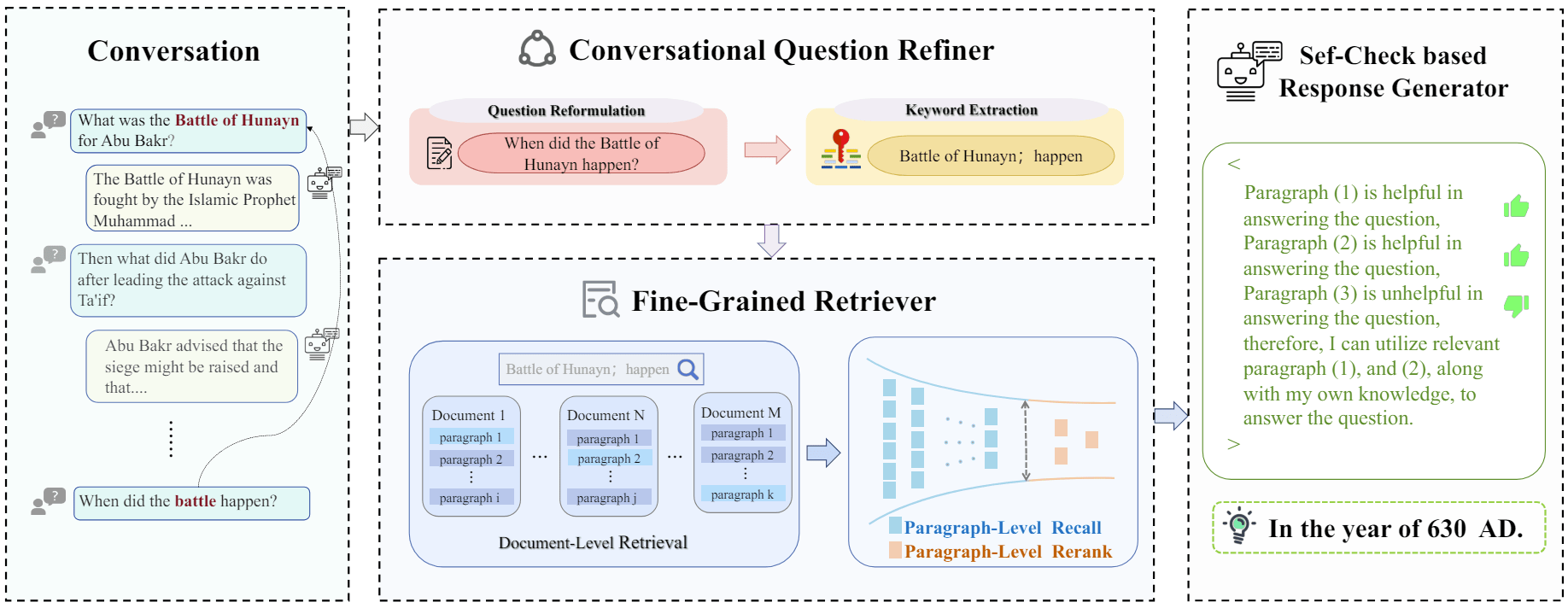
RAG 查询检索模块 - 后处理 - 清洗过滤
方法:专家系统
根据关键字词、元数据、规则等对检索得到的内容进行清洗或过滤。
方法:过滤不相关的检索信息
分享一篇从 answer 的角度来优化排序检索内容的 paper。
大体思路:
- 当检索到相关文本集合时,可以训练一个判断模型 $M_{ctx}$,用它来选择能支撑 query 的内容,即 $M_{ctx}(t|q, P)$,其中 q 为 query,P 为召回的相关内容集合,t 为筛选出的相关片段集合。
- 有了判断模型 $M_{ctx}$,利用它选择出来的相关片段集合 t 作为最终的检索内容,来支撑 $M_{gen}$ 生成,即 $M_{gen}(o|q, t)$,其中 o 为生成内容。

在上述流程中,其核心在于判断模型 $M_{ctx}$ 如何训练,其训练的监督数据如何构建。针对该问题,论文提出三种方法来构建判断模型的训练数据,即对应图中的 StrInc、CXMI、Lexical。
- StrInc:String Inclusion,当 o(query 对应的 answer)完整出现在一个片段 t 中,就把这个片段召回,只要第一个,这样就构造一条形如 <(q, P), t> 格式的训练数据。该方法比较简单直接,缺点是可能找不到满足条件 t 或者找到的 t 仍然是噪声内容。
- CXMI:Conditional Cross-Mutual Information,条件互信息度量指标。其含义是对比在有没有检索内容 t 的支撑下,$M_{gen}$ 生成 o 的概率;可这样理解:如果为 1,表示 t 可有可无;如果大于 1,表示 t 利于模型生成;如果小于 1,表示 t 带来了噪声,不利于模型生成。所以,利用该度量指标,可以选择 $f_{cxmi}$ 分数最大对应的片段作为最终的 t,这样也可以构建出训练数据集。优点是可以直接用生成模型来度量,判断哪个片段有效;缺点是要用大模型遍历所有的片段,效率比较低。
- Lexical:Lexical Overlap,将 e = q + o 放在一起进行分词,然后再将所有召回的片段也进行分词,最后看那个片段与 e 的词重叠最多,就将其作为训练数据的 t。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 clvsit 个人博客!
相关推荐


最新文章


