PyramidKV
北大、威斯康辛-麦迪逊、微软等联合团队提出了全新的缓存分配方案,只用 2.5% 的 kv cache 就能保持大模型 90% 的性能。该方法名为 PyramidKV,在 kv cache 压缩的过程中融入了金字塔型的信息汇聚方式。在内存受限的情况下,PyramidKV 表现非常出色,既保留了长上下文理解能力,又显著减少了内存使用。
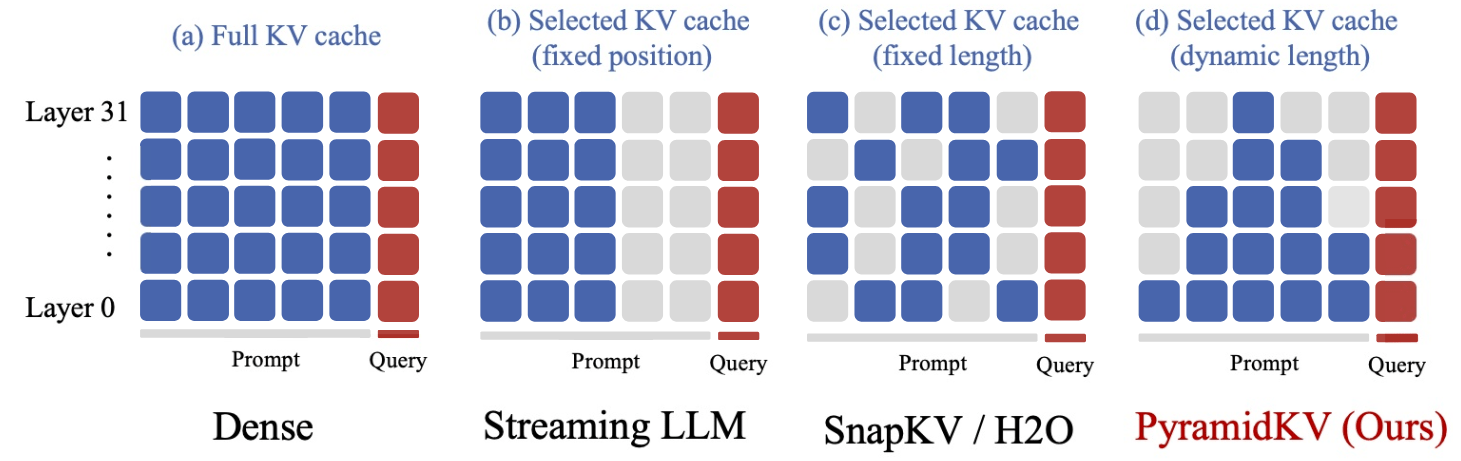
传统对 kv cache 压缩的方法有一个共同特点,对每个 Transformer 层的 kv cache“一视同仁”地用相同的压缩设置,压缩到同样的长度。
PyramidKV 团队发现,对 KV cache 进行极致压缩情况下(从 32k 长度压缩到 64,即保留 0.2%的 kv cache)上述方法的表现会面临严重的性能下降。于是作者提出疑问:对每个 Transformer 层将 kv cache 压缩到同样大小是否为最优方案?
