LLM - 推理相关资料整理
推理服务
通常情况下,LLM 推理服务目标是首 token 输出尽可能快、吞吐量尽可能高以及每个输出 token 的时间尽可能短。换句话说,希望模型服务能够尽可能快地尽可能多地为用户生成文本。
常见 LLM 推理服务性能评估指标
- 首 token 生成时间(Time To First Token,TTFT):用户输入 prompt 后多久开始看到模型输出。这一指标取决于推理服务处理 prompt 和生成第一个输出 token 所需的时间。在实时交互中,低时延获取响应非常重要,但在离线工作任务中则不太重要。通常,不仅对平均 TTFT 感兴趣,还包括其分布,如 P50、P90、P95 和 P99 等。
- 生成每个输出 token 所需时间(Time Per Output Token,TPOT):生成一个输出 token 所需的时间,这一指标与用户感知模型“速度”相对应。例如,TPOT 为 100ms/token,表示每秒生成 10 个 token。
- 端到端时延:模型为用户生成完整响应所需的总时间。整体响应时延可使用前两个指标计算得出:时延 = (TTFT) + (TPOT) * (要生成的 token 数量)。
- 吞吐量(Throughput):推理服务器每秒可为所有用户和请求处理的 token 数以及生成的输出 token 数的总和。
- 每分钟完成的请求数(Request Per Minutes):通常情况下,我们希望系统能够处理并发请求,例如处理来自多个用户的输入或者一个批量的推理任务。
- 单个请求的成本:API 提供商通常会权衡其他指标(如:时延)以换取成本。例如,可以通过在更多 GPU 上运行相同的模型或使用更高端的 GPU 来降低时延。
- 最大利用率下每百万 token 的成本:比较不同配置的成本(例如,在 1 个 A800 80G GPU、1 个 H 800 80G GPU 或 1 个 A100 40GB GPU 上提供 Llama2-7B 模型),估算给定输出的部署总成本。
- 预加载时间:只能通过对输入 prompt 的首 token 的生成时间来间接估算。一些研究发现,在 250 个输入 token 和 800 个输入 token 之间,输入 token 与 TTFT 之间似乎并不存在明显的关系,且由于其他原因,它被 TTFT 中的随机噪声掩盖。通常情况下,输入 token 对端到端时延的影响约为输出 token 的 1%。
对于实时交互的在线服务来说,目标是小 TTFT 和小 TPOT 以及高吞吐量。对于离线非实时服务来说,更重要的是服务的吞吐能力和资源的利用率(GPU 计算和显存的利用率)。
注意事项:吞吐量和 TPOT 之间存在权衡,如果我们同时处理多个用户的输入,相比按顺序处理单条输入,吞吐量会更高,但为每个用户服务的 TPOT 时间会更长。这是因为 GPU 的流式处理器数量有限,即使显存可以存放更多的请求,但正在被处理的请求数量仍然有限,更多的请求处于等待队列中。
如果对整体的推理延迟有要求,以下是一些评估模型的有用建议:
- 输出长度主导整体响应延迟:对于平均延迟,通常只需将预期或者最大输出 token 长度乘以模型每个输出 token 的整体平均时间。
- 输入长度对性能影响不大,但对硬件要求很重要:增加输入 token 所增加的延迟比增加输出 token 所增加的延迟要少,这是因为预填充阶段可以并行处理,而解码阶段只能从左到右逐个 token 生成。
- 总体延迟与模型大小呈亚线性关系:在相同硬件条件下,模型越大速度越慢,但速度比率并不一定与参数量比率相匹配。例如,Llama2-70B 的延迟是 Llama2-13B 的 2 倍。
影响推理的因素
内存带宽是关键
LLM 中的计算主要由矩阵乘法运算主导。在大多数硬件上,这些小维度运算通常受内存带宽限制。当以自回归方式生成 token 时,激活矩阵的维度 [batch_size, seq_len, hidden_size],在 batch size 较小的情况下很小。因此,速度取决于将激活和模型参数从 GPU 内存加载到本地缓存或寄存器的速度,而不是加载数据后的计算速度。推理硬件内存带宽的利用率比其峰值算力更能预测 token 生成的速度。
