Alibaba at IJCNLP-2017 Task 1
- 发布时间:2017
- 论文作者:阿里巴巴 NLP 团队
本篇论文介绍阿里巴巴 NLP 团队在 IJCNLP 2017 任务 No. 1 中文语法错误诊断(CGED)的做法。任务是诊断四种语法错误,即冗余词语(R)、缺失词语(M)、错误词语(S)和乱序词语(W)。作者将该任务视作序列标注问题,并设计了一些手工特征来解决这个问题。作者的系统主要基于 LSTM-CRF 模型,并应用 3 种集成策略来提高性能。
1. 介绍
CGED 任务为中国 NLP 研究人员提供了构建和开发中文语法错误诊断系统,比较其结果并交流学习方法的机会。本篇论文的组织结构如下:
- 第 2 节:介绍了任务的细节;
- 第 3 节:介绍了一些相关的中英文著作;
- 第 4 节:介绍了作者提出的方法,包括特征生成、模型架构和集成策略。
- 第 5 节:显示评估数据集上的数据分析和最终结果;
- 第 6 节:总结并展望了未来的工作。
2. 中文语法错误诊断
NLPTea CGED 自 2014 年以来一直举办,它提供了几套由中文外语学习者编写的训练数据。在这些训练数据集中,已标记了 4 种 错误:
- R:冗余词语;
- S:错误词语;
- M:缺失词语;
- W:乱序词语。
利用提供的测试数据集来开发一种自动的中文语法错误诊断系统来检测:
- 句子正确与否;
- 若有错误,则是什么类型的错误;
- 确切的错误位置。
需要特别注意的一件事是,每个句子可能包含多个错误。一些典型示例如表 1 所示。

在测试结果中测量这些指标:误报率、准确率、精确率、召回率和 F1。
4. 方法
4.1 模型描述
与 2016 年大多数团队的方法相同,作者将 CGED 问题视为序列标注问题。具体而言,给定句子 X,使用 BIO 编码生成相应的标签序列 Y。HIT 团队使用传统的 CRF 模型和基于 LSTM 的模型来解决序列标注问题。这两种模型可以直接结合起来,产生了一个新的模型 LSTM-CRF。在 CRF 模型的帮助下,LSTM-CRF 模型可以更好地预测序列的标记。例如,与单个 LSTM 模型相比,LSTM-CRF 模型可以避免预测“I-X”错误。
与 HIT 团队一样,作者使用双向 LSTM 作为 RNN 单元对输入序列进行建模,模型架构如图 1 所示。
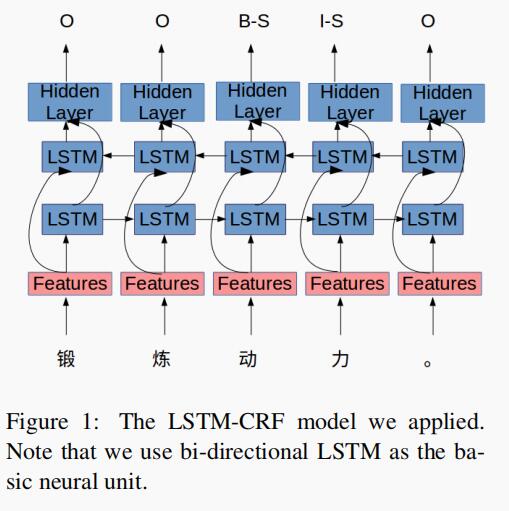
从图中可以看出,这些特征不是体系结构中特定的,我们将在下一节中进行说明。
4.2 特征工程
由于缺少训练数据,因此任务很大程度上取决于外部数据或领域专家提供的先验知识,例如 POS 特征等等。
换句话说,特征工程在此任务中非常重要,作者设计了几个特征,图 2 介绍了使用的特征。
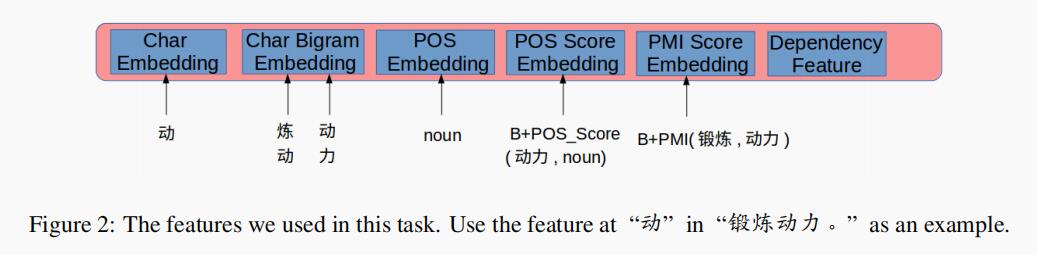
下面分别介绍每个特征:
- Char:作者随机初始 char 嵌入作为输入的特征之一。