研究团队对大模型进行 RAG 的机制进行深入分析,研究 Llama 模型进行多文档问答的逐层注意力图,发现注意力层中的金字塔型信息汇聚模式(Pyramidal Information Funneling)的存在:
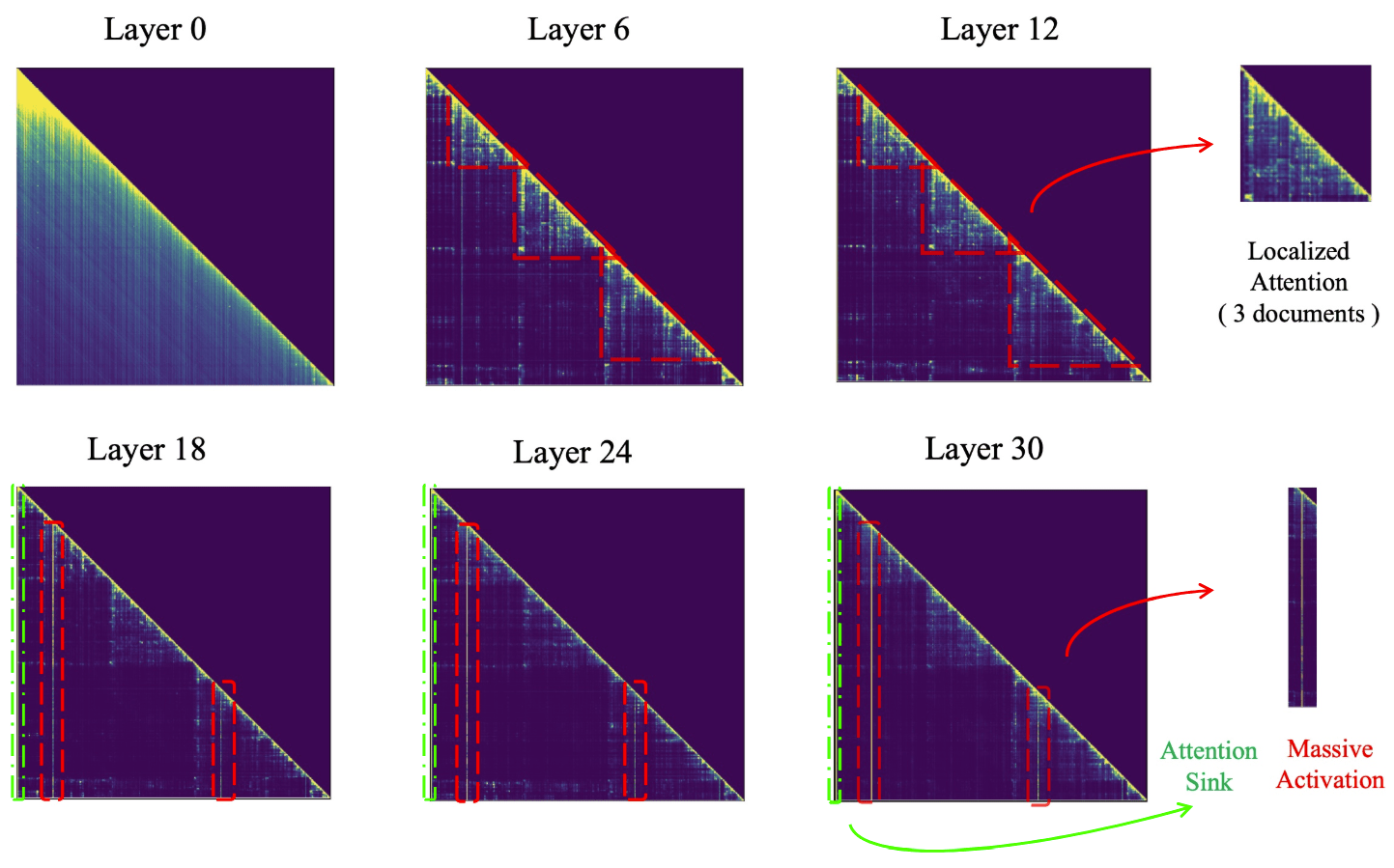
- 在模型的低层(例如第 0 层)中,注意力分数呈现近似均匀分布,这表明模型在较低层时从所有可用内容中全局聚合信息,而不会优先关注特定的 span。
- 在模型的中间层(6 - 18)时,逐渐转变为聚焦在 span 内部的注意力模式(Localized Attention)。在该阶段,注意力主要集中在同一文档内的 token 上,表明模型在单个 span 内进行了信息聚合。
- 在模型的上层(24 - 30),继续加强中间层的模式,观察到了“Attention Sink”和“Massive Activation”现象。在这些层中,注意力机制极大地集中在少数几个关键的 token 上,因此只需要保留这些关键 token 就能让输出保持一致并且减少显存占用。