就服务成本而言,推理硬件的利用率非常重要。GPU 价格昂贵,因此需要做尽可能多的工作。通过共享推理服务,合并来自多用户的工作负载、填补单个计算流中的气泡和 batching 多个请求提高吞吐来降低成本。
模型带宽利用率(MBU)
在较小的 batch size 前提下,LLM 推理受限于如何将模型参数和中间激活从设备内存加载到计算单元的速度。内存带宽决定了数据移动的速度。为了衡量底层硬件的利用率,引入了一个新指标,称为模型带宽利用率(MBU),MBU = 实际的内存带宽 / 峰值内存带宽,其中实际的内存带宽为 (模型参数总大小 + kv 缓存大小) / TPOT。
例如,如果以 float16 精度运行 7B 参数的模型,其 TPOT 等于 14ms,相当于在 14ms 内要移动 14GB,每秒使用 1TB 的带宽。如果机器的峰值带宽为 2TB/s,那么对应的 MBU 为 50%。为简单起见,该示例忽略了 kv 缓存大小,因为对于较小的 batch size 和较短的序列长度来说,kv cache 较小。
MBU 值接近 100%,意味着推理系统有效利用了可用的内存带宽。MBU 还有助于以标准化方式比较不同的推理系统(硬件 + 软件)。MBU 是对模型浮点计算利用率(MFU)指标的补充,其中 MFU 在 compute-bound 的环境中非常重要。
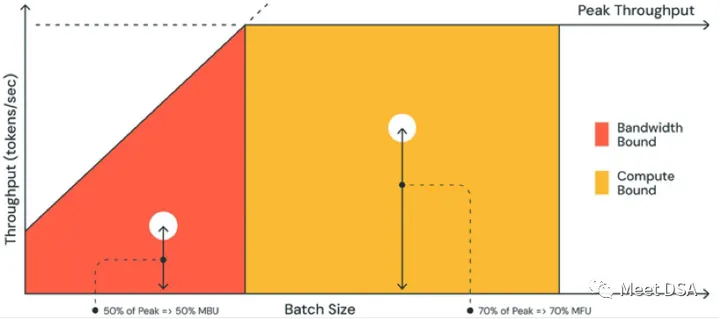
上图 为 MBU 示例图(来源于参考资料 1),橙色区域的斜线表示在内存带宽 100% 完全饱和的情况下可能达到的最大吞吐量。然而,在实际情况中,对于小 batch size(白点),观察到的性能会低于最大值——低多少是 MBU 的衡量标准。对于大 batch size(黄色区域),系统是 compute-bound,所实现的吞吐量占峰值吞吐量的比例可以通过 MFU 来衡量。
推理框架
vLLM:高吞吐量、高内存效率的 LLMs 推理和服务引擎,采用 PagedAttention 来高效管理 kv cache。
- 官方网址:https://vllm.ai/
- 官方文档:https://docs.vllm.ai/en/latest/index.html
- GitHub 地址:https://github.com/vllm-project/vllm
TensorRT:NVIDIA® TensorRT™ 是在 NVIDIA GPU 上进行高性能深度学习推理的 SDK。该资源库包含 TensorRT 的开源组件。
TGI(Text-Generation-Inference):文本生成推理(TGI)是一个用于部署和服务大型语言模型(LLM)的工具包。TGI 可为最流行的开源 LLM(包括 Llama、Falcon、StarCoder、BLOOM、GPT-NeoX 和 T5)实现高性能文本生成。
lightllm:LightLLM 是一个基于 Python 的 LLM(大型语言模型)推理和服务框架,以其轻量级设计、易扩展性和高速性能而著称。
- GitHub 地址:https://github.com/ModelTC/lightllm
lmdeploy:LMDeploy 是用于压缩、部署和服务 LLM 的工具包,由 MMRazor 和 MMDeploy 团队开发。其中的一个优点是 LMDeploy 通过引入持久批处理(又称连续批处理)、阻塞式 KV 缓存、动态拆分与融合、张量并行、高性能 CUDA 内核等关键功能,将请求吞吐量提高到 vLLM 的 1.8 倍。
- GitHub 地址:https://github.com/InternLM/lmdeploy
SwiftInfer:流式 LLM 是一种支持无限输入长度的 LLM 推断技术。它利用 Attention Sink 来防止注意力窗口移动时模型崩溃。最初的工作是在 PyTorch 中实现的,作者提供了 SwiftInfer(一种 TensorRT 实现),以使 StreamingLLM 更具生产水平。该实现基于最近发布的 TensorRT-LLM 项目。
- GitHub 地址:https://github.com/hpcaitech/SwiftInfer
参考资料
- 1:前沿论文 | LLM推理性能优化最佳实践 - 奕行智能的文章 - 知乎:https://zhuanlan.zhihu.com/p/665097408