解码策略:Speculative Sampling
- GitHub 仓库:https://github.com/feifeibear/LLMSpeculativeSampling
- 论文地址:https://arxiv.org/abs/2211.17192
投机采样在解码过程中使用两个模型:目标模型和近似模型。近似模型是一个较小的模型,而目标模型是一个较大的模型。近似模型生成 token 猜测,目标模型纠正这些猜测。通过这种方法,可以在近似模型的输出上并行运行目标模型进行解码,从而比单独使用目标模型解码效率更高。
投机采样由 Google 和 Deepmind 于 2022 年各自提出。因此,上述 GitHub 仓库实现了两个略有不同的投机采样版本:Google 和 Deepmind 版本。
前置知识
对于 LLM 如 GPT 系列的这一类 Decoder-only Transformer 架构,“推理”特指模型生成文本的过程,分为预填充和解码两个阶段。
- 预填充(pre-filling):并行处理输入 prompt 中的词元(token)。
- 解码(decoding):以自回归的方式逐个生成词元(token),每个生成的词元会被添加到输入中,重新送入模型来生成下一个词元。当生成特殊的停止词元或者满足用户自定义的终止条件时,生成过程就会停止。
投机采样的思想:用近似模块相对目标模型更快速地执行解码阶段,并将生成的 tokens 交给目标模型来“验证”,此时目标模型对送入的 prompt 执行预填充阶段,该阶段可以并行执行。通过这种小模型生成、大模型校验的方式来加快推理速度。
采样过程
- 用近似模型$M_q$做自回归采样连续生成 n 个 tokens。
- 把生成的 n 个 tokens 和前缀 prompt 拼接到一起送进目标模型$M_p$执行一次 forward。
- 使用目标模型$M_p$和近似模型$M_q$的 logits 结果做比对:
- 如果对近似模型$M_q$的生成 tokens 都满意,则目标模型$M_p$直接生成下一个 token。
- 如果发现某个 token 小模型生成的不好,则从该 token 之前重新拼接 prompt,来生成下一个 token。
- 不断重复上述步骤,直到解码结束。

步骤 2 中,将 n 个 tokens 和前缀拼接到一块作为目标模型的输入,在预填充阶段并行计算每个 token 的 logits,相比解码阶段要快数倍。通过这种方式,可以快速让目标模型来校验近似模型的生成结果。
步骤 3 中,无论如何都会让目标模型$M_p$生成一个新的 token,这样即使在最坏情况下,目标模型$M_p$也仅仅是退化为串行执行(解码阶段),运行次数也不会超过常规解码的次数。
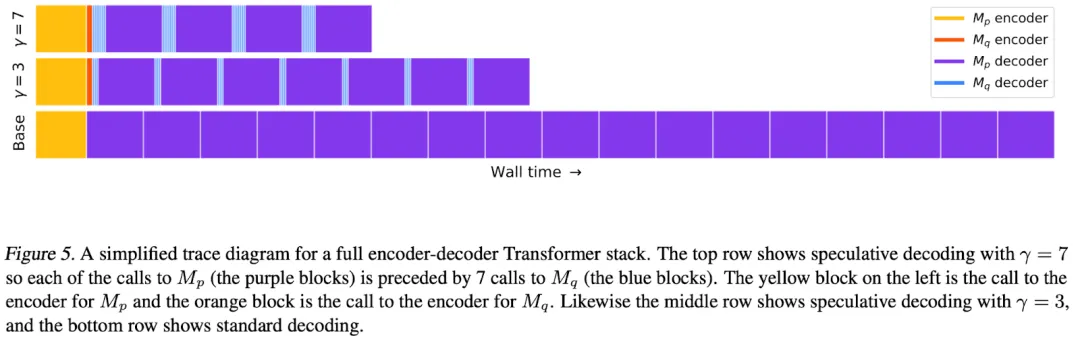
如下图 5 所示,作者提供了一个简单的示例,包含不同$\gamma$(验证的 token 数目),其中紫色为执行目标模型$M_p$的 decoder;蓝色为执行近似模型$M_q$的 decoder;黄色和橙色为调用 encoder。
问题:步骤 3 中,如何评价一个 token 生成的效果?
p 和 q 表示近似模型和目标模型的采样概率,也就是 logits 归一化后的概率分布。如果 q(x) > p(x),则以 1 - p(x) / q(x) 为概率拒绝这个 token 的生成,从一个新的概率分布 p’(x) = norm(max(0, p(x) - q(x))) 中重新采样一个 token。
加速效果
投机采样相比自回归采样之所以有加速效果,因为它减少了目标模型串行调用的次数,将置信度较高且容易生成的内容交给小的近似模型来完成,并利用预填充阶段的并行处理方式对近似模型的生成结果进行校验。因此,当 n 越大,p 和 q 的生成分布月接近,加速的效果越明显,因为目标模型的调用次数越少。
$$
E(#generated \ tokens) = \frac{1 - \alpha^{1 + n}}{1 - \alpha}
$$
$$
E(\alpha) = E(min(p, q))
$$
这里的$\alpha$是反应模型 p 和 q 性质的量。比如使用 argmax(贪婪解码)作为采样策略,LAMDA(137B)和 LAMDA(100M)的$\alpha$是 0.61。
更多评测可参阅 HuggingFace 官方的测试结果:https://huggingface.co/blog/assisted-generation。
参考资料
- 大模型推理妙招—投机采样(Speculative Decoding) - 方佳瑞的文章 - 知乎:https://zhuanlan.zhihu.com/p/651359908
- Assisted Generation:a new direction toward low-latency text generation:https://huggingface.co/blog/assisted-generation
- 万字综述 10+ 种 LLM 投机采样推理加速方案:https://mp.weixin.qq.com/s/PyAKiFzbQNq6w7HmaTnSEw