根据以上发现,研究团队认为之前的工作对所有 Transformer 层统一处理是低效的,因此不同 Transformer 层的注意力稀疏程度并不相同。在底层能观察到特别稠密的注意力,而在较高层则可以观察到非常稀疏的注意力。因此,在不同层之间使用固定的 kv cache 大小可能会导致性能不佳。这些方法可能在较高层的稀疏注意力中保留许多不重要的 tokens,而忽略较低层密集注意力中的许多重要的 tokens。
具体做法
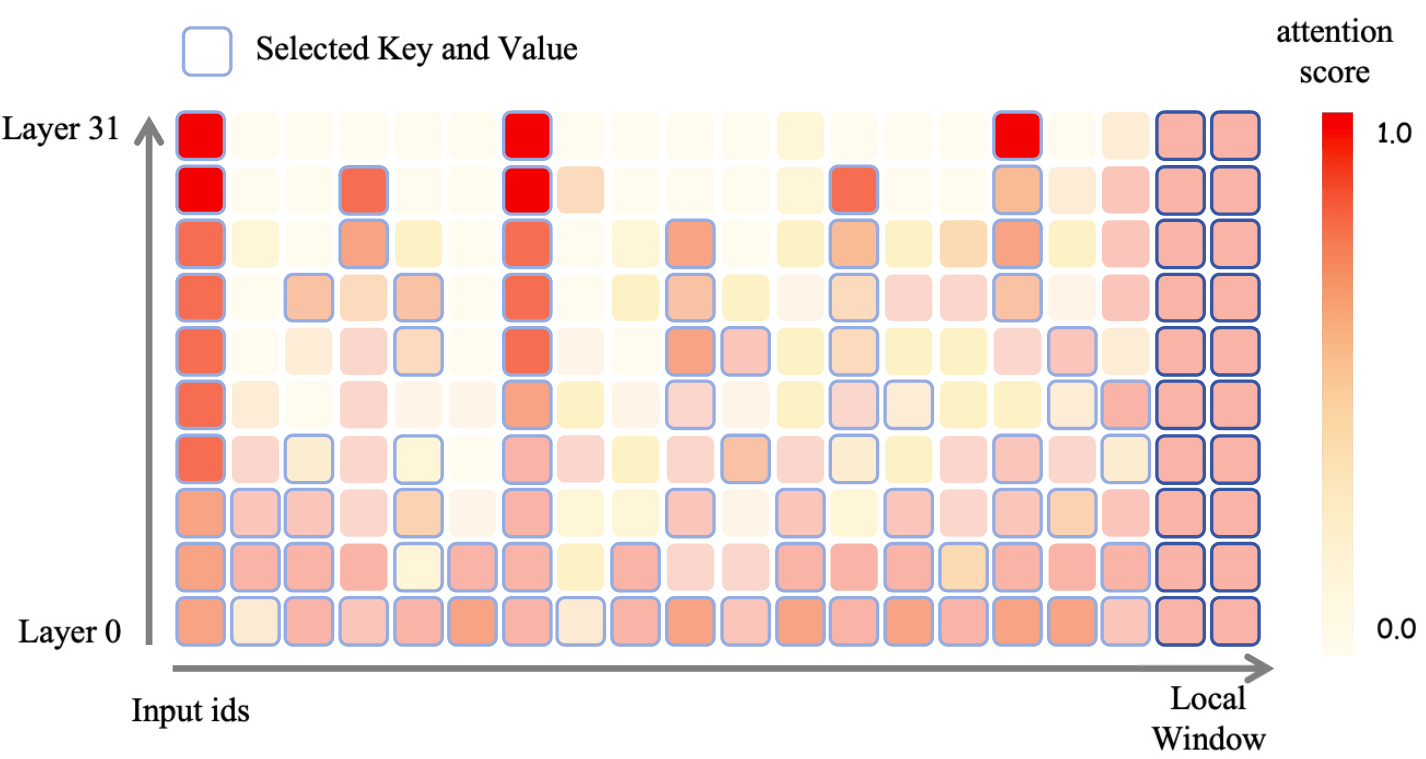
研究团队选择了通过基于注意力模式动态分配缓存预算来提高压缩效率:在信息更加分散的较低层分配更多的 kv cache,而在信息集中于少数关键 tokens 的较高层减少 kv cache。