RAG 查询检索模块 - 前处理 - 查询变换
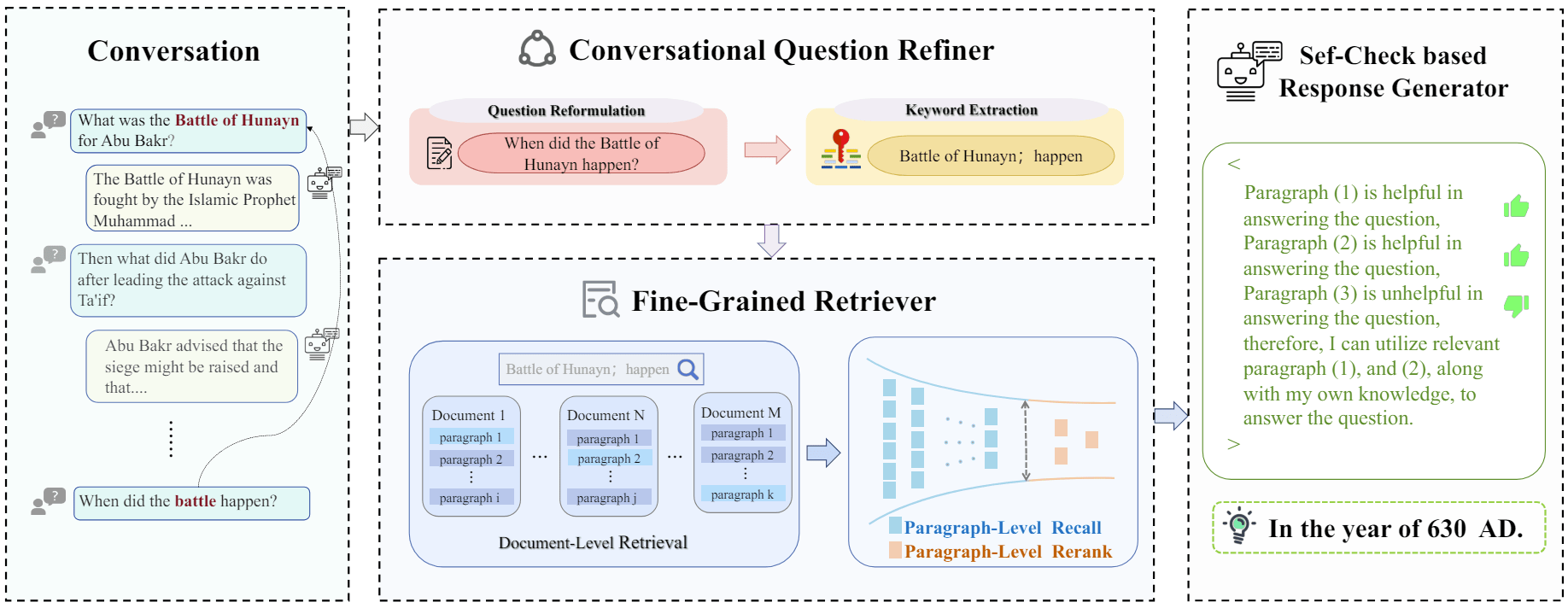
查询文本的表达方式直接影响着检索结果,微小的文本改动都可能会得到天差地别的结果。直接用原始的查询文本进行检索在很多时候可能是简单有效的,但有时候可能需要对查询文本进行一些变换,以得到更好的检索结果,从而更可能在后续生成更好的回复结果。
方法:同义改写
将原始查询改写成相同语义下不同的表达方式,例如将原始查询“What are the approaches to Task Decomposition?”改写成下面几种同义表达:
1 | How can Task Decomposition be approached? |
对每种查询表达,分别检索出一组相关的文档,然后对所有检索结果进行去重合并,从而得到一个更大的候选相关文档集合。
优点:能够克服单一查询的局限,获得更丰富的检索结果集合。
缺点:如果数据库内存在冗余和噪声数据,也更容易检索出冗余和噪声的文档。
方法:查询分解
有相关的研究表明:
- Measuring and Narrowing the Compositionality Gap in Language Models
- ReAct: Synergizing Reasoning and Acting in Language Models
LLM 在回答复杂问题时,如果将复杂问题分解成相对简单的子问题,回复表现会更好。这里可以分类为单步分解和多步分解。
单步分解
将一个复杂查询转化为多个简单的子查询,融合每个子查询的答案作为原始复杂查询的回复。
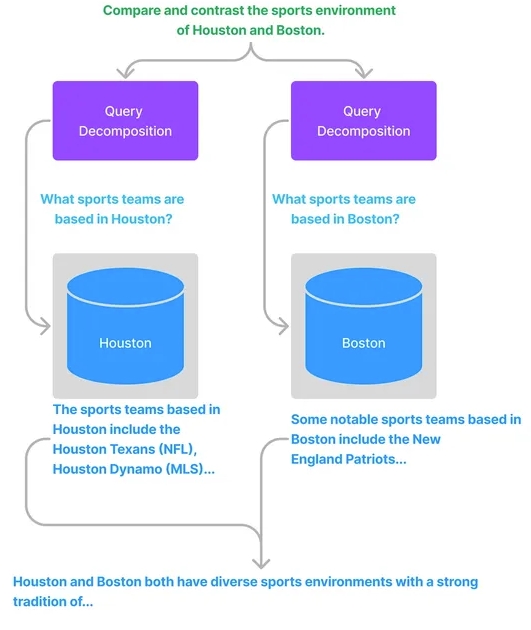
多步分解
给定初始的复杂查询,会一步步地转换成多个子查询,结合前一步的回复结果生成下一步的查询问题,直到问不出更多问题为止。最后结合每一步的回复生成最终的结果。

方法:查询扩展
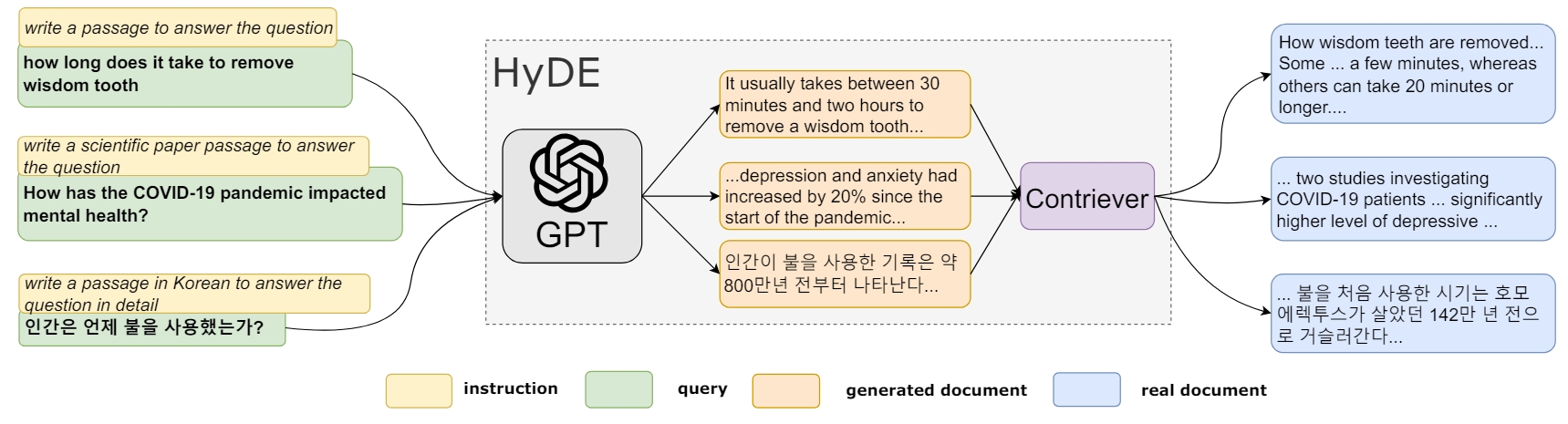
HyDE
Hypothetical Document Embeddings(HyDE),给定初始查询,首先利用 LLM 生成一个假设的文档或者回复,然后以这个假设的文档或者回复作为新的查询进行检索,而不是直接使用初始查询。
