RAG 查询检索模块 - 后处理 - 重排序
重排序是指对检索得到的文档集合根据特定指标进行重新排序的过程,明确最“重要”和最“不重要”的文档,用于后续的过滤和挑选环节。

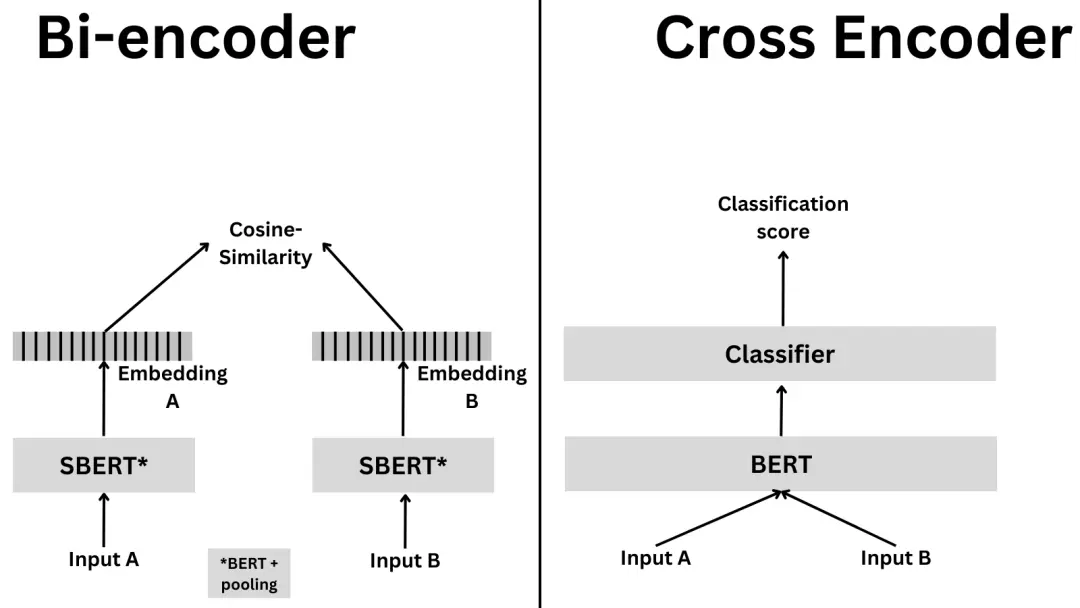
由于 cross-encoder 需要两两进行比对,当数据量较多时,编码的次数会急剧上升,编码更慢且需要更多的内容。通常,会先用 bi-encoder 进行粗筛,挑选出一部分匹配的候选项;然后,再用 cross-encoder 去重新排序候选项,得到最终的带有高精度的结果。
cross-encoder
交叉编码器 cross-encoder 是一种深度神经网络,它将两个输入序列作为单个输入,同时进行编码,从而捕获了句子的表征和相关关系。与 bi-encoder 生成的嵌入(独立的)不同,cross-encoder 生成的嵌入是互相依赖的,因此允许直接比较和对比输入,以更综合和细致的方式理解它们的关系。
cross-encoder 被训练来优化分类或回归损失,而不是相似性损失。
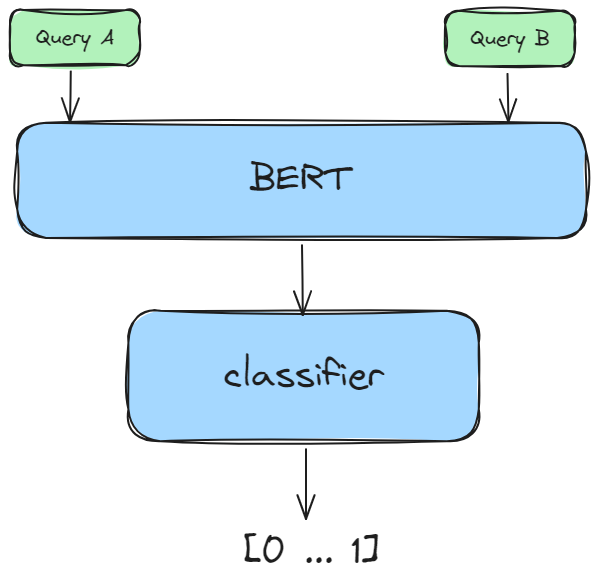
实现方式
借助 sentence-transformers 实现 cross-encoder 的执行流程。
- 首先,安装 sentence-transformers。
1 | pip install -U sentence-transformers |
- 加载 cross-encoder 模型,这里选择 ms-macro-MiniLM-L-6-v2(joyland 使用 bge-reranker-large),对于排序的性能度量可以参考 SBERT 选择更好的模型。
1 | from sentence_transformers import CrossEncoder |
- 对每对(查询,检索得到的文档)进行打分。
1 | pairs = [[query, doc] for doc in retrieved_documents] |
相关研究
RAG 重排哪家强?Cross-Encoder VS LLM Reranker
相关资料
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 clvsit 个人博客!
相关推荐


最新文章


