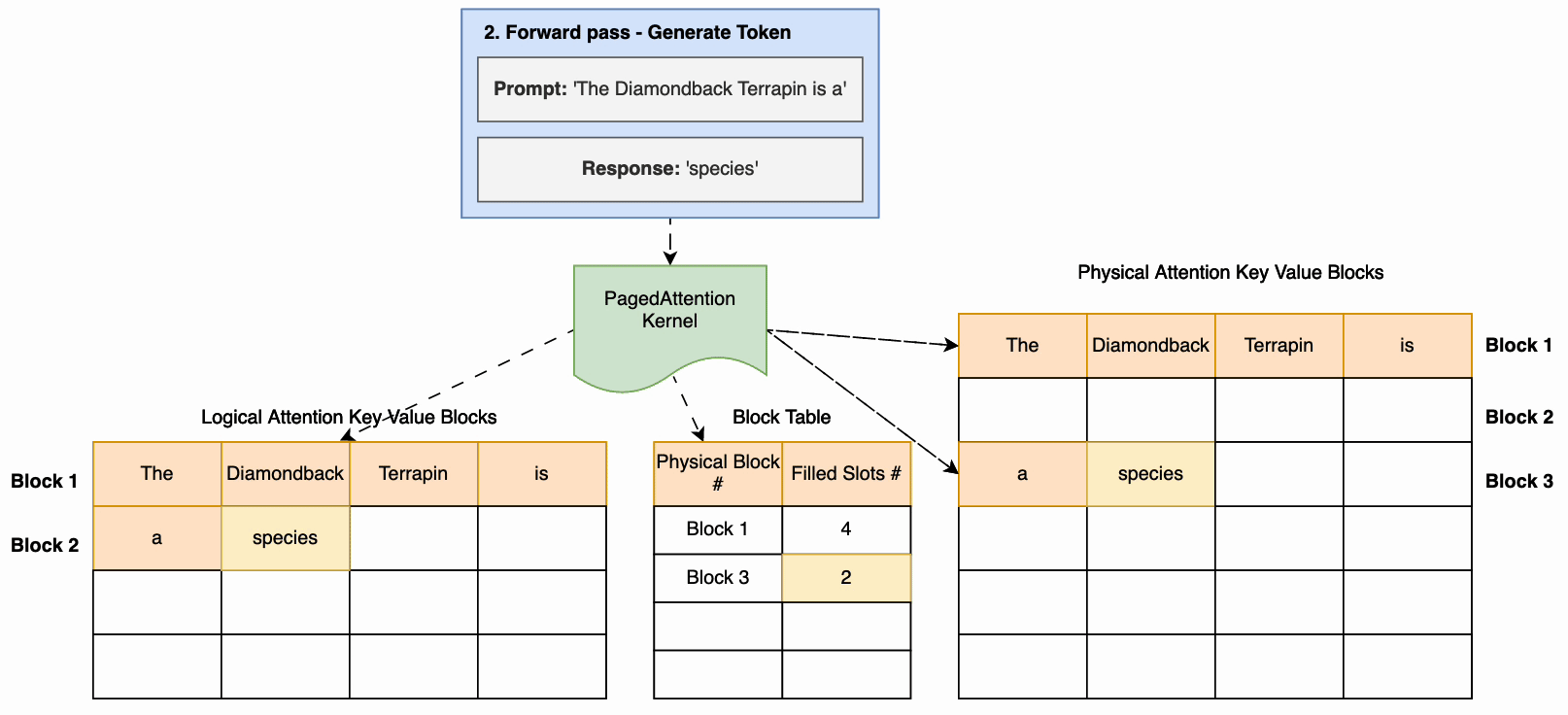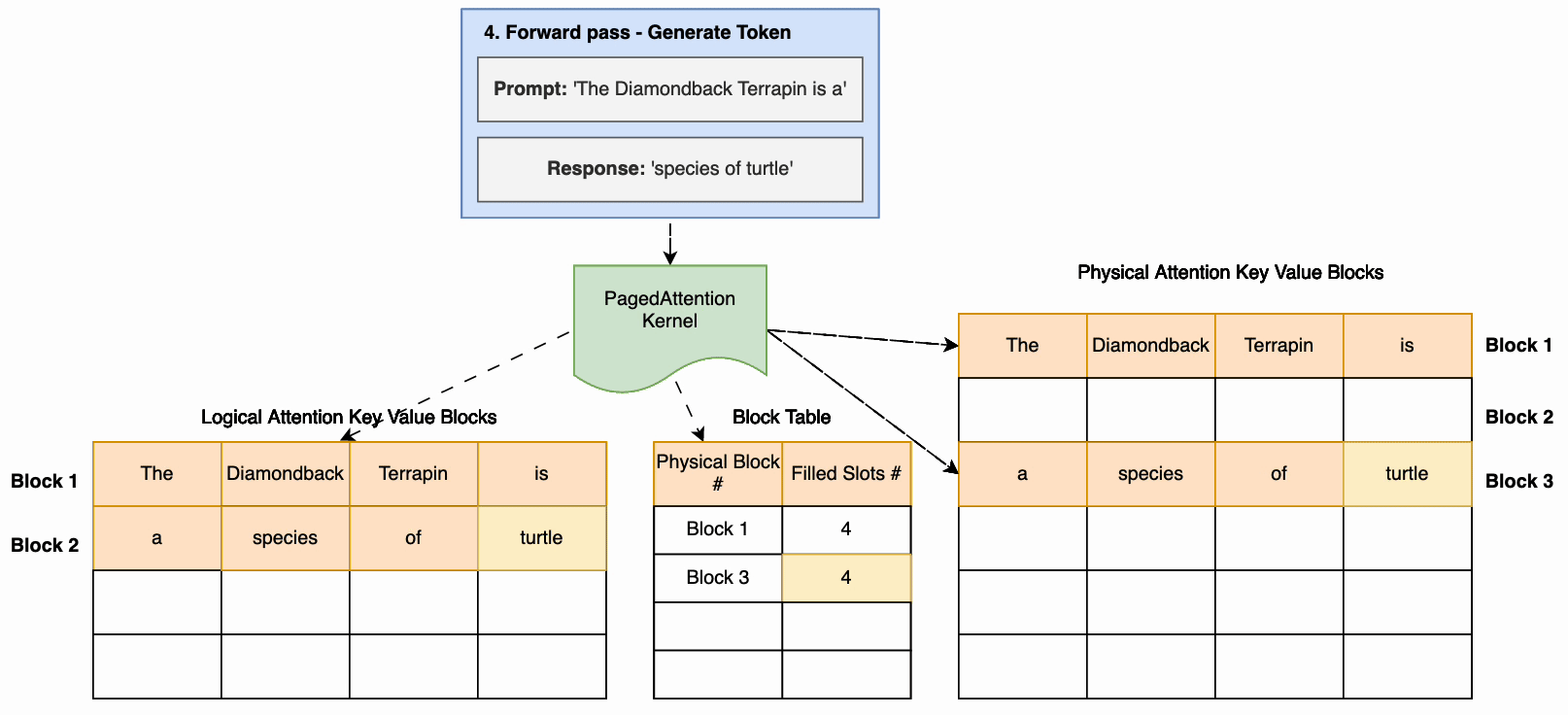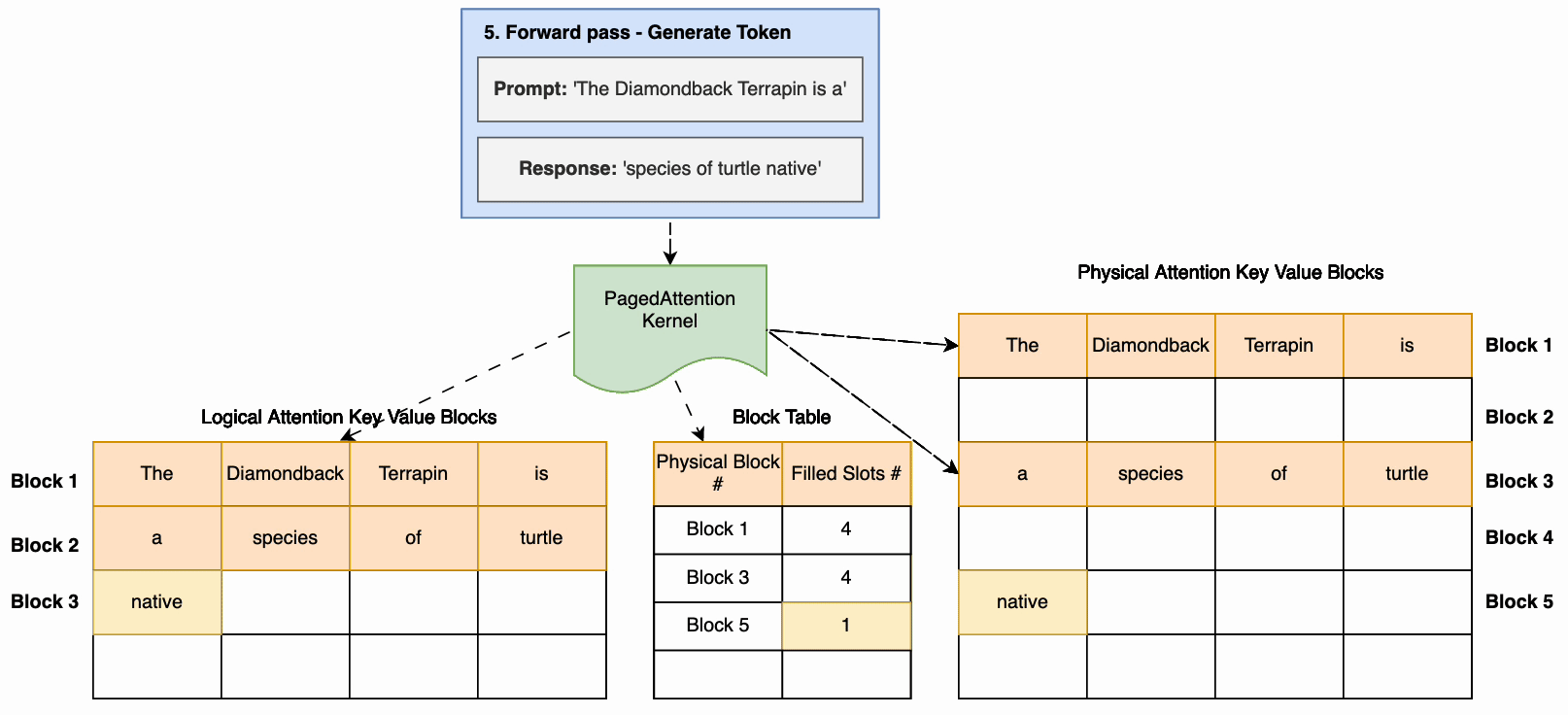
PagedAttention 有助于接近最佳的内存使用,减少内存浪费。这样可以将更多请求分批处理,从而显著提高推理的吞吐量。
何时使用批处理技术
下表总结了不同的批处理技术及其使用案例。
| 批处理策略 | 如何工作 | 何时工作最好 |
|---|---|---|
| PagedAttention 批处理 | 总是在 token 级别合并新请求和分页区块,并进行批量推理 | 这是仅支持解码器模型的推荐方法。适用于吞吐量优化的工作负载。仅适用于文本生成模型 |
| 连续批处理 | 总是在 token 级别合并新请求并进行批量推理 | 以相同的解码策略处理不同时间的并发请求。适用于吞吐量优化的工作负载。仅适用于文本生成模型 |