- Char Bigram:Bigram 是此任务中提供信息和区分特征的特征,因为它使模型易于了解相邻字符之间的搭配程度。
- POS:包含动词、副词、形容词、名词的词性标签,并使用 B-pos 的方式将位置信息添加到 POS 特征上。
- POS Score:通过对训练数据的分析,作者发现很多错误词语的 POS 标签不是最常出现的标签。例如,“损伤”在句子“抽烟明显损伤身体健康”中的词性标签是 VV,这不是“损伤”最常出现的标签。这是一个 S 错误,“损伤”应该被修改为“损害”。作者使用词语标签的离散概率作为特征,概率由 Gigawords 数据集计算。请注意,作者使用与 POS 特征相同的方式将位置指示器附加到此特征上。
- Adjacent Word Collocation:在训练数据中,作者发现相邻词语之间的搭配错误。基于此观察,作者使用 Gigawords 数据集为每个相邻词语对计算了 point-wise 互信息(PMI)分数。例如“<锻炼, 动力>”的 PMI 分数较低,而“<锻炼, 能力>”的 PMI 分数较高。同样,“<一部, 电影>”的 PMI 分数要高于“<一台, 电影>”。作者将离散的 PMI 分数嵌入的低维向量中,作为 LSTM-CRF 模型的输入特征之一。因为是在字级别处理任务,因此将位置指示器添加到了离散的 PMI 分数中。
计算 PMI 分数的公式如下所示:
$$PMI(w_1, w_2) = log(\frac{p(w_1, w_2)}{p(w_1) * p(w_2)}) \quad (1)$$
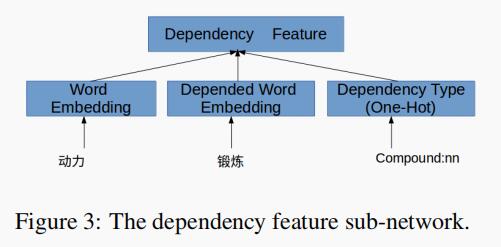
- Dependent Word Collocation:相邻词 PMI 分数表示相邻词之间的搭配。然而,搭配关系不限于相邻词。例如,“一个”在句子“他刚刚出版了一个新的小说”用于修饰词语“小说”。通过使用依赖分析器,我们可以获得每个词语的依赖性词语。在每个位置,作者通过子网络为搭配关系特征建模。子网络的输入是词嵌入、依赖词嵌入和依赖类型的连接(concate)。图 3 显示了子网络。
4.3 集成策略
由于随机初始化,随机 dropout 和随机训练顺序,因此每次训练结束时模型结果可能会有所不同。经过实验,作者发现,即使每个模型共享相同的预训练参数集,每个模型也会给出非常不同的预测结果。根据这种情况,作者设计了 3 种不同的集成方法来提高结果。
第一种集成方法只是简单地合并所有结果。作者发现单个模型的精度比召回率要高,使用该集成策略,召回率提高但精度大大降低。
因此,作者设计了第二种集成方法来平衡精度和召回率。
作者使用 LSTM-CRF 生成的分数对每个模型生成的错误进行排名,删除每个模型的最终排名 20%,然后合并其余结果。第二种集成方法可以在一定程度上提高精度,但是很难超过单个模型。
为了进一步提高精度,作用采用的第三种集成策略是投票法。