论文地址:Precise Zero-Shot Dense Retrieval without Relevance Labels
思想:希望检索看起来像答案的文档,感兴趣的是它的结构和表述。所以,可以将假设的答案视为帮助识别嵌入空间中相关邻域的模板。
示例:prompt。
1 | You are a helpful expert financial research assistant. |
缺点:这种转换在没有上下文的情况下可能会生成一个误导性的假设文档或者回复,从而可能得到一个和原始查询不相关的错误回复。
MultiQueryRetriever
指示 LLM 生成与原始查询相关的 N 个问题,然后将它们(+原始查询)全部发送到检索系统,从向量数据库中检索出更多的相关文档。再根据后处理(去重过滤、重排序)等手段,删除冗余、关联度不大的文档,保留最相关的文档。
与方法:同义改写类似。
思想:扩展可能不完整或不明确的初始查询,合并成可能相关和互补的最终结果。
示例:生成相关问题的 prompt。
1 | You are a helpful expert financial research assistant. |
缺点:会得到更多的文档,而这些文档或多或少会存在一些冗余和无关的信息,导致分散 LLM 的注意力,使其无法生成有用的答案。
实现方式:LangChain
https://python.langchain.com/docs/modules/data_connection/retrievers/MultiQueryRetriever
Step Back Prompting
论文地址:Take A Step Back: Evoking Reasoning Via Abstraction In Large Language Models
Google deep mind 开发的一种方法,使用 LLM 来创建用户查询的抽象(原始查询和查询抽象的关系类似面向对象中的类和抽象类的关系)。该方法将从用户查询中退后一步,以便更好地从问题中获得概述。LLM 将根据用户查询生成更通用的问题。
示例:原始查询和后退查询。
1 | { |
这两个查询将用于提取相关文档,将这些文档组合在一起作为一个上下文,提供给 LLM 生成最终的答案。