| 动态批处理 | 在请求级别合并新请求;可延迟几毫秒形成批处理 | 以相同的解码策略处理不同时间的并发请求。它适用于需要较高吞吐量的响应时间敏感型工作负载。它适用于 CV、NLP 和其他类型的模型 |
| 客户端批处理 | 客户端负责在将多个推理请求发送到推理服务器之前,在同一有效负载中对其进行批处理 | 它适用于离线推理使用案例,这些案例没有最大化吞吐量的延迟限制 |
| 无批处理 | 当请求到达时,立即运行推理 | 不频繁的推理请求或采用不同解码策略的推理请求。它适用于对响应时间延迟有严格要求的工作负载 |
SageMaker 上大型生成模型不同批处理技术的吞吐量比较
作者在 SageMaker 上使用 LMI 容器和本文讨论的不同批处理技术对 Llama v2 7B 模型进行了性能基准测试,并发传入请求为 50 个,请求总数为 5,000 个。
在性能测试中,使用了三种不同长度的输入 prompt。在连续批处理和 PagedAttention 批处理中,三个输入 prompt 的输出 token 长度分别设置为 64、128 和 256。在动态批处理中,使用了一致的 128 个输出 token 长度。下表列出了性能基准测试的结果。
测试环境:实例类型为 ml.g5.24xlarge 的 SageMaker 端点。
| 模型名称 | 批处理策略 | RPS |
|---|---|---|
| LLaMA2-7b | 动态批处理 | 3.24 |
| LLaMA2-7b | 连续批处理 | 6.92 |
| LLaMA2-7b | PagedAttention 批处理 | 7.41 |
总结
在这篇文章中,作者解释了用于 LLMs 推断的不同批处理技术,以及它如何帮助提高吞吐量。展示了内存优化技术如何通过使用连续分批和 PagedAttention 分批来提高硬件效率,并提供比动态分批更高的吞吐量值。