投票法实际上是一种强大的方法,因为只要模型数量足够大,投票法就可以大大提高精度,同时保持召回率不变。
在所有实验中,作者使用了 4 个不同的参数组,并为每个参数组训练了 2 个模型,因此总共使用了 8 个模型。出乎意料的是,作者发现这三种不同的集成方法分别在检测级别、识别级别和位置级别上获得了最佳的 F1 分数。
5. 实验
5.1 数据切分和实验设置
作者收集了 2015 年、2016 年和 2017 年的数据集,其中 2017 年的 20% 数据用于验证,其余数据用于训练。在实验中,作者发现添加正确的句子可以改善结果,因此将所有正确的句子都添加到训练集中。
作者使用 Gigawords 数据集对 bigram-char 嵌入和词嵌入进行了预训练,并在训练模型时进行了固定。对于其他参数,则随机初始化。
在三个级别上分别计算性能指标:检测级别、识别级别和位置级别。对于每个级别,包括误报率、准确性、精确率、召回率和 F1 得分。
5.2 实验结果
5.2.1 验证数据集结果
作者使用验证数据集为单个 LSTM-CRF 模型选择最佳超参数。在这些参数中,作者选择了 4 组参数,并为每个要集成的参数组训练了 2 个模型。4 组参数之间存在一定程度的差异,而每个参数组的模型性能也很好,表 2 显示了结果。
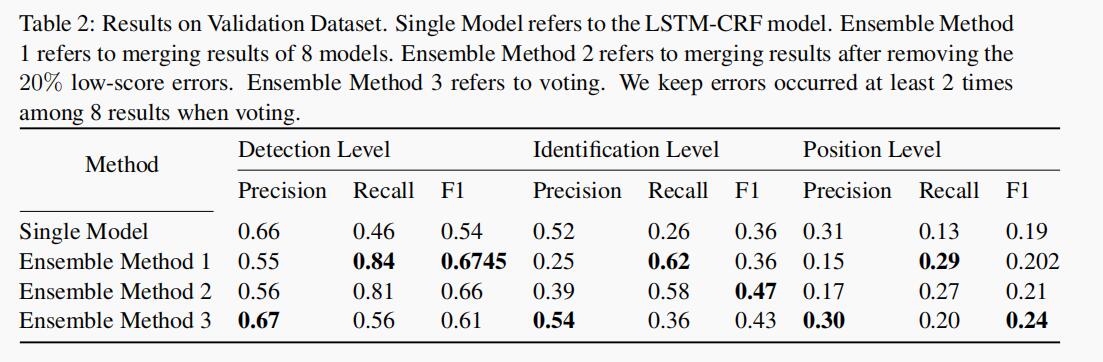
正如我们所看到的,集成策略 1(简单合并所有单个模型)在所有三个级别上的召回率最高,同时在检测级别上获得最佳的 F1 分数。
集成策略 2(消除低得分错误后合并)在所有三个级别上都具有相对较好的性能,尤其是在识别级别上获得最高的 F1 分数。
集成策略 3(投票法)在所有 3 个级别上都具有最佳精度,它在位置级别上获得最佳的 F1 分数。可以预期,从集成策略 1 到 3,精度正在提高,而召回率却在下降。此外,与单一模型相比,所有 3 种集成策略都非常有效,并且在所有 3 个级别上都对 F1 分数有很大的提高。
5.2.2 评估数据集的结果
在最终评估数据集上进行测试时,作者合并了训练数据集和验证数据集,并重新训练了模型。表 3 显示了 3 个提交的结果,每个提交对应于一个集成策略。
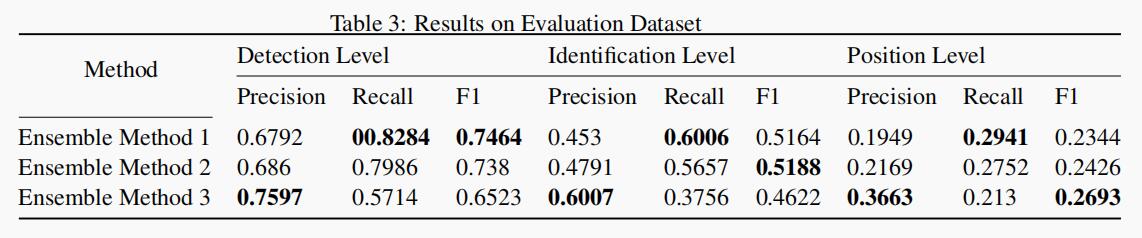
作者的系统在识别级别和位置级别均获得最佳的 F1 分数,并且在所有 3 个级别中均获得最佳的召回率。
6. 总结和未来工作
作者结合了一些手工特征,例如 POS、依赖特征和 PMI 分数等,并基于这些特征训练了 LSTM-CRF 模型。然后,为 3 个级别设计了不同的集成策略,结果表明该策略是有效的。
将来,作者希望借助更多训练数据,不仅能够识别错误,而且希望基于 seq2seq 等模型直接纠正错误。目前,在此任务中使用了许多手工特征,将来,将结合预训练的语言模型和其他相关的多任务模型,设计出一种更加自动化的神经体系结构,以获得端到端的语法错误识别系统,这将有助于识别和纠正语法错误。