一旦为每一层确定 kv cache 预算后,PyramidKV 在每一个 Transformer 层中选择根据注意力选择要缓存的 kv。最后部分 token 的 kv cache,即 instruction token 会在所有 Transformer 层中保留(根据 UIUC、普林斯顿等提出的 SnapKV 方法,剩余 kv cache 的选择由这些 instruciton token 中获得的对其他 token 注意力分数来指导)。
实验结果
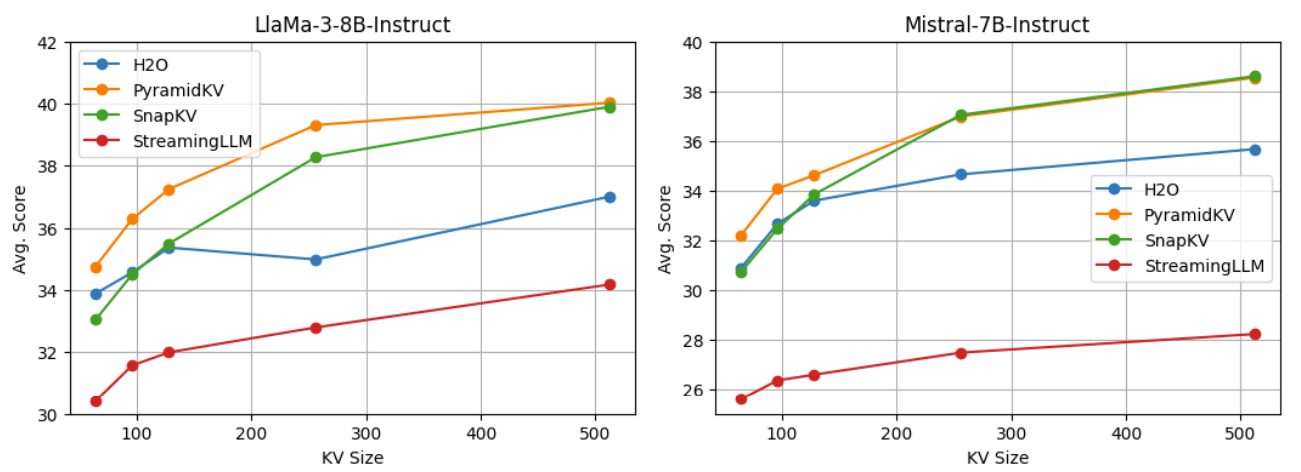
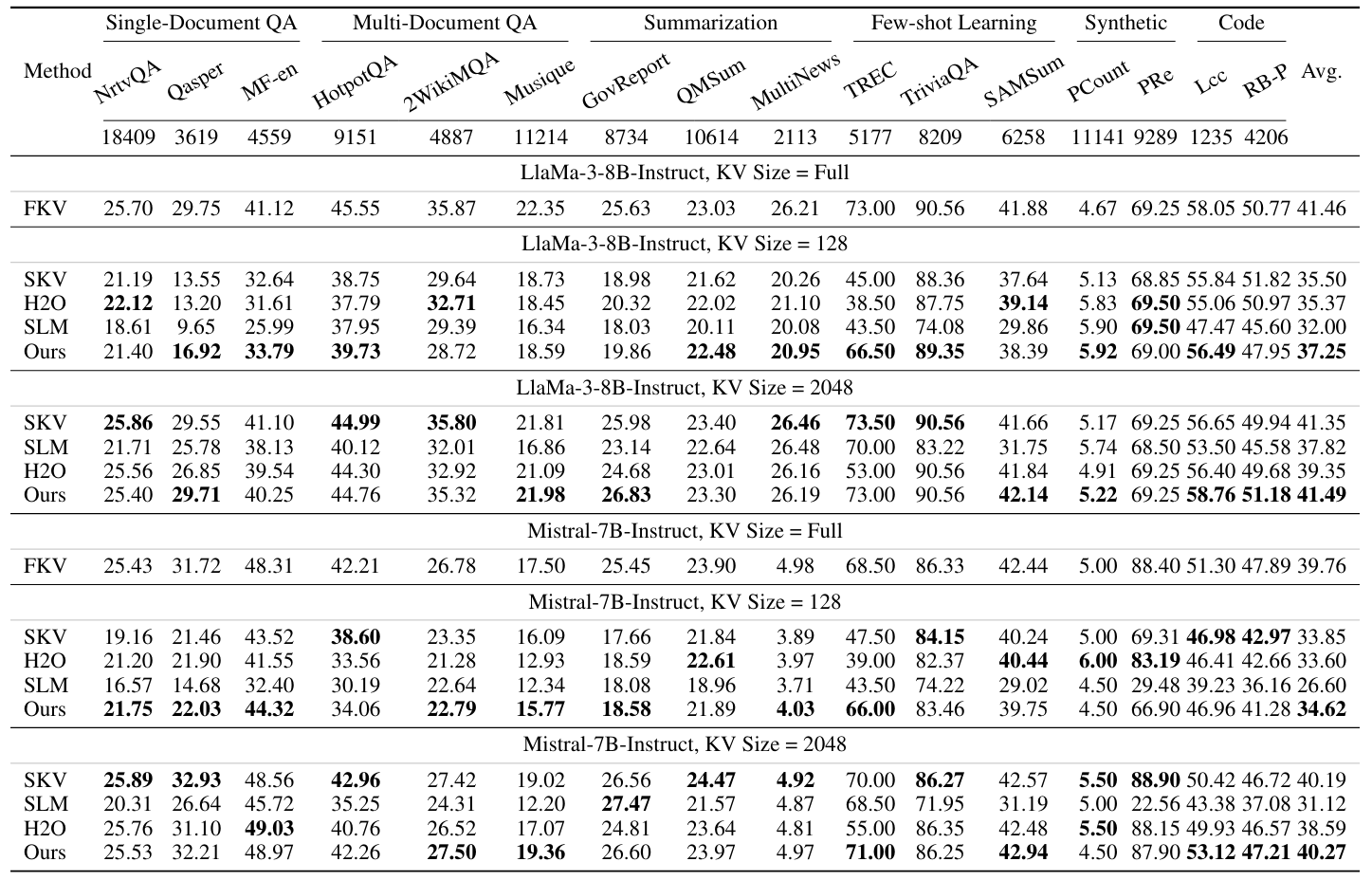
研究团队使用最新的 Llama-3-8B-Instruct 和 Mistral-7B-Instruct 来对 PyramidKV 和其他方法进行对比。测试示例以生成格式进行评估,所有任务的答案均通过贪婪解码生成,并使用 LongBench 来评估 PyramidKV 在处理长上下文输入任务中的表现。
在 64、96、128、256 和 512 个 kv cache 大小的设定下,PyramidKV 在 LongBench 中均取得了优于 baseline 的效果。
在此基础上,作者还研究了两种不同的操作场景——节省内存场景(Memory-Efficient Scenario)和保持性能场景(Performance-Preserving Scenario),分别用于在内存和模型性能之间进行权衡。
值的注意的是,PyramidKV 在 size = 128 的设置下,在 TREC(上下文学习问答挑战)任务中表现出显著优越的性能,相较于 baseline,提高了 20. 的 ACC 结果。
参考资料
- 2.5%KV缓存保持大模型90%性能,大模型金字塔式信息汇聚模式探秘|开源 - 量子位的文章 - 知乎
https://zhuanlan.zhihu.com/p/703313505



