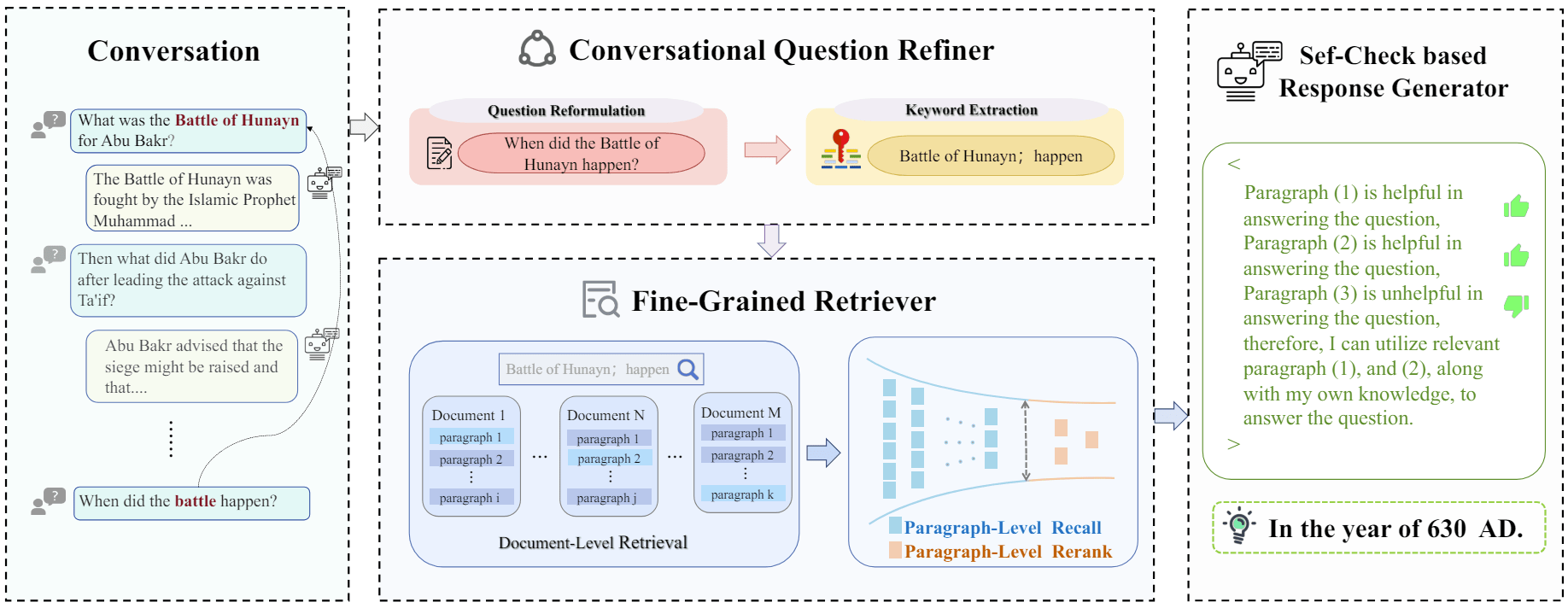
RAG 查询检索模块 - 后处理 - 合并挑选
在 RAG 中,“Lost in the Middle”问题相当具有挑战性。斯坦福大学和加州大学伯克利分校等大学的研究强调了这一问题,这与人们经常记住购物清单上的第一个和最后一个项目,但忘记中间的项目类似。语言模型与人一样很擅长识别他们正在分析的文本的开头或结尾的信息,但他们往往会忽略中心的关键细节。
LLM 关注开头和结尾是否和现实世界的文章相关联?现实世界的文章的重心大都也放在开头和结尾,那么在预训练期间,这些数据让模型有这种关注的趋势?
为了解决这个问题,一个常用的流程是:
- 避免使用单一知识库,对不同类型的文档只使用一个知识库可能会混淆检索模型。他们可能很难根据主题或上下文找到正确的信息。
- 使用多个向量存储,为不同类型的文档创建单独的数据存储区域(称为向量存储),这有助于更有效地组织信息。
- 使用一个称为 Merge Retrieve 的工具合并来自这些不同向量数据库的数据,这有助于汇集来自不同来源的相关信息。
- 使用长上下文重新排序,这确保了模型对文本中间的数据给予同等的关注,而不仅仅是在开头或结尾。
通过该流程,可以确保数据的所有部分,包括中间部分都得到了适当的检索,有助于改进 RAG 系统的性能,使它们更有效地处理和解释大量不同的信息源。
方法:常用筛选策略
常用的筛选和排序策略包括:
- 基于相似度分数进行过滤和排序。
- 基于关键词进行过滤,比如限定包含或者不包含某些关键词。
- 让 LLM 基于返回的相关文档及其相关性得分来重新排序。
- 基于时间进行过滤和排序,比如只筛选最新的相关文档。
- 基于时间对相似度进行加权,然后进行排序和筛选。
方法:LOTR(合并检索器)
LOTR:Lord of the retrievers,也称为 merger retriever,它将检索器列表作为输入,并将它们的 get_relevance_documents() 方法的结果合并到单个列表中。合并的结果将是与查询相关的文档列表,这些文档是被不同的检索器排序过的。
MergerRetriever 类可以通过几种方式用于提高文档检索的准确性:它结合多个检索器的结果,这有助于减少结果偏差的风险。并且可以对不同检索器的结果进行排序,这有助于确保首先返回最相关的文档。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 clvsit 个人博客!
相关推荐


最新文章